 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context Engineering Framework for Improving Enterprise AI Agents based on Digital-Twin MDP
Mar 23, 2026Despite rapid progress in AI agents for enterprise automation and decision-making, their real-world deployment and further performance gains remain constrained by limited data quality and quantity, complex real-world reasoning demands, difficulties with self-play, and the lack of reliable feedback signals. To address these challenges, we propose a lightweight, model-agnostic framework for improving LLM-based enterprise agents via offline reinforcement learning (RL). The proposed Context Engineering via DT-MDP (DT-MDP-CE) framework comprises three key components: (1) A Digital-Twin Markov Decision Process (DT-MDP), which abstracts the agent's reasoning behavior as a finite MDP; (2) A robust contrastive inverse RL, which, armed with the DT-MDP, to efficiently estimate a well-founded reward function and induces policies from mixed-quality offline trajectories; and (3) RL-guided context engineering, which uses the policy obtained from the integrated process of (1) and (2), to improve the agent's decision-making behavior. As a case study, we apply the framework to a representative task in the enterprise-oriented domain of IT automation. Extensive experimental results demonstrate consistent and significant improvements over baseline agents across a wide range of evaluation settings, suggesting that the framework can generalize to other agents sharing similar characteristics in enterprise environments.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Learning Granger Causality from Instance-wise Self-attentive Hawkes Processes
Feb 06, 2024We address the problem of learning Granger causality from asynchronous, interdependent, multi-type event sequences. In particular, we are interested in discovering instance-level causal structures in an unsupervised manner. Instance-level causality identifies causal relationships among individual events, providing more fine-grained information for decision-making. Existing work in the literature either requires strong assumptions, such as linearity in the intensity function, or heuristically defined model parameters that do not necessarily meet the requirements of Granger causality. We propose Instance-wise Self-Attentive Hawkes Processes (ISAHP), a novel deep learning framework that can directly infer the Granger causality at the event instance level. ISAHP is the first neural point process model that meets the requirements of Granger causality. It leverages the self-attention mechanism of the transformer to align with the principles of Granger causality. We empirically demonstrate that ISAHP is capable of discovering complex instance-level causal structures that cannot be handled by classical models. We also show that ISAHP achieves state-of-the-art performance in proxy tasks involving type-level causal discovery and instance-level event type prediction.
Generative Perturbation Analysis for Probabilistic Black-Box Anomaly Attribution
Aug 09, 2023We address the task of probabilistic anomaly attribution in the black-box regression setting, where the goal is to compute the probability distribution of the attribution score of each input variable, given an observed anomaly. The training dataset is assumed to be unavailable. This task differs from the standard XAI (explainable AI) scenario, since we wish to explain the anomalous deviation from a black-box prediction rather than the black-box model itself. We begin by showing that mainstream model-agnostic explanation methods, such as the Shapley values, are not suitable for this task because of their ``deviation-agnostic property.'' We then propose a novel framework for probabilistic anomaly attribution that allows us to not only compute attribution scores as the predictive mean but also quantify the uncertainty of those scores. This is done by considering a generative process for perturbations that counter-factually bring the observed anomalous observation back to normalcy. We introduce a variational Bayes algorithm for deriving the distributions of per variable attribution scores. To the best of our knowledge, this is the first probabilistic anomaly attribution framework that is free from being deviation-agnostic.
Black-Box Anomaly Attribution
May 29, 2023When the prediction of a black-box machine learning model deviates from the true observation, what can be said about the reason behind that deviation? This is a fundamental and ubiquitous question that the end user in a business or industrial AI application often asks. The deviation may be due to a sub-optimal black-box model, or it may be simply because the sample in question is an outlier. In either case, one would ideally wish to obtain some form of attribution score -- a value indicative of the extent to which an input variable is responsible for the anomaly. In the present paper we address this task of ``anomaly attribution,'' particularly in the setting in which the model is black-box and the training data are not available. Specifically, we propose a novel likelihood-based attribution framework we call the ``likelihood compensation (LC),'' in which the responsibility score is equated with the correction on each input variable needed to attain the highest possible likelihood. We begin by showing formally why mainstream model-agnostic explanation methods, such as the local linear surrogate modeling and Shapley values, are not designed to explain anomalies. In particular, we show that they are ``deviation-agnostic,'' namely, that their explanations are blind to the fact that there is a deviation in the model prediction for the sample of interest. We do this by positioning these existing methods under the unified umbrella of a function family we call the ``integrated gradient family.'' We validate the effectiveness of the proposed LC approach using publicly available data sets. We also conduct a case study with a real-world building energy prediction task and confirm its usefulness in practice based on expert feedback.
Targeted Advertising on Social Networks Using Online Variational Tensor Regression
Aug 25, 2022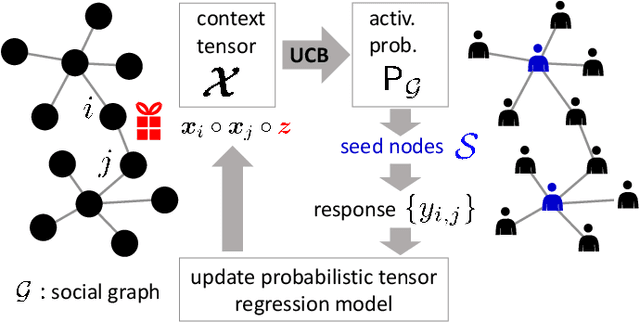

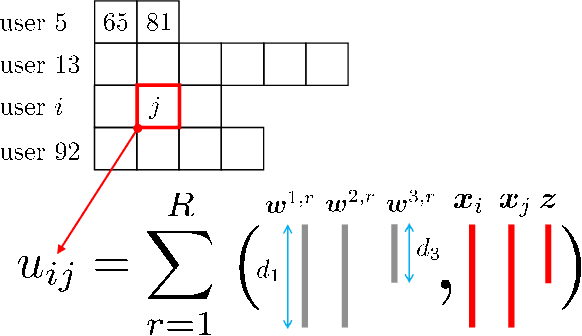
This paper is concerned with online targeted advertising on social networks. The main technical task we address is to estimate the activation probability for user pairs, which quantifies the influence one user may have on another towards purchasing decisions. This is a challenging task because one marketing episode typically involves a multitude of marketing campaigns/strategies of different products for highly diverse customers. In this paper, we propose what we believe is the first tensor-based contextual bandit framework for online targeted advertising. The proposed framework is designed to accommodate any number of feature vectors in the form of multi-mode tensor, thereby enabling to capture the heterogeneity that may exist over user preferences, products, and campaign strategies in a unified manner. To handle inter-dependency of tensor modes, we introduce an online variational algorithm with a mean-field approximation. We empirically confirm that the proposed TensorUCB algorithm achieves a significant improvement in influence maximization tasks over the benchmarks, which is attributable to its capability of capturing the user-product heterogeneity.
Anomaly Attribution with Likelihood Compensation
Aug 23, 2022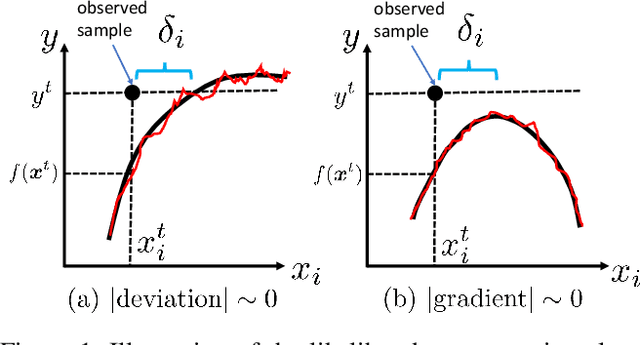
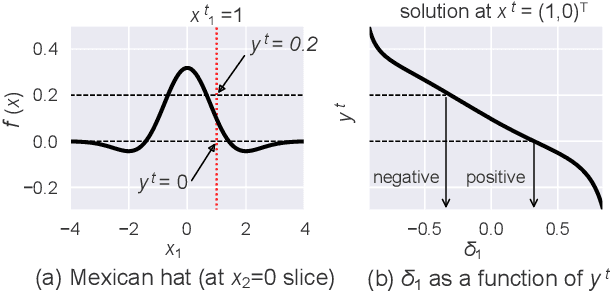
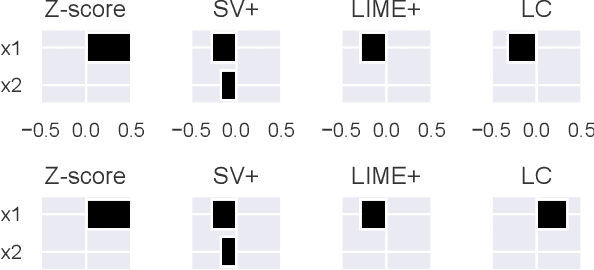
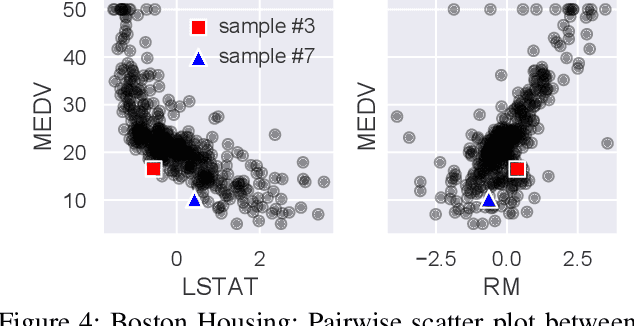
This paper addresses the task of explaining anomalous predictions of a black-box regression model. When using a black-box model, such as one to predict building energy consumption from many sensor measurements, we often have a situation where some observed samples may significantly deviate from their prediction. It may be due to a sub-optimal black-box model, or simply because those samples are outliers. In either case, one would ideally want to compute a ``responsibility score'' indicative of the extent to which an input variable is responsible for the anomalous output. In this work, we formalize this task as a statistical inverse problem: Given model deviation from the expected value, infer the responsibility score of each of the input variables. We propose a new method called likelihood compensation (LC), which is founded on the likelihood principle and computes a correction to each input variable. To the best of our knowledge, this is the first principled framework that computes a responsibility score for real valued anomalous model deviations. We apply our approach to a real-world building energy prediction task and confirm its utility based on expert feedback.
Cardinality-Regularized Hawkes-Granger Model
Aug 23, 2022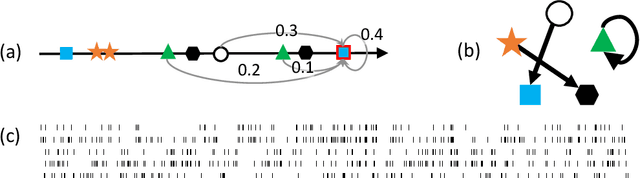
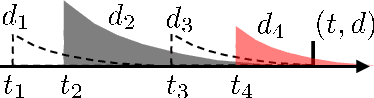

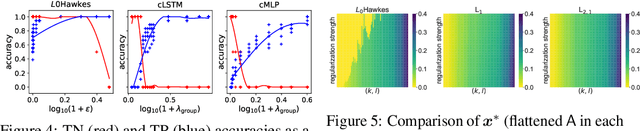
We propose a new sparse Granger-causal learning framework for temporal event data. We focus on a specific class of point processes called the Hawkes process. We begin by pointing out that most of the existing sparse causal learning algorithms for the Hawkes process suffer from a singularity in maximum likelihood estimation. As a result, their sparse solutions can appear only as numerical artifacts. In this paper, we propose a mathematically well-defined sparse causal learning framework based on a cardinality-regularized Hawkes process, which remedies the pathological issues of existing approaches. We leverage the proposed algorithm for the task of instance-wise causal event analysis, where sparsity plays a critical role. We validate the proposed framework with two real use-cases, one from the power grid and the other from the cloud data center management domain.
Directed Graph Auto-Encoders
Feb 25, 2022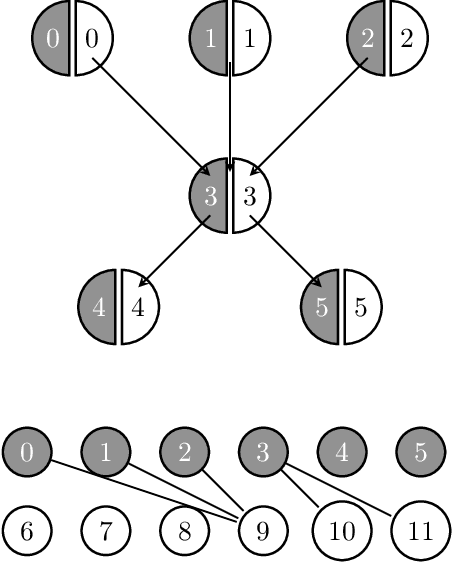

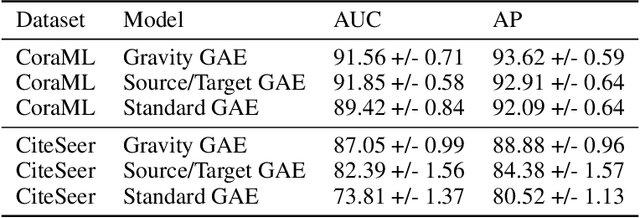

We introduce a new class of auto-encoders for directed graphs, motivated by a direct extension of the Weisfeiler-Leman algorithm to pairs of node labels. The proposed model learns pairs of interpretable latent representations for the nodes of directed graphs, and uses parameterized graph convolutional network (GCN) layers for its encoder and an asymmetric inner product decoder. Parameters in the encoder control the weighting of representations exchanged between neighboring nodes. We demonstrate the ability of the proposed model to learn meaningful latent embeddings and achieve superior performance on the directed link prediction task on several popular network datasets.
Word Clustering and Disambiguation Based on Co-occurrence Data
Jul 17, 1998

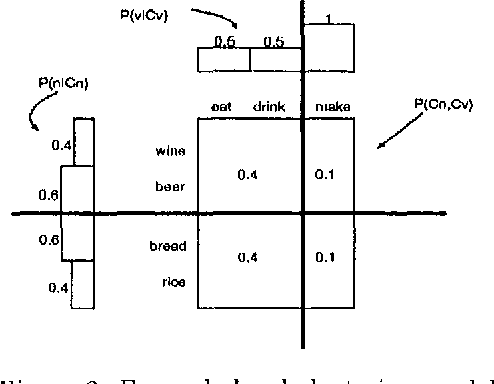
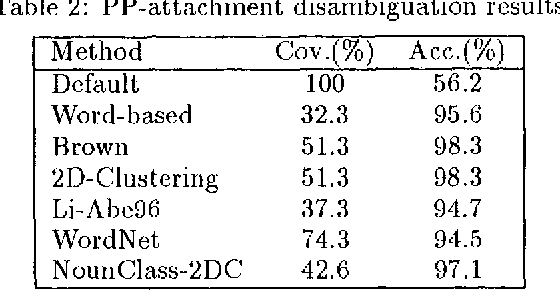
We address the problem of clustering words (or constructing a thesaurus) based on co-occurrence data, and using the acquired word classes to improve the accuracy of syntactic disambiguation. We view this problem as that of estimating a joint probability distribution specifying the joint probabilities of word pairs, such as noun verb pairs. We propose an efficient algorithm based on the Minimum Description Length (MDL) principle for estimating such a probability distribution. Our method is a natural extension of those proposed in (Brown et al 92) and (Li & Abe 96), and overcomes their drawbacks while retaining their advantages. We then combined this clustering method with the disambiguation method of (Li & Abe 95) to derive a disambiguation method that makes use of both automatically constructed thesauruses and a hand-made thesaurus. The overall disambiguation accuracy achieved by our method is 85.2%, which compares favorably against the accuracy (82.4%) obtained by the state-of-the-art disambiguation method of (Brill & Resnik 94).