 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEDANTIC: A Dataset for the Automatic Examination of Definiteness in Patent Claims
May 28, 2025Patent claims define the scope of protection for an invention. If there are ambiguities in a claim, it is rejected by the patent office. In the US, this is referred to as indefiniteness (35 U.S.C {\S} 112(b)) and is among the most frequent reasons for patent application rejection. The development of automatic methods for patent definiteness examination has the potential to make patent drafting and examination more efficient, but no annotated dataset has been published to date. We introduce PEDANTIC (Patent Definiteness Examination Corpus), a novel dataset of 14k US patent claims from patent applications relating to Natural Language Processing (NLP), annotated with reasons for indefiniteness. We construct PEDANTIC using a fully automatic pipeline that retrieves office action documents from the USPTO and uses Large Language Models (LLMs) to extract the reasons for indefiniteness. A human validation study confirms the pipeline's accuracy in generating high-quality annotations. To gain insight beyond binary classification metrics, we implement an LLM-as-Judge evaluation that compares the free-form reasoning of every model-cited reason with every examiner-cited reason. We show that LLM agents based on Qwen 2.5 32B and 72B struggle to outperform logistic regression baselines on definiteness prediction, even though they often correctly identify the underlying reasons. PEDANTIC provides a valuable resource for patent AI researchers, enabling the development of advanced examination models. We will publicly release the dataset and code.
Pap2Pat: Towards Automated Paper-to-Patent Drafting using Chunk-based Outline-guided Generation
Oct 09, 2024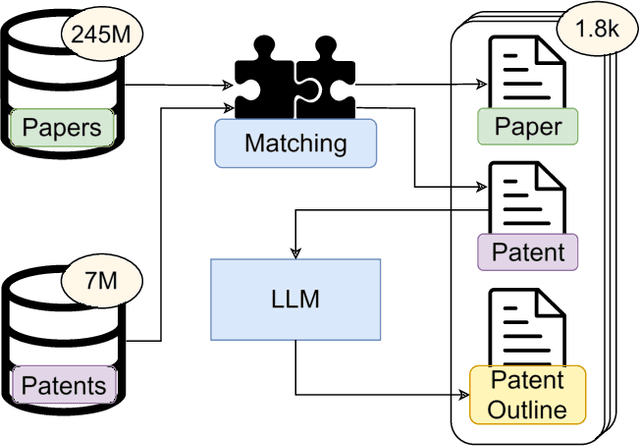
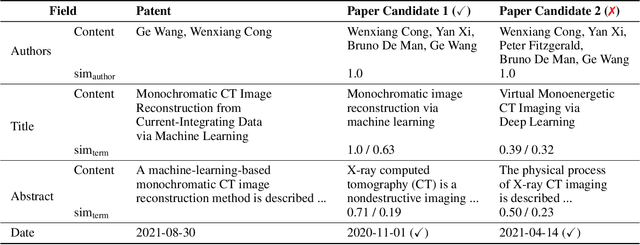


The patent domain is gaining attention in natural language processing research, offering practical applications in streamlining the patenting process and providing challenging benchmarks for large language models (LLMs). However, the generation of the description sections of patents, which constitute more than 90% of the patent document, has not been studied to date. We address this gap by introducing the task of outline-guided paper-to-patent generation, where an academic paper provides the technical specification of the invention and an outline conveys the desired patent structure. We present PAP2PAT, a new challenging benchmark of 1.8k patent-paper pairs with document outlines, collected using heuristics that reflect typical research lab practices. Our experiments with current open-weight LLMs and outline-guided chunk-based generation show that they can effectively use information from the paper but struggle with repetitions, likely due to the inherent repetitiveness of patent language. We release our data and code.
BoschAI @ PLABA 2023: Leveraging Edit Operations in End-to-End Neural Sentence Simplification
Nov 03, 2023



Automatic simplification can help laypeople to comprehend complex scientific text. Language models are frequently applied to this task by translating from complex to simple language. In this paper, we describe our system based on Llama 2, which ranked first in the PLABA shared task addressing the simplification of biomedical text. We find that the large portion of shared tokens between input and output leads to weak training signals and conservatively editing models. To mitigate these issues, we propose sentence-level and token-level loss weights. They give higher weight to modified tokens, indicated by edit distance and edit operations, respectively. We conduct an empirical evaluation on the PLABA dataset and find that both approaches lead to simplifications closer to those created by human annotators (+1.8% / +3.5% SARI), simpler language (-1 / -1.1 FKGL) and more edits (1.6x / 1.8x edit distance) compared to the same model fine-tuned with standard cross entropy. We furthermore show that the hyperparameter $\lambda$ in token-level loss weights can be used to control the edit distance and the simplicity level (FKGL).