 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoTDiff: High-resolution Motion Trajectory estimation from a single blurred image using Diffusion models
Oct 30, 2025



Accurate estimation of motion information is crucial in diverse computational imaging and computer vision applications. Researchers have investigated various methods to extract motion information from a single blurred image, including blur kernels and optical flow. However, existing motion representations are often of low quality, i.e., coarse-grained and inaccurate. In this paper, we propose the first high-resolution (HR) Motion Trajectory estimation framework using Diffusion models (MoTDiff). Different from existing motion representations, we aim to estimate an HR motion trajectory with high-quality from a single motion-blurred image. The proposed MoTDiff consists of two key components: 1) a new conditional diffusion framework that uses multi-scale feature maps extracted from a single blurred image as a condition, and 2) a new training method that can promote precise identification of a fine-grained motion trajectory, consistent estimation of overall shape and position of a motion path, and pixel connectivity along a motion trajectory. Our experiments demonstrate that the proposed MoTDiff can outperform state-of-the-art methods in both blind image deblurring and coded exposure photography applications.
Ray-Space Motion Compensation for Lenslet Plenoptic Video Coding
Jul 01, 2022
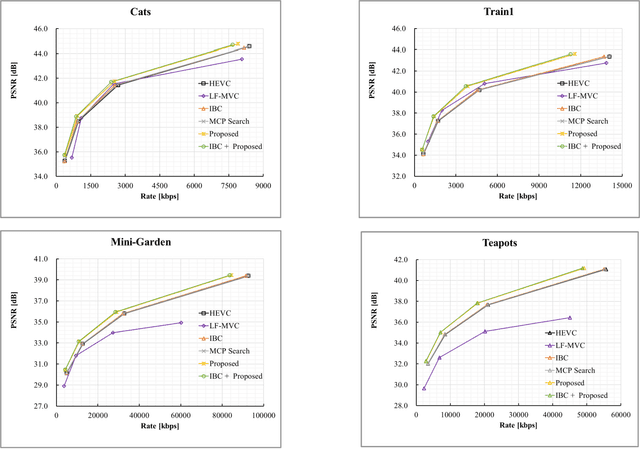
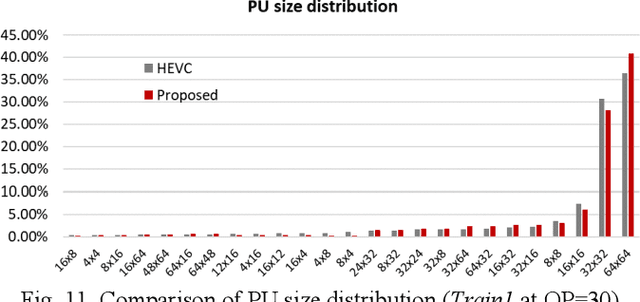
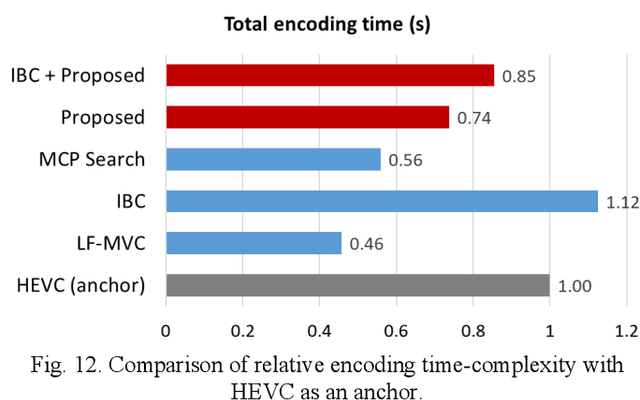
Plenoptic images and videos bearing rich information demand a tremendous amount of data storage and high transmission cost. While there has been much study on plenoptic image coding, investigations into plenoptic video coding have been very limited. We investigate the motion compensation for plenoptic video coding from a slightly different perspective by looking at the problem in the ray-space domain instead of in the conventional pixel domain. Here, we develop a novel motion compensation scheme for lenslet video under two sub-cases of ray-space motion, that is, integer ray-space motion and fractional ray-space motion. The proposed new scheme of light field motion-compensated prediction is designed such that it can be easily integrated into well-known video coding techniques such as HEVC. Experimental results compared to relevant existing methods have shown remarkable compression efficiency with an average gain of 19.63% and a peak gain of 29.1%.
Multi-Scale Deep Compressive Imaging
Aug 03, 2020

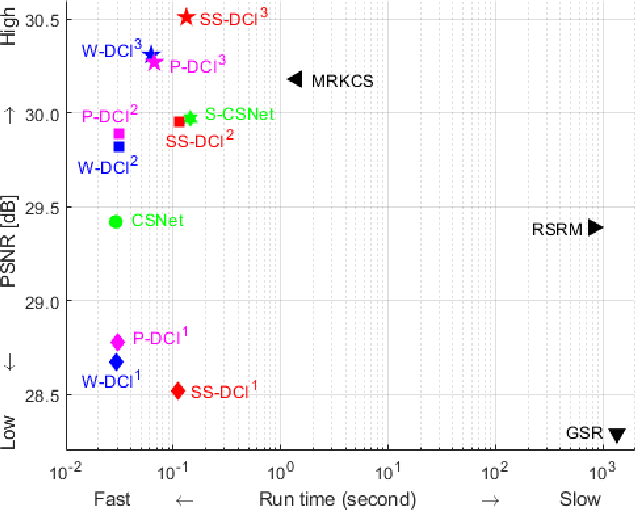
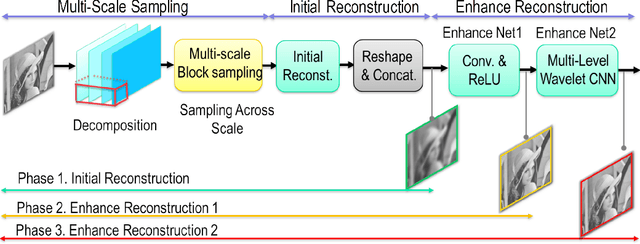
Recently, deep learning-based compressive imaging (DCI) has surpassed the conventional compressive imaging in reconstruction quality and faster running time. While multi-scale has shown superior performance over single-scale, research in DCI has been limited to single-scale sampling. Despite training with single-scale images, DCI tends to favor low-frequency components similar to the conventional multi-scale sampling, especially at low subrate. From this perspective, it would be easier for the network to learn multi-scale features with a multi-scale sampling architecture. In this work, we proposed a multi-scale deep compressive imaging (MS-DCI) framework which jointly learns to decompose, sample, and reconstruct images at multi-scale. A three-phase end-to-end training scheme was introduced with an initial and two enhance reconstruction phases to demonstrate the efficiency of multi-scale sampling and further improve the reconstruction performance. We analyzed the decomposition methods (including Pyramid, Wavelet, and Scale-space), sampling matrices, and measurements and showed the empirical benefit of MS-DCI which consistently outperforms both conventional and deep learning-based approaches.
Restricted Structural Random Matrix for Compressive Sensing
Feb 18, 2020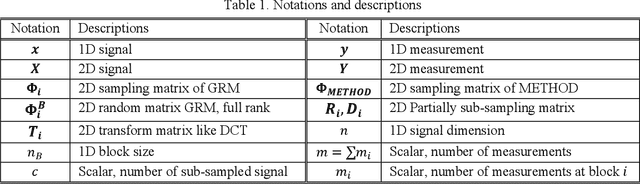


Compressive sensing (CS) is well-known for its unique functionalities of sensing, compressing, and security (i.e. CS measurements are equally important). However, there is a tradeoff. Improving sensing and compressing efficiency with prior signal information tends to favor particular measurements, thus decrease the security. This work aimed to improve the sensing and compressing efficiency without compromise the security with a novel sampling matrix, named Restricted Structural Random Matrix (RSRM). RSRM unified the advantages of frame-based and block-based sensing together with the global smoothness prior (i.e. low-resolution signals are highly correlated). RSRM acquired compressive measurements with random projection (equally important) of multiple randomly sub-sampled signals, which was restricted to be the low-resolution signals (equal in energy), thereby, its observations are equally important. RSRM was proven to satisfies the Restricted Isometry Property and shows comparable reconstruction performance with recent state-of-the-art compressive sensing and deep learning-based methods.
Multi-Scale Deep Compressive Sensing Network
Sep 18, 2018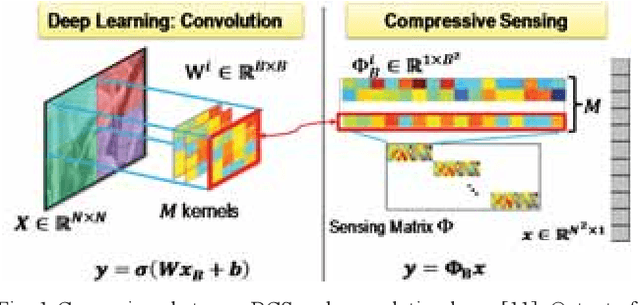


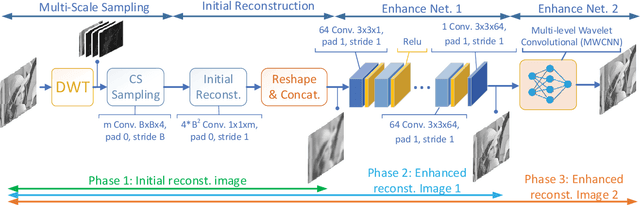
With joint learning of sampling and recovery, the deep learning-based compressive sensing (DCS) has shown significant improvement in performance and running time reduction. Its reconstructed image, however, losses high-frequency content especially at low subrates. This happens similarly in the multi-scale sampling scheme which also samples more low-frequency components. In this paper, we propose a multi-scale DCS convolutional neural network (MS-DCSNet) in which we convert image signal using multiple scale-based wavelet transform, then capture it through convolution block by block across scales. The initial reconstructed image is directly recovered from multi-scale measurements. Multi-scale wavelet convolution is utilized to enhance the final reconstruction quality. The network is able to learn both multi-scale sampling and multi-scale reconstruction, thus results in better reconstruction quality.
Compressive Sensing of Color Images Using Nonlocal Higher Order Dictionary
Nov 26, 2017

This paper addresses an ill-posed problem of recovering a color image from its compressively sensed measurement data. Differently from the typical 1D vector-based approach of the state-of-the-art methods, we exploit the nonlocal similarities inherently existing in images by treating each patch of a color image as a 3D tensor consisting of not only horizontal and vertical but also spectral dimensions. A group of nonlocal similar patches form a 4D tensor for which a nonlocal higher order dictionary is learned via higher order singular value decomposition. The multiple sub-dictionaries contained in the higher order dictionary decorrelate the group in each corresponding dimension, thus help the detail of color images to be reconstructed better. Furthermore, we promote sparsity of the final solution using a sparsity regularization based on a weight tensor. It can distinguish those coefficients of the sparse representation generated by the higher order dictionary which are expected to have large magnitude from the others in the optimization. Accordingly, in the iterative solution, it acts like a weighting process which is designed by approximating the minimum mean squared error filter for more faithful recovery. Experimental results confirm improvement by the proposed method over the state-of-the-art ones.
Block Compressive Sensing of Image and Video with Nonlocal Lagrangian Multiplier and Patch-based Sparse Representation
Mar 15, 2017



Although block compressive sensing (BCS) makes it tractable to sense large-sized images and video, its recovery performance has yet to be significantly improved because its recovered images or video usually suffer from blurred edges, loss of details, and high-frequency oscillatory artifacts, especially at a low subrate. This paper addresses these problems by designing a modified total variation technique that employs multi-block gradient processing, a denoised Lagrangian multiplier, and patch-based sparse representation. In the case of video, the proposed recovery method is able to exploit both spatial and temporal similarities. Simulation results confirm the improved performance of the proposed method for compressive sensing of images and video in terms of both objective and subjective qualities.
Total variation reconstruction for compressive sensing using nonlocal Lagrangian multiplier
Aug 28, 2016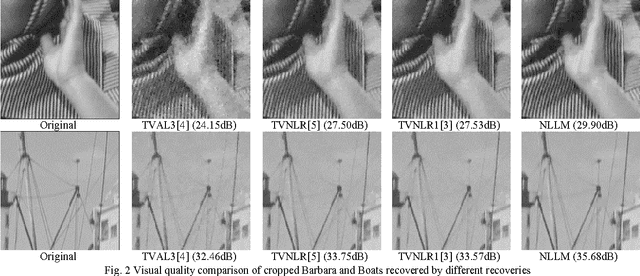
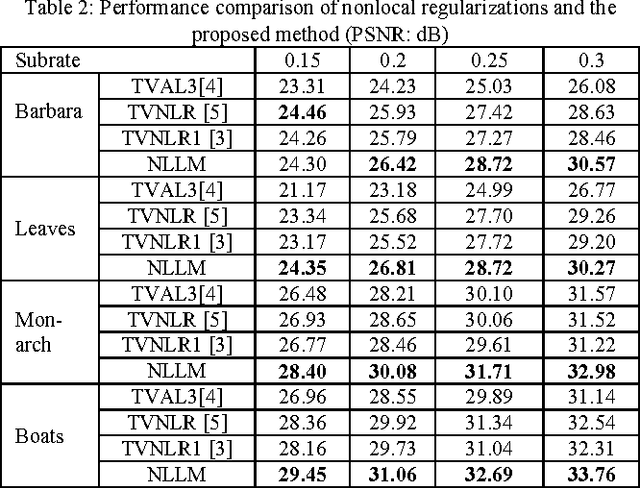

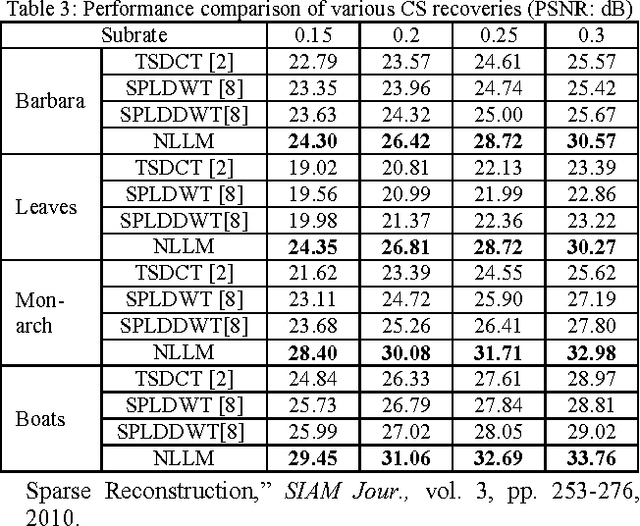
Total variation has proved its effectiveness in solving inverse problems for compressive sensing. Besides, the nonlocal means filter used as regularization preserves texture better for recovered images, but it is quite complex to implement. In this paper, based on existence of both noise and image information in the Lagrangian multiplier, we propose a simple method in term of implementation called nonlocal Lagrangian multiplier (NLLM) in order to reduce noise and boost useful image information. Experimental results show that the proposed NLLM is superior both in subjective and objective qualities of recovered image over other recovery algorithms.