 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooping Back to Move Forward: Recursive Transformers for Efficient and Flexible Large Multimodal Models
Feb 09, 2026Large Multimodal Models (LMMs) have achieved remarkable success in vision-language tasks, yet their vast parameter counts are often underutilized during both training and inference. In this work, we embrace the idea of looping back to move forward: reusing model parameters through recursive refinement to extract stronger multimodal representations without increasing model size. We propose RecursiveVLM, a recursive Transformer architecture tailored for LMMs. Two key innovations enable effective looping: (i) a Recursive Connector that aligns features across recursion steps by fusing intermediate-layer hidden states and applying modality-specific projections, respecting the distinct statistical structures of vision and language tokens; (ii) a Monotonic Recursion Loss that supervises every step and guarantees performance improves monotonically with recursion depth. This design transforms recursion into an on-demand refinement mechanism: delivering strong results with few loops on resource-constrained devices and progressively improving outputs when more computation resources are available. Experiments show consistent gains of +3% over standard Transformers and +7% over vanilla recursive baselines, demonstrating that strategic looping is a powerful path toward efficient, deployment-adaptive LMMs.
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
Feb 15, 2024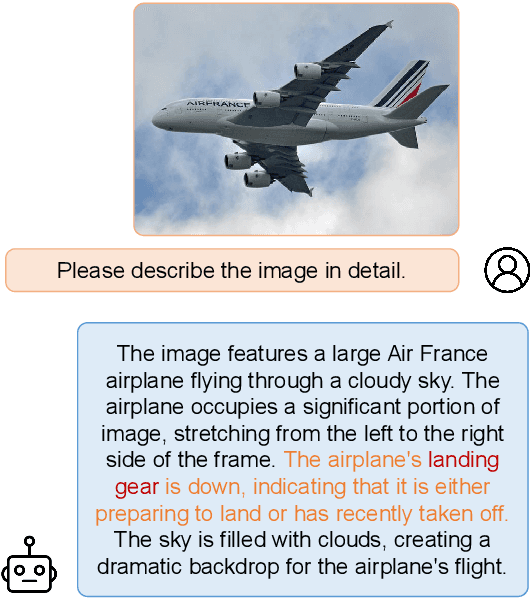
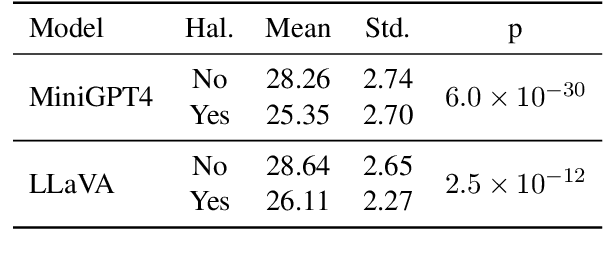
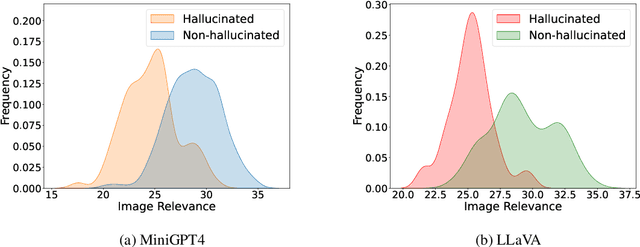

Multimodal large language models (MLLMs) have attracted increasing attention in the past few years, but they may still generate descriptions that include objects not present in the corresponding images, a phenomenon known as object hallucination. To eliminate hallucinations, existing methods manually annotate paired responses with and without hallucinations, and then employ various alignment algorithms to improve the alignment capability between images and text. However, they not only demand considerable computation resources during the finetuning stage but also require expensive human annotation to construct paired data needed by the alignment algorithms. To address these issues, we borrow the idea of unlearning and propose an efficient fine-grained unlearning framework (EFUF), which can eliminate hallucinations without the need for paired data. Extensive experiments show that our method consistently reduces hallucinations while preserving the generation quality with modest computational overhead. Our code and datasets will be publicly available.