 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Multi-Scale Attention for Enhanced Multi-Scale Feature Extraction and Interaction with Low-Resolution Images
Dec 03, 2024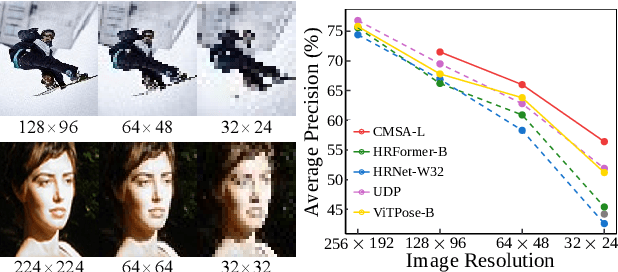
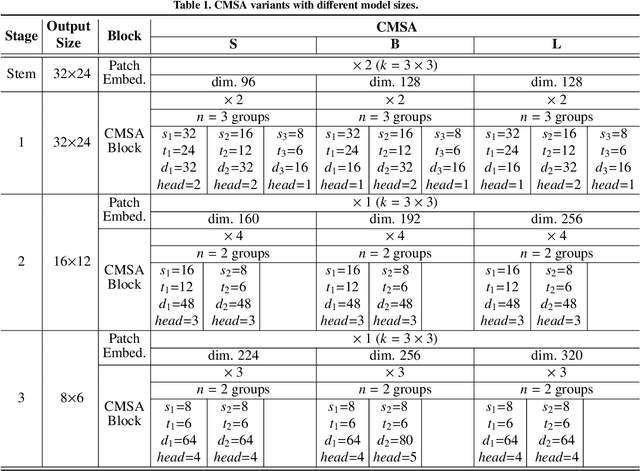
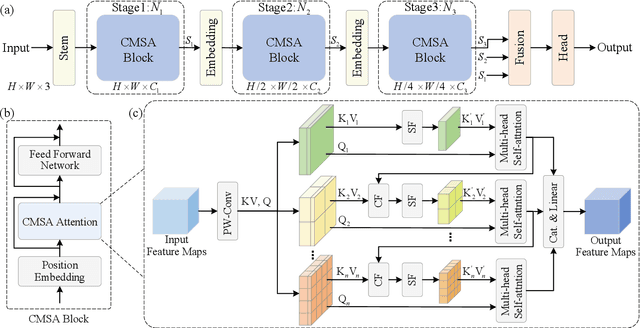
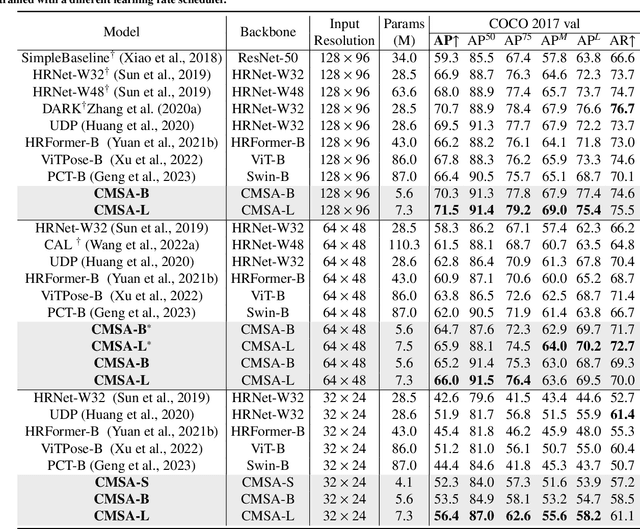
In real-world applications of image recognition tasks, such as human pose estimation, cameras often capture objects, like human bodies, at low resolutions. This scenario poses a challenge in extracting and leveraging multi-scale features, which is often essential for precise inference. To address this challenge, we propose a new attention mechanism, named cascaded multi-scale attention (CMSA), tailored for use in CNN-ViT hybrid architectures, to handle low-resolution inputs effectively. The design of CMSA enables the extraction and seamless integration of features across various scales without necessitating the downsampling of the input image or feature maps. This is achieved through a novel combination of grouped multi-head self-attention mechanisms with window-based local attention and cascaded fusion of multi-scale features over different scales. This architecture allows for the effective handling of features across different scales, enhancing the model's ability to perform tasks such as human pose estimation, head pose estimation, and more with low-resolution images. Our experimental results show that the proposed method outperforms existing state-of-the-art methods in these areas with fewer parameters, showcasing its potential for broad application in real-world scenarios where capturing high-resolution images is not feasible. Code is available at https://github.com/xyongLu/CMSA.
SBCFormer: Lightweight Network Capable of Full-size ImageNet Classification at 1 FPS on Single Board Computers
Nov 07, 2023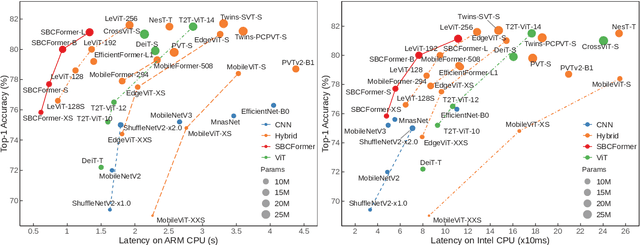
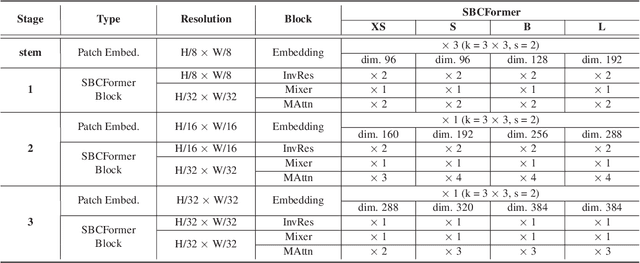
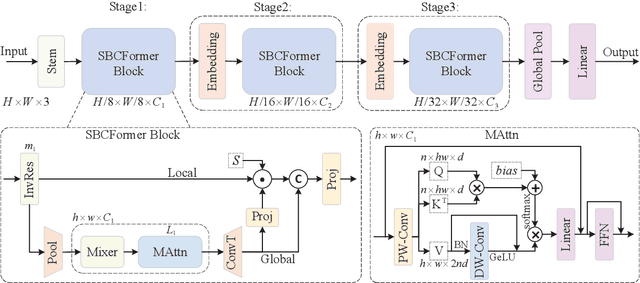
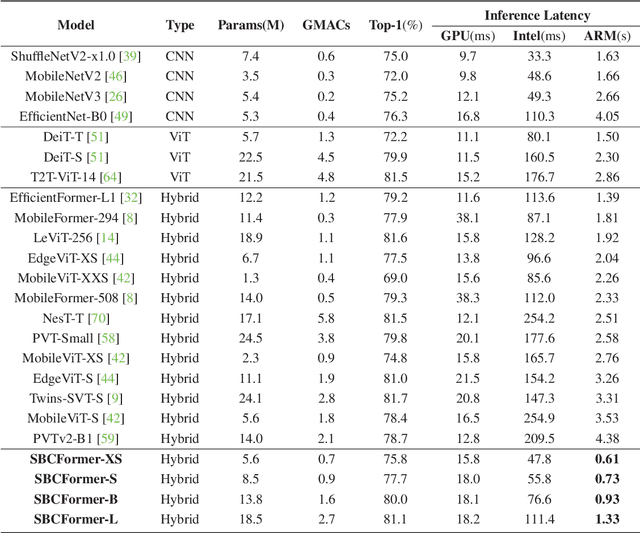
Computer vision has become increasingly prevalent in solving real-world problems across diverse domains, including smart agriculture, fishery, and livestock management. These applications may not require processing many image frames per second, leading practitioners to use single board computers (SBCs). Although many lightweight networks have been developed for mobile/edge devices, they primarily target smartphones with more powerful processors and not SBCs with the low-end CPUs. This paper introduces a CNN-ViT hybrid network called SBCFormer, which achieves high accuracy and fast computation on such low-end CPUs. The hardware constraints of these CPUs make the Transformer's attention mechanism preferable to convolution. However, using attention on low-end CPUs presents a challenge: high-resolution internal feature maps demand excessive computational resources, but reducing their resolution results in the loss of local image details. SBCFormer introduces an architectural design to address this issue. As a result, SBCFormer achieves the highest trade-off between accuracy and speed on a Raspberry Pi 4 Model B with an ARM-Cortex A72 CPU. For the first time, it achieves an ImageNet-1K top-1 accuracy of around 80% at a speed of 1.0 frame/sec on the SBC. Code is available at https://github.com/xyongLu/SBCFormer.
* 11 pages, 2 figures, WACV2024
Clairvoyance: Intelligent Route Planning for Electric Buses Based on Urban Big Data
Dec 09, 2021Nowadays many cities around the world have introduced electric buses to optimize urban traffic and reduce local carbon emissions. In order to cut carbon emissions and maximize the utility of electric buses, it is important to choose suitable routes for them. Traditionally, route selection is on the basis of dedicated surveys, which are costly in time and labor. In this paper, we mainly focus attention on planning electric bus routes intelligently, depending on the unique needs of each region throughout the city. We propose Clairvoyance, a route planning system that leverages a deep neural network and a multilayer perceptron to predict the future people's trips and the future transportation carbon emission in the whole city, respectively. Given the future information of people's trips and transportation carbon emission, we utilize a greedy mechanism to recommend bus routes for electric buses that will depart in an ideal state. Furthermore, representative features of the two neural networks are extracted from the heterogeneous urban datasets. We evaluate our approach through extensive experiments on real-world data sources in Zhuhai, China. The results show that our designed neural network-based algorithms are consistently superior to the typical baselines. Additionally, the recommended routes for electric buses are helpful in reducing the peak value of carbon emissions and making full use of electric buses in the city.
Boosting Light-Weight Depth Estimation Via Knowledge Distillation
May 13, 2021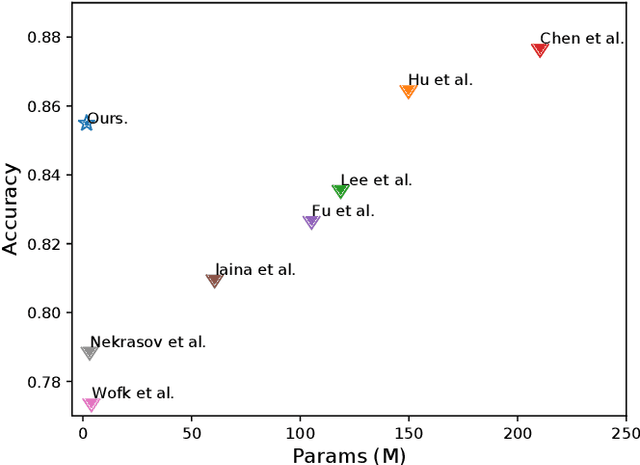

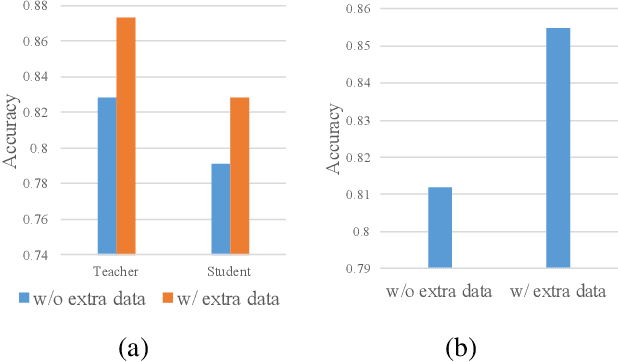
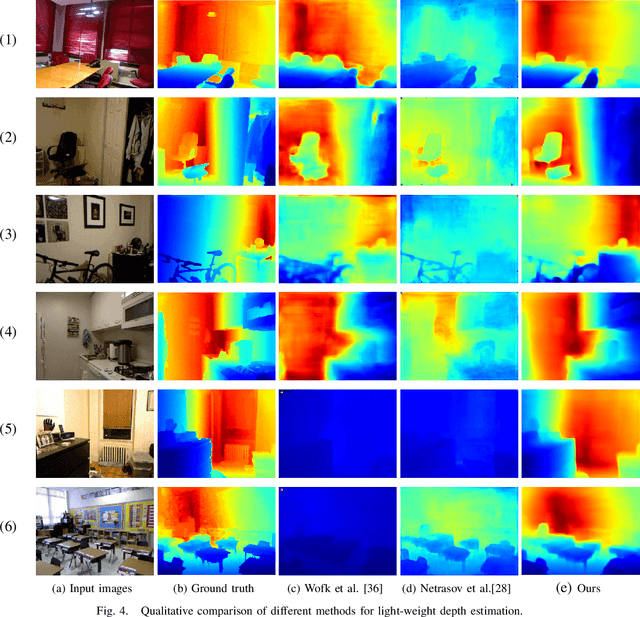
The advanced performance of depth estimation is achieved by the employment of large and complex neural networks. While the performance has still been continuously improved, we argue that the depth estimation has to be accurate and efficient. It's a preliminary requirement for real-world applications. However, fast depth estimation tends to lower the performance as the trade-off between the model's capacity and accuracy. In this paper, we attempt to archive highly accurate depth estimation with a light-weight network. To this end, we first introduce a compact network that can estimate a depth map in real-time. We then technically show two complementary and necessary strategies to improve the performance of the light-weight network. As the number of real-world scenes is infinite, the first is the employment of auxiliary data that increases the diversity of training data. The second is the use of knowledge distillation to further boost the performance. Through extensive and rigorous experiments, we show that our method outperforms previous light-weight methods in terms of inference accuracy, computational efficiency and generalization. We can achieve comparable performance compared to state-of-the-of-art methods with only 1% parameters, on the other hand, our method outperforms other light-weight methods by a significant margin.