 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Annotation for Object Detection: Is Annotating Small-size Instances Worth Its Cost?
Dec 07, 2024Detecting objects occupying only small areas in an image is difficult, even for humans. Therefore, annotating small-size object instances is hard and thus costly. This study questions common sense by asking the following: is annotating small-size instances worth its cost? We restate it as the following verifiable question: can we detect small-size instances with a detector trained using training data free of small-size instances? We evaluate a method that upscales input images at test time and a method that downscales images at training time. The experiments conducted using the COCO dataset show the following. The first method, together with a remedy to narrow the domain gap between training and test inputs, achieves at least comparable performance to the baseline detector trained using complete training data. Although the method needs to apply the same detector twice to an input image with different scaling, we show that its distillation yields a single-path detector that performs equally well to the same baseline detector. These results point to the necessity of rethinking the annotation of training data for object detection.
Open-vocabulary vs. Closed-set: Best Practice for Few-shot Object Detection Considering Text Describability
Oct 20, 2024
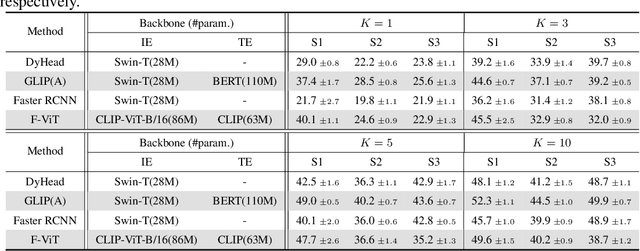
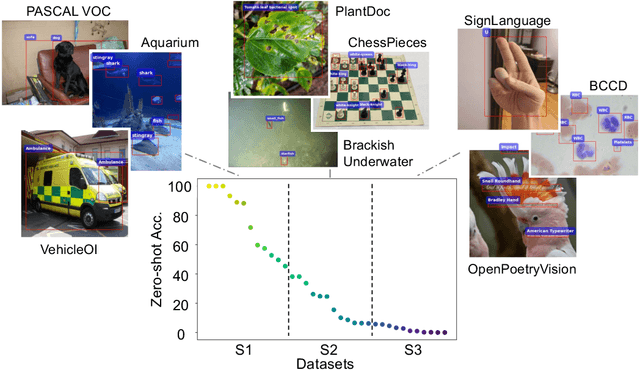
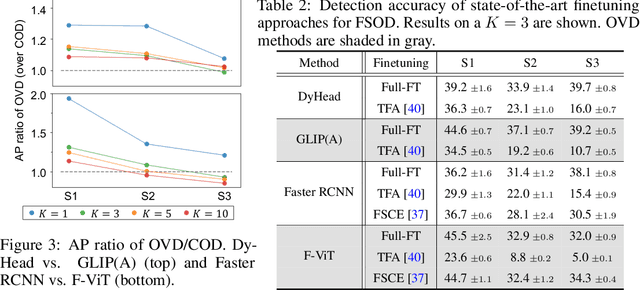
Open-vocabulary object detection (OVD), detecting specific classes of objects using only their linguistic descriptions (e.g., class names) without any image samples, has garnered significant attention. However, in real-world applications, the target class concepts is often hard to describe in text and the only way to specify target objects is to provide their image examples, yet it is often challenging to obtain a good number of samples. Thus, there is a high demand from practitioners for few-shot object detection (FSOD). A natural question arises: Can the benefits of OVD extend to FSOD for object classes that are difficult to describe in text? Compared to traditional methods that learn only predefined classes (referred to in this paper as closed-set object detection, COD), can the extra cost of OVD be justified? To answer these questions, we propose a method to quantify the ``text-describability'' of object detection datasets using the zero-shot image classification accuracy with CLIP. This allows us to categorize various OD datasets with different text-describability and emprically evaluate the FSOD performance of OVD and COD methods within each category. Our findings reveal that: i) there is little difference between OVD and COD for object classes with low text-describability under equal conditions in OD pretraining; and ii) although OVD can learn from more diverse data than OD-specific data, thereby increasing the volume of training data, it can be counterproductive for classes with low-text-describability. These findings provide practitioners with valuable guidance amidst the recent advancements of OVD methods.
More Practical Scenario of Open-set Object Detection: Open at Category Level and Closed at Super-category Level
Jul 20, 2022
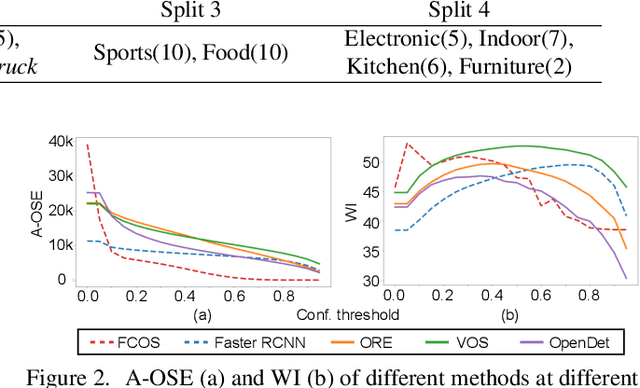

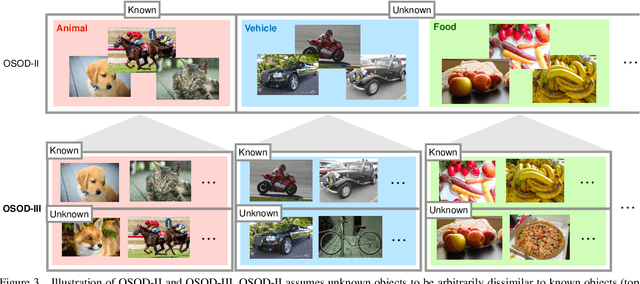
Open-set object detection (OSOD) has recently attracted considerable attention. It is to detect unknown objects while correctly detecting/classifying known objects. We first point out that the scenario of OSOD considered in recent studies, which considers an unlimited variety of unknown objects similar to open-set recognition (OSR), has a fundamental issue. That is, we cannot determine what to detect and what not for such unlimited unknown objects, which is necessary for detection tasks. This issue leads to difficulty with the evaluation of methods' performance on unknown object detection. We then introduce a novel scenario of OSOD, which deals with only unknown objects that share the super-category with known objects. It has many real-world applications, e.g., detecting an increasing number of fine-grained objects. This new setting is free from the above issue and evaluation difficulty. Moreover, it makes detecting unknown objects more realistic owing to the visual similarity between known and unknown objects. We show through experimental results that a simple method based on the uncertainty of class prediction from standard detectors outperforms the current state-of-the-art OSOD methods tested in the previous setting.
Analysis and a Solution of Momentarily Missed Detection for Anchor-based Object Detectors
Oct 21, 2019


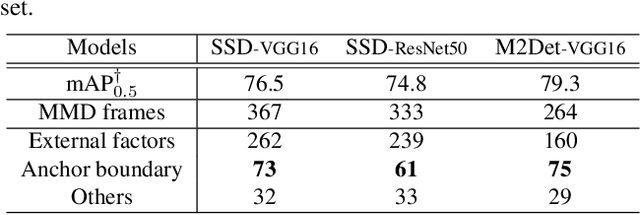
The employment of convolutional neural networks has led to significant performance improvement on the task of object detection. However, when applying existing detectors to continuous frames in a video, we often encounter momentary miss-detection of objects, that is, objects are undetected exceptionally at a few frames, although they are correctly detected at all other frames. In this paper, we analyze the mechanism of how such miss-detection occurs. For the most popular class of detectors that are based on anchor boxes, we show the followings: i) besides apparent causes such as motion blur, occlusions, background clutters, etc., the majority of remaining miss-detection can be explained by an improper behavior of the detectors at boundaries of the anchor boxes; and ii) this can be rectified by improving the way of choosing positive samples from candidate anchor boxes when training the detectors.