 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and a Solution of Momentarily Missed Detection for Anchor-based Object Detectors
Paper and Code



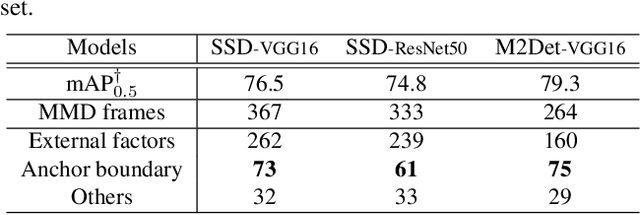
The employment of convolutional neural networks has led to significant performance improvement on the task of object detection. However, when applying existing detectors to continuous frames in a video, we often encounter momentary miss-detection of objects, that is, objects are undetected exceptionally at a few frames, although they are correctly detected at all other frames. In this paper, we analyze the mechanism of how such miss-detection occurs. For the most popular class of detectors that are based on anchor boxes, we show the followings: i) besides apparent causes such as motion blur, occlusions, background clutters, etc., the majority of remaining miss-detection can be explained by an improper behavior of the detectors at boundaries of the anchor boxes; and ii) this can be rectified by improving the way of choosing positive samples from candidate anchor boxes when training the detectors.