 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-vocabulary vs. Closed-set: Best Practice for Few-shot Object Detection Considering Text Describability
Paper and Code
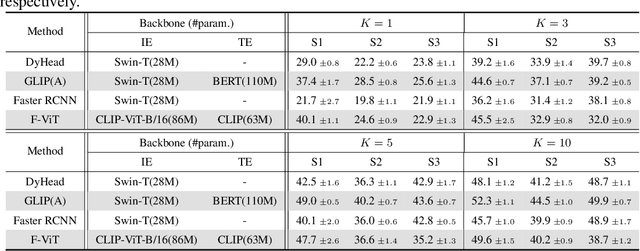
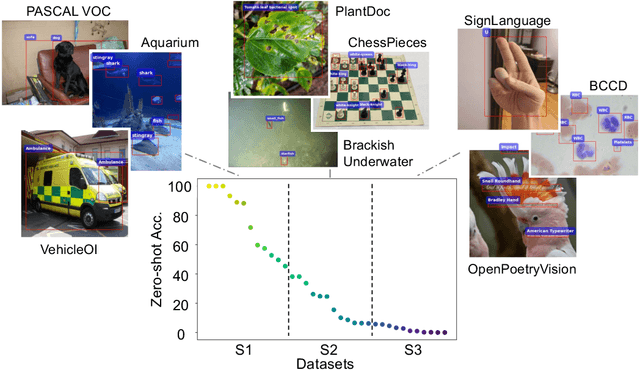
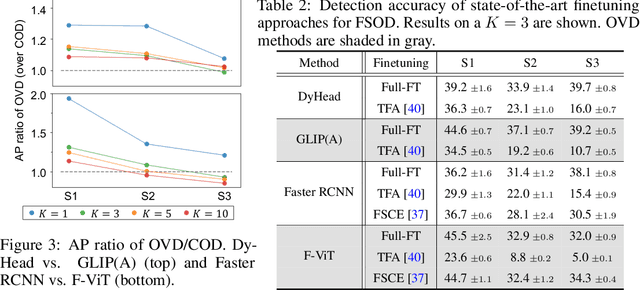
Open-vocabulary object detection (OVD), detecting specific classes of objects using only their linguistic descriptions (e.g., class names) without any image samples, has garnered significant attention. However, in real-world applications, the target class concepts is often hard to describe in text and the only way to specify target objects is to provide their image examples, yet it is often challenging to obtain a good number of samples. Thus, there is a high demand from practitioners for few-shot object detection (FSOD). A natural question arises: Can the benefits of OVD extend to FSOD for object classes that are difficult to describe in text? Compared to traditional methods that learn only predefined classes (referred to in this paper as closed-set object detection, COD), can the extra cost of OVD be justified? To answer these questions, we propose a method to quantify the ``text-describability'' of object detection datasets using the zero-shot image classification accuracy with CLIP. This allows us to categorize various OD datasets with different text-describability and emprically evaluate the FSOD performance of OVD and COD methods within each category. Our findings reveal that: i) there is little difference between OVD and COD for object classes with low text-describability under equal conditions in OD pretraining; and ii) although OVD can learn from more diverse data than OD-specific data, thereby increasing the volume of training data, it can be counterproductive for classes with low-text-describability. These findings provide practitioners with valuable guidance amidst the recent advancements of OVD methods.