 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Attention Mechanism for Handling All the Interactions between Many Inputs with Application to Visual Dialog
Paper and Code


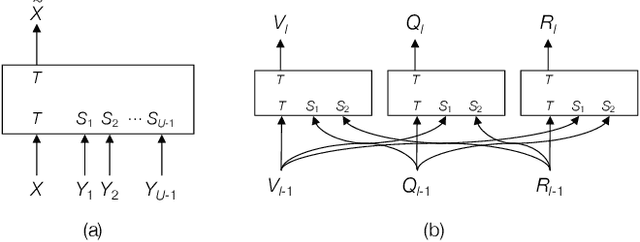
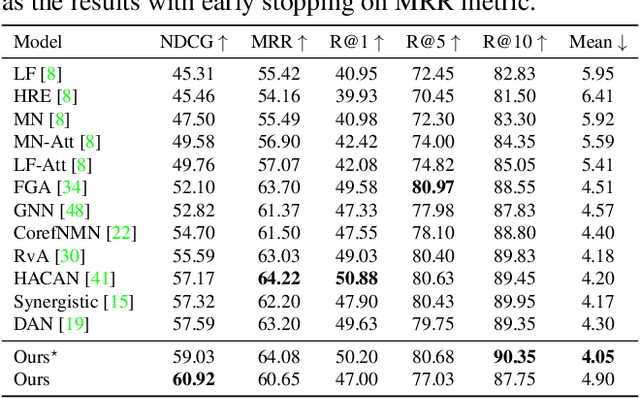
It has been a primary concern in recent studies of vision and language tasks to design an effective attention mechanism dealing with interactions between the two modalities. The Transformer has recently been extended and applied to several bi-modal tasks, yielding promising results. For visual dialog, it becomes necessary to consider interactions between three or more inputs, i.e., an image, a question, and a dialog history, or even its individual dialog components. In this paper, we present a neural architecture that can efficiently deal with all the interactions between many such inputs. It has a block structure similar to the Transformer and employs the same design of attention computation, whereas it has only a small number of parameters, yet has sufficient representational power for the purpose. Assuming a standard setting of visual dialog, a network built upon the proposed attention block has less than one-tenth of parameters as compared with its counterpart, a natural Transformer extension. We present its application to the visual dialog task. The experimental results validate the effectiveness of the proposed approach, showing improvements of the best NDCG score on the VisDial v1.0 dataset from 57.59 to 60.92 with a single model, from 64.47 to 66.53 with ensemble models, and even to 74.88 with additional finetuning.