 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring Fairness under Prior Probability Shifts
May 06, 2020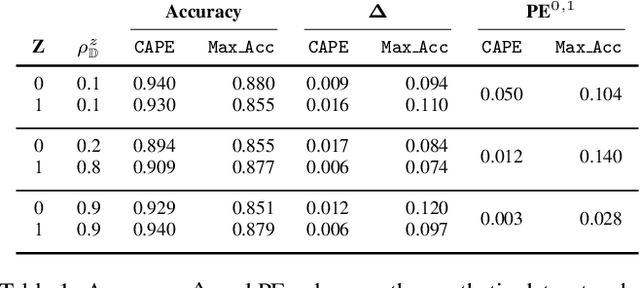
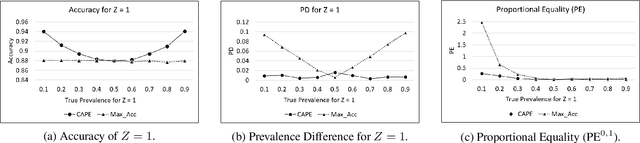
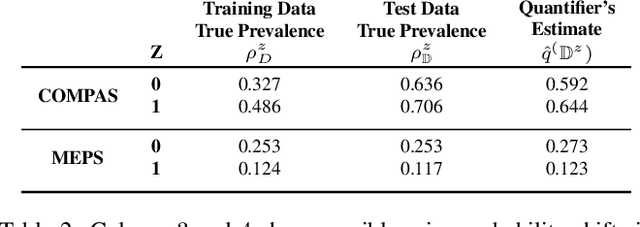
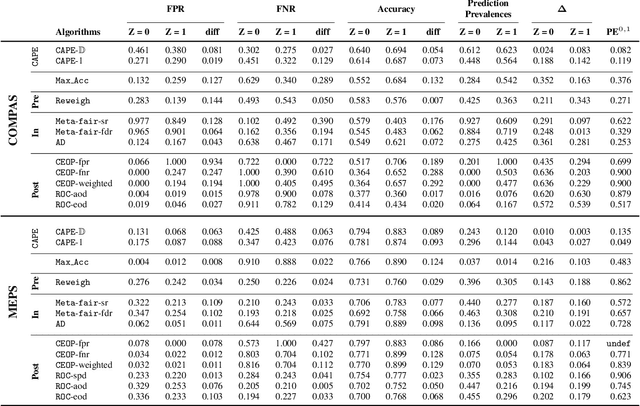
In this paper, we study the problem of fair classification in the presence of prior probability shifts, where the training set distribution differs from the test set. This phenomenon can be observed in the yearly records of several real-world datasets, such as recidivism records and medical expenditure surveys. If unaccounted for, such shifts can cause the predictions of a classifier to become unfair towards specific population subgroups. While the fairness notion called Proportional Equality (PE) accounts for such shifts, a procedure to ensure PE-fairness was unknown. In this work, we propose a method, called CAPE, which provides a comprehensive solution to the aforementioned problem. CAPE makes novel use of prevalence estimation techniques, sampling and an ensemble of classifiers to ensure fair predictions under prior probability shifts. We introduce a metric, called prevalence difference (PD), which CAPE attempts to minimize in order to ensure PE-fairness. We theoretically establish that this metric exhibits several desirable properties. We evaluate the efficacy of CAPE via a thorough empirical evaluation on synthetic datasets. We also compare the performance of CAPE with several popular fair classifiers on real-world datasets like COMPAS (criminal risk assessment) and MEPS (medical expenditure panel survey). The results indicate that CAPE ensures PE-fair predictions, while performing well on other performance metrics.