 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Video Coding Knowledge for Deep Video Enhancement
Feb 27, 2023


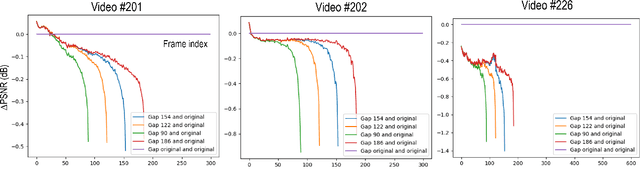
Recent advancements in deep learning techniques have significantly improved the quality of compressed videos. However, previous approaches have not fully exploited the motion characteristics of compressed videos, such as the drastic change in motion between video contents and the hierarchical coding structure of the compressed video. This study proposes a novel framework that leverages the low-delay configuration of video compression to enhance the existing state-of-the-art method, BasicVSR++. We incorporate a context-adaptive video fusion method to enhance the final quality of compressed videos. The proposed approach has been evaluated in the NTIRE22 challenge, a benchmark for video restoration and enhancement, and achieved improvements in both quantitative metrics and visual quality compared to the previous method.
Human-Imperceptible Identification with Learnable Lensless Imaging
Feb 04, 2023



Lensless imaging protects visual privacy by capturing heavily blurred images that are imperceptible for humans to recognize the subject but contain enough information for machines to infer information. Unfortunately, protecting visual privacy comes with a reduction in recognition accuracy and vice versa. We propose a learnable lensless imaging framework that protects visual privacy while maintaining recognition accuracy. To make captured images imperceptible to humans, we designed several loss functions based on total variation, invertibility, and the restricted isometry property. We studied the effect of privacy protection with blurriness on the identification of personal identity via a quantitative method based on a subjective evaluation. Moreover, we validate our simulation by implementing a hardware realization of lensless imaging with photo-lithographically printed masks.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022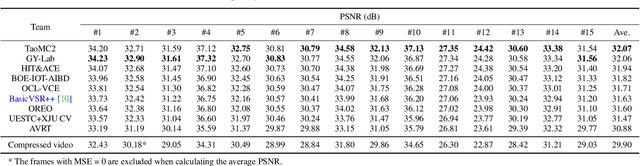
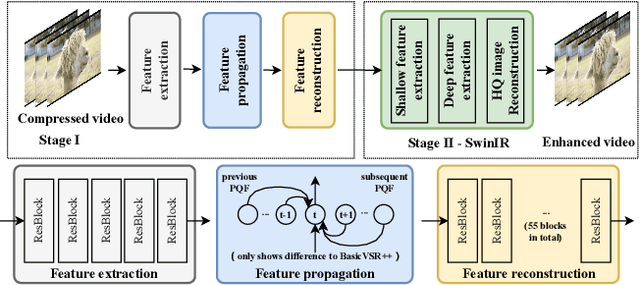
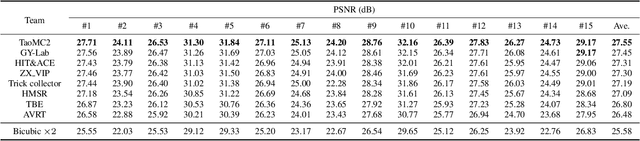

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Multi-Scale Deep Compressive Imaging
Aug 03, 2020

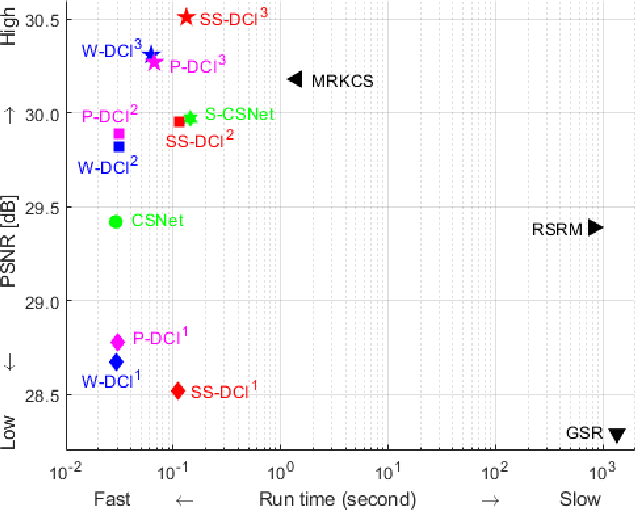
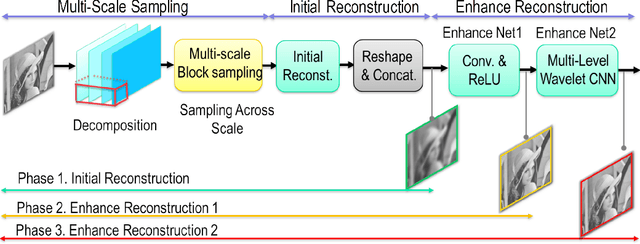
Recently, deep learning-based compressive imaging (DCI) has surpassed the conventional compressive imaging in reconstruction quality and faster running time. While multi-scale has shown superior performance over single-scale, research in DCI has been limited to single-scale sampling. Despite training with single-scale images, DCI tends to favor low-frequency components similar to the conventional multi-scale sampling, especially at low subrate. From this perspective, it would be easier for the network to learn multi-scale features with a multi-scale sampling architecture. In this work, we proposed a multi-scale deep compressive imaging (MS-DCI) framework which jointly learns to decompose, sample, and reconstruct images at multi-scale. A three-phase end-to-end training scheme was introduced with an initial and two enhance reconstruction phases to demonstrate the efficiency of multi-scale sampling and further improve the reconstruction performance. We analyzed the decomposition methods (including Pyramid, Wavelet, and Scale-space), sampling matrices, and measurements and showed the empirical benefit of MS-DCI which consistently outperforms both conventional and deep learning-based approaches.
Restricted Structural Random Matrix for Compressive Sensing
Feb 18, 2020

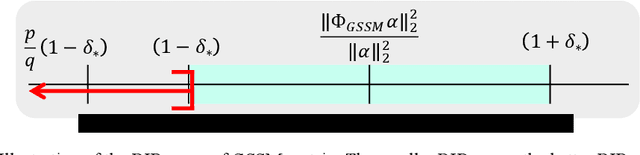

Compressive sensing (CS) is well-known for its unique functionalities of sensing, compressing, and security (i.e. CS measurements are equally important). However, there is a tradeoff. Improving sensing and compressing efficiency with prior signal information tends to favor particular measurements, thus decrease the security. This work aimed to improve the sensing and compressing efficiency without compromise the security with a novel sampling matrix, named Restricted Structural Random Matrix (RSRM). RSRM unified the advantages of frame-based and block-based sensing together with the global smoothness prior (i.e. low-resolution signals are highly correlated). RSRM acquired compressive measurements with random projection (equally important) of multiple randomly sub-sampled signals, which was restricted to be the low-resolution signals (equal in energy), thereby, its observations are equally important. RSRM was proven to satisfies the Restricted Isometry Property and shows comparable reconstruction performance with recent state-of-the-art compressive sensing and deep learning-based methods.
Multi-Scale Deep Compressive Sensing Network
Sep 18, 2018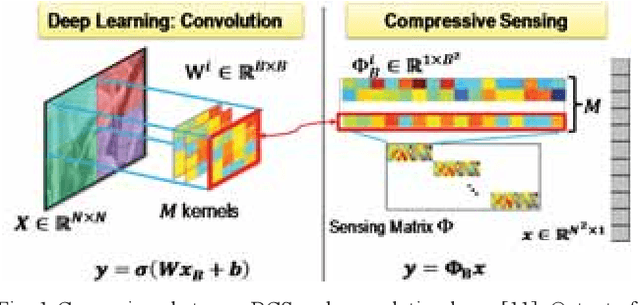


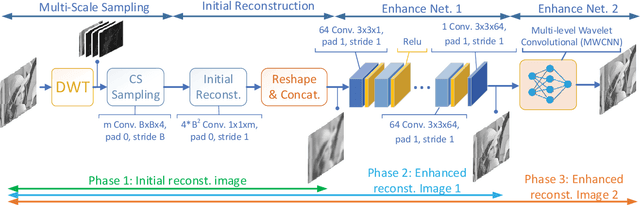
With joint learning of sampling and recovery, the deep learning-based compressive sensing (DCS) has shown significant improvement in performance and running time reduction. Its reconstructed image, however, losses high-frequency content especially at low subrates. This happens similarly in the multi-scale sampling scheme which also samples more low-frequency components. In this paper, we propose a multi-scale DCS convolutional neural network (MS-DCSNet) in which we convert image signal using multiple scale-based wavelet transform, then capture it through convolution block by block across scales. The initial reconstructed image is directly recovered from multi-scale measurements. Multi-scale wavelet convolution is utilized to enhance the final reconstruction quality. The network is able to learn both multi-scale sampling and multi-scale reconstruction, thus results in better reconstruction quality.
Compressive Sensing of Color Images Using Nonlocal Higher Order Dictionary
Nov 26, 2017
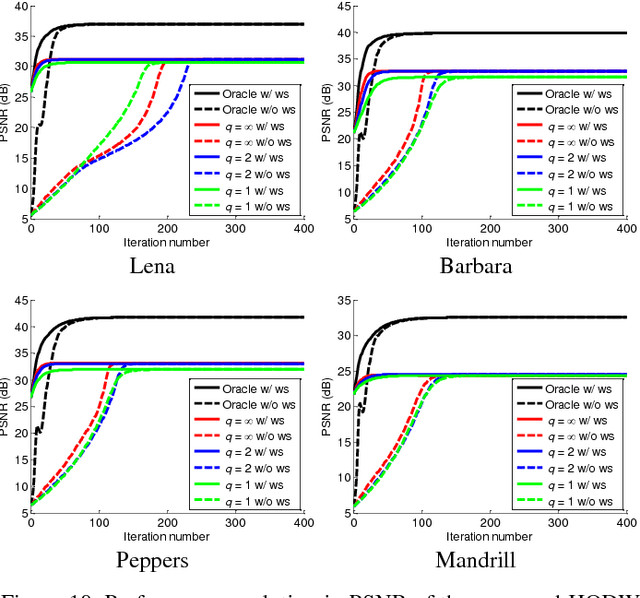
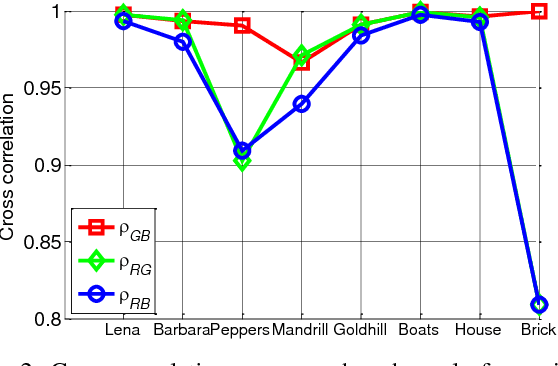

This paper addresses an ill-posed problem of recovering a color image from its compressively sensed measurement data. Differently from the typical 1D vector-based approach of the state-of-the-art methods, we exploit the nonlocal similarities inherently existing in images by treating each patch of a color image as a 3D tensor consisting of not only horizontal and vertical but also spectral dimensions. A group of nonlocal similar patches form a 4D tensor for which a nonlocal higher order dictionary is learned via higher order singular value decomposition. The multiple sub-dictionaries contained in the higher order dictionary decorrelate the group in each corresponding dimension, thus help the detail of color images to be reconstructed better. Furthermore, we promote sparsity of the final solution using a sparsity regularization based on a weight tensor. It can distinguish those coefficients of the sparse representation generated by the higher order dictionary which are expected to have large magnitude from the others in the optimization. Accordingly, in the iterative solution, it acts like a weighting process which is designed by approximating the minimum mean squared error filter for more faithful recovery. Experimental results confirm improvement by the proposed method over the state-of-the-art ones.