 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePap2Pat: Towards Automated Paper-to-Patent Drafting using Chunk-based Outline-guided Generation
Paper and Code
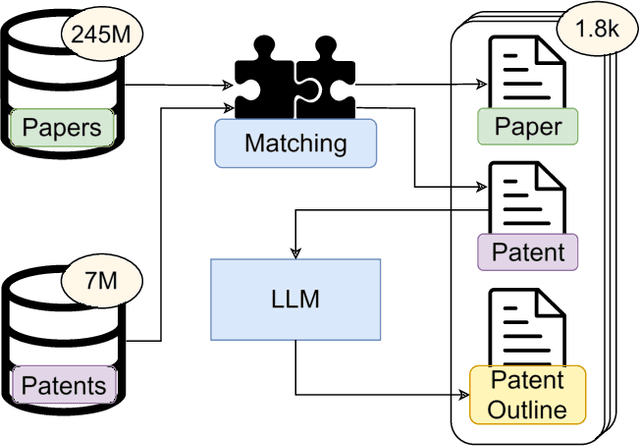
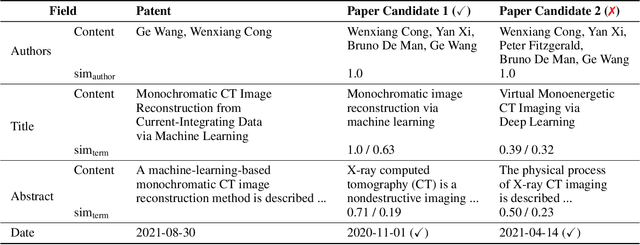


The patent domain is gaining attention in natural language processing research, offering practical applications in streamlining the patenting process and providing challenging benchmarks for large language models (LLMs). However, the generation of the description sections of patents, which constitute more than 90% of the patent document, has not been studied to date. We address this gap by introducing the task of outline-guided paper-to-patent generation, where an academic paper provides the technical specification of the invention and an outline conveys the desired patent structure. We present PAP2PAT, a new challenging benchmark of 1.8k patent-paper pairs with document outlines, collected using heuristics that reflect typical research lab practices. Our experiments with current open-weight LLMs and outline-guided chunk-based generation show that they can effectively use information from the paper but struggle with repetitions, likely due to the inherent repetitiveness of patent language. We release our data and code.