 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models Can Self-Improve Reasoning via Reflection
Oct 30, 2024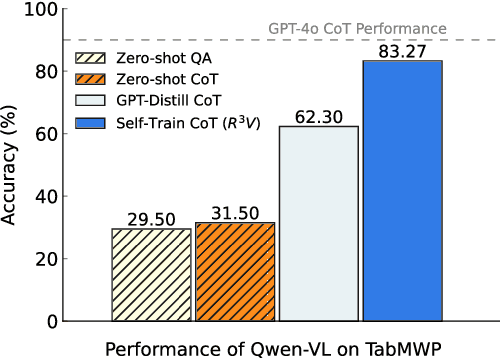
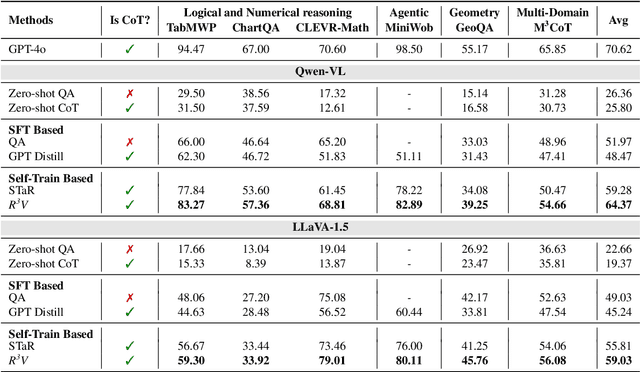
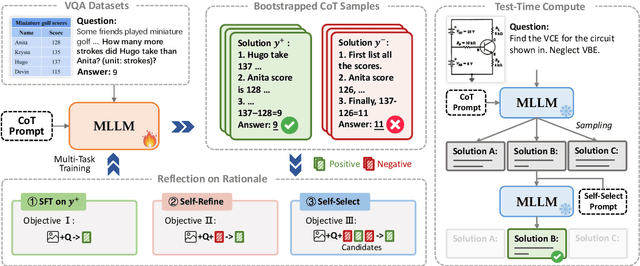
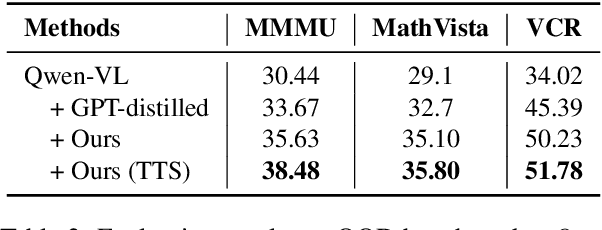
Chain-of-thought (CoT) has proven to improve the reasoning capability of large language models (LLMs). However, due to the complexity of multimodal scenarios and the difficulty in collecting high-quality CoT data, CoT reasoning in multimodal LLMs has been largely overlooked. To this end, we propose a simple yet effective self-training framework, R3V, which iteratively enhances the model's Vision-language Reasoning by Reflecting on CoT Rationales. Our framework consists of two interleaved parts: (1) iteratively bootstrapping positive and negative solutions for reasoning datasets, and (2) reflection on rationale for learning from mistakes. Specifically, we introduce the self-refine and self-select losses, enabling the model to refine flawed rationale and derive the correct answer by comparing rationale candidates. Experiments on a wide range of vision-language tasks show that R3V consistently improves multimodal LLM reasoning, achieving a relative improvement of 23 to 60 percent over GPT-distilled baselines. Additionally, our approach supports self-reflection on generated solutions, further boosting performance through test-time computation.
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents
Jan 17, 2024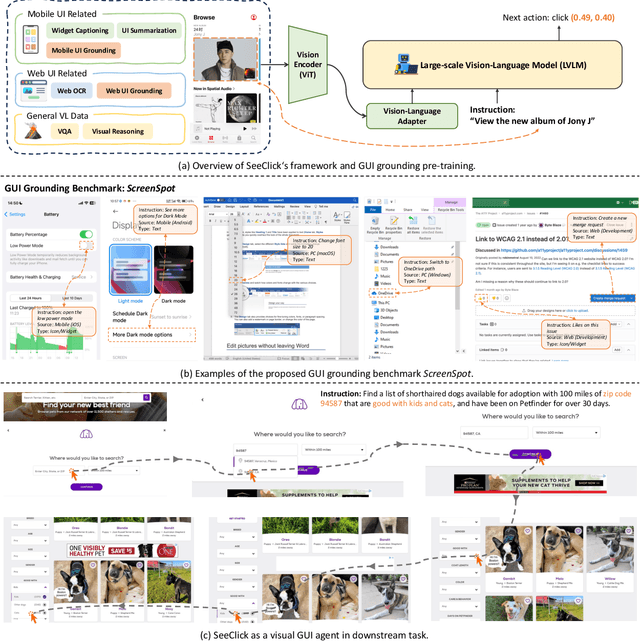
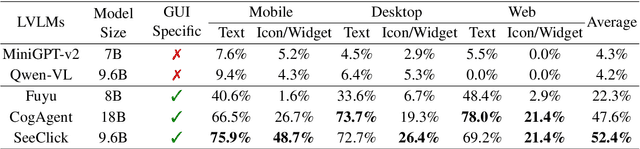
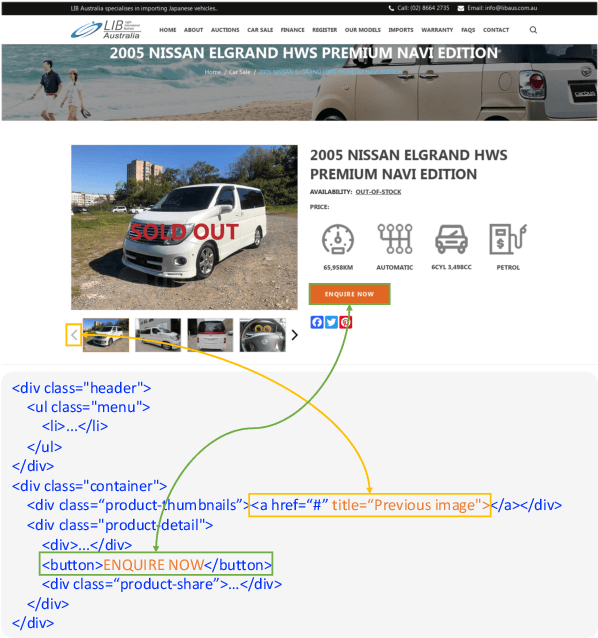
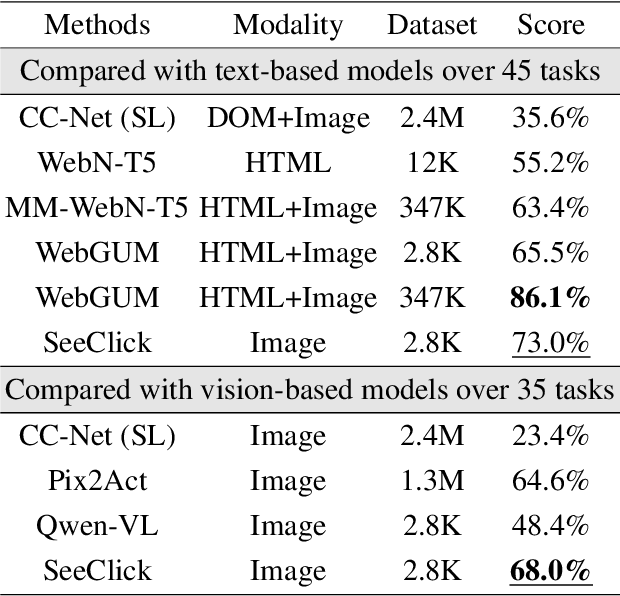
Graphical User Interface (GUI) agents are designed to automate complex tasks on digital devices, such as smartphones and desktops. Most existing GUI agents interact with the environment through extracted structured data, which can be notably lengthy (e.g., HTML) and occasionally inaccessible (e.g., on desktops). To alleviate this issue, we propose a visual GUI agent -- SeeClick, which only relies on screenshots for task automation. In our preliminary study, we have discovered a key challenge in developing visual GUI agents: GUI grounding -- the capacity to accurately locate screen elements based on instructions. To tackle this challenge, we propose to enhance SeeClick with GUI grounding pre-training and devise a method to automate the curation of GUI grounding data. Along with the efforts above, we have also created ScreenSpot, the first realistic GUI grounding dataset that encompasses mobile, desktop, and web environments. After pre-training, SeeClick demonstrates significant improvement in ScreenSpot over various baselines. Moreover, comprehensive evaluations on three widely used benchmarks consistently support our finding that advancements in GUI grounding directly correlate with enhanced performance in downstream GUI agent tasks. The model, data and code are available at https://github.com/njucckevin/SeeClick.