 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch Knowledge Graphs: the Shifting Paradigm of Scholarly Information Representation
Jun 08, 2025Sharing and reusing research artifacts, such as datasets, publications, or methods is a fundamental part of scientific activity, where heterogeneity of resources and metadata and the common practice of capturing information in unstructured publications pose crucial challenges. Reproducibility of research and finding state-of-the-art methods or data have become increasingly challenging. In this context, the concept of Research Knowledge Graphs (RKGs) has emerged, aiming at providing an easy to use and machine-actionable representation of research artifacts and their relations. That is facilitated through the use of established principles for data representation, the consistent adoption of globally unique persistent identifiers and the reuse and linking of vocabularies and data. This paper provides the first conceptualisation of the RKG vision, a categorisation of in-use RKGs together with a description of RKG building blocks and principles. We also survey real-world RKG implementations differing with respect to scale, schema, data, used vocabulary, and reliability of the contained data. We also characterise different RKG construction methodologies and provide a forward-looking perspective on the diverse applications, opportunities, and challenges associated with the RKG vision.
Toward FAIR Semantic Publishing of Research Dataset Metadata in the Open Research Knowledge Graph
Apr 12, 2024Search engines these days can serve datasets as search results. Datasets get picked up by search technologies based on structured descriptions on their official web pages, informed by metadata ontologies such as the Dataset content type of schema.org. Despite this promotion of the content type dataset as a first-class citizen of search results, a vast proportion of datasets, particularly research datasets, still need to be made discoverable and, therefore, largely remain unused. This is due to the sheer volume of datasets released every day and the inability of metadata to reflect a dataset's content and context accurately. This work seeks to improve this situation for a specific class of datasets, namely research datasets, which are the result of research endeavors and are accompanied by a scholarly publication. We propose the ORKG-Dataset content type, a specialized branch of the Open Research Knowledge Graoh (ORKG) platform, which provides descriptive information and a semantic model for research datasets, integrating them with their accompanying scholarly publications. This work aims to establish a standardized framework for recording and reporting research datasets within the ORKG-Dataset content type. This, in turn, increases research dataset transparency on the web for their improved discoverability and applied use. In this paper, we present a proposal -- the minimum FAIR, comparable, semantic description of research datasets in terms of salient properties of their supporting publication. We design a specific application of the ORKG-Dataset semantic model based on 40 diverse research datasets on scientific information extraction.
* 8 pages, 1 figure, published in the Joint Proceedings of the Onto4FAIR 2023 Workshops
GSAP-NER: A Novel Task, Corpus, and Baseline for Scholarly Entity Extraction Focused on Machine Learning Models and Datasets
Nov 16, 2023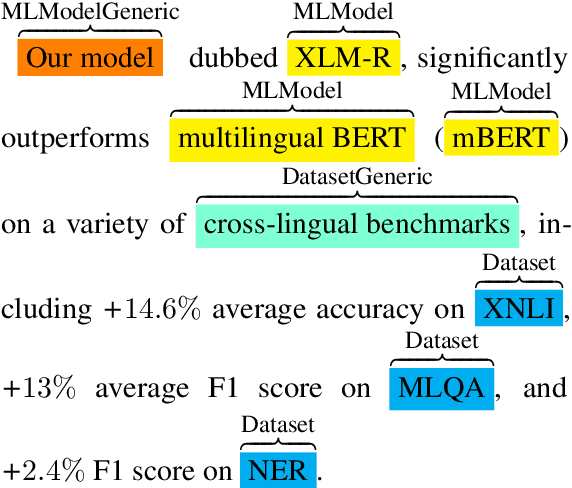
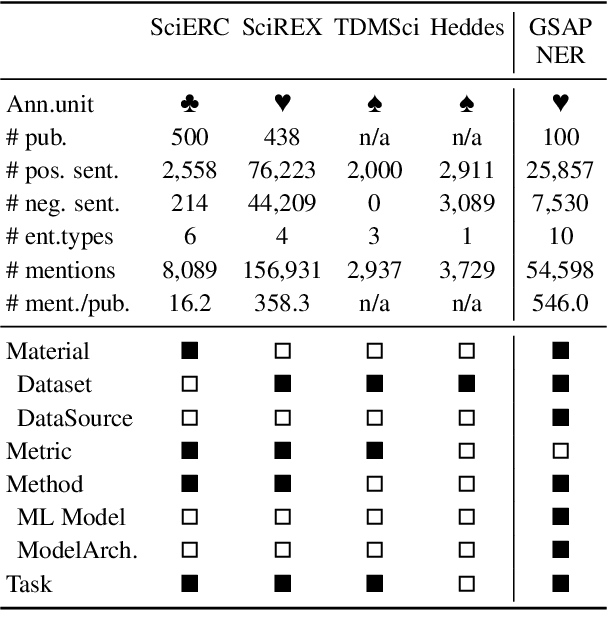

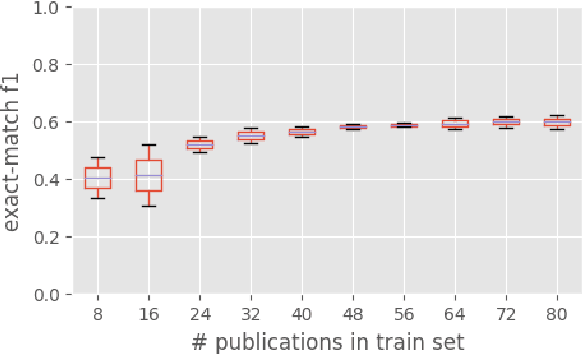
Named Entity Recognition (NER) models play a crucial role in various NLP tasks, including information extraction (IE) and text understanding. In academic writing, references to machine learning models and datasets are fundamental components of various computer science publications and necessitate accurate models for identification. Despite the advancements in NER, existing ground truth datasets do not treat fine-grained types like ML model and model architecture as separate entity types, and consequently, baseline models cannot recognize them as such. In this paper, we release a corpus of 100 manually annotated full-text scientific publications and a first baseline model for 10 entity types centered around ML models and datasets. In order to provide a nuanced understanding of how ML models and datasets are mentioned and utilized, our dataset also contains annotations for informal mentions like "our BERT-based model" or "an image CNN". You can find the ground truth dataset and code to replicate model training at https://data.gesis.org/gsap/gsap-ner.