 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Multi-Scale Attention for Enhanced Multi-Scale Feature Extraction and Interaction with Low-Resolution Images
Paper and Code
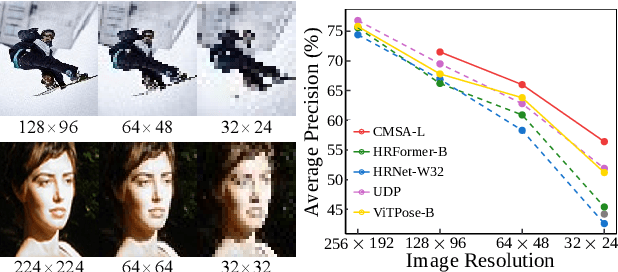
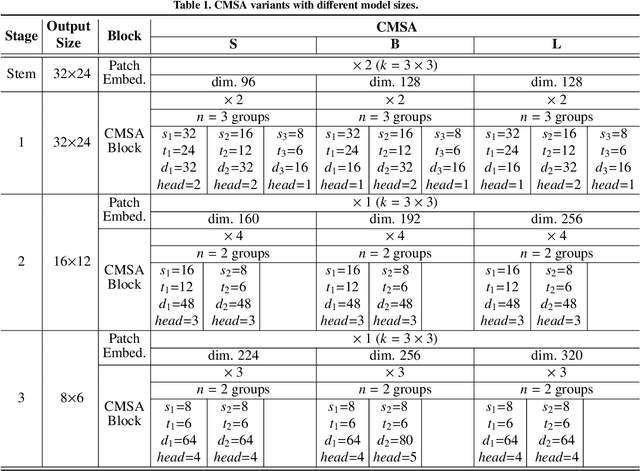
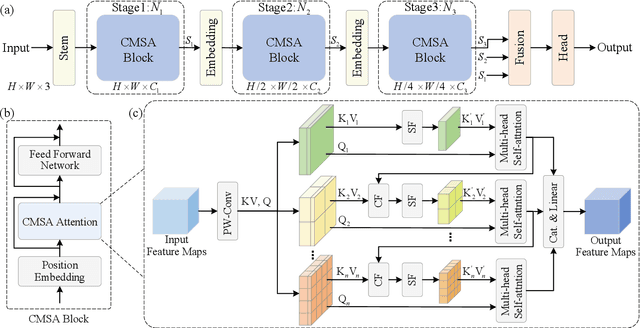
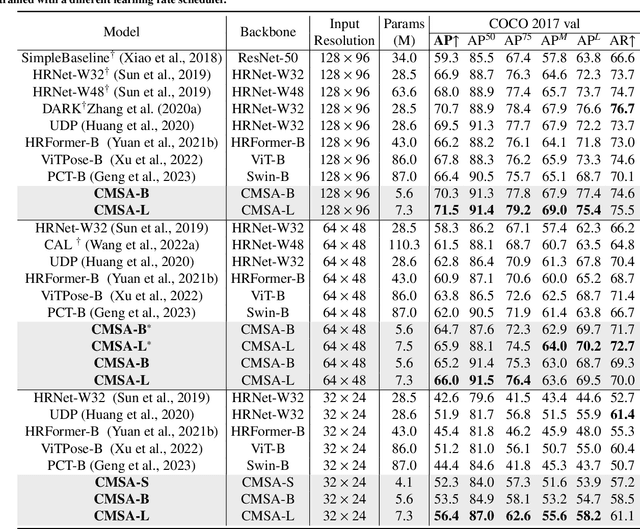
In real-world applications of image recognition tasks, such as human pose estimation, cameras often capture objects, like human bodies, at low resolutions. This scenario poses a challenge in extracting and leveraging multi-scale features, which is often essential for precise inference. To address this challenge, we propose a new attention mechanism, named cascaded multi-scale attention (CMSA), tailored for use in CNN-ViT hybrid architectures, to handle low-resolution inputs effectively. The design of CMSA enables the extraction and seamless integration of features across various scales without necessitating the downsampling of the input image or feature maps. This is achieved through a novel combination of grouped multi-head self-attention mechanisms with window-based local attention and cascaded fusion of multi-scale features over different scales. This architecture allows for the effective handling of features across different scales, enhancing the model's ability to perform tasks such as human pose estimation, head pose estimation, and more with low-resolution images. Our experimental results show that the proposed method outperforms existing state-of-the-art methods in these areas with fewer parameters, showcasing its potential for broad application in real-world scenarios where capturing high-resolution images is not feasible. Code is available at https://github.com/xyongLu/CMSA.