 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Relation Extraction: Beyond Shortcuts to Generalization with a Debiased Benchmark
Jan 02, 2025



Benchmarks are crucial for evaluating machine learning algorithm performance, facilitating comparison and identifying superior solutions. However, biases within datasets can lead models to learn shortcut patterns, resulting in inaccurate assessments and hindering real-world applicability. This paper addresses the issue of entity bias in relation extraction tasks, where models tend to rely on entity mentions rather than context. We propose a debiased relation extraction benchmark DREB that breaks the pseudo-correlation between entity mentions and relation types through entity replacement. DREB utilizes Bias Evaluator and PPL Evaluator to ensure low bias and high naturalness, providing a reliable and accurate assessment of model generalization in entity bias scenarios. To establish a new baseline on DREB, we introduce MixDebias, a debiasing method combining data-level and model training-level techniques. MixDebias effectively improves model performance on DREB while maintaining performance on the original dataset. Extensive experiments demonstrate the effectiveness and robustness of MixDebias compared to existing methods, highlighting its potential for improving the generalization ability of relation extraction models. We will release DREB and MixDebias publicly.
MixRED: A Mix-lingual Relation Extraction Dataset
Mar 23, 2024
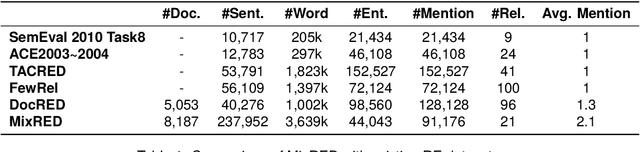
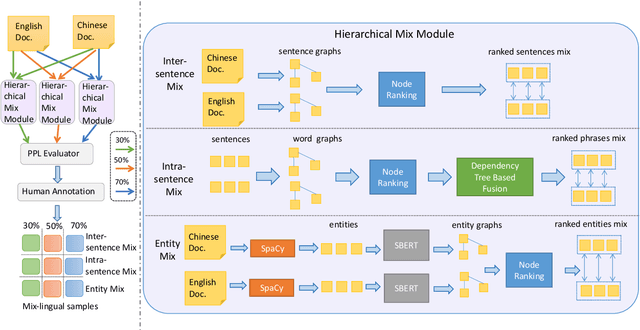
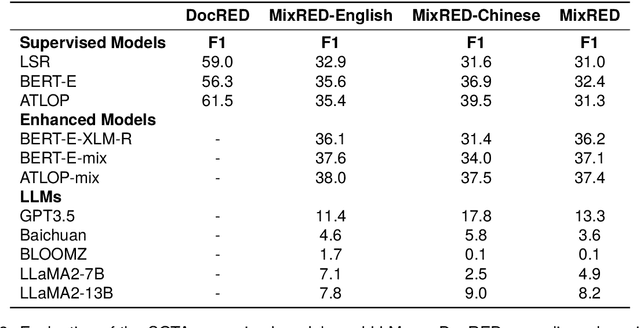
Relation extraction is a critical task in the field of natural language processing with numerous real-world applications. Existing research primarily focuses on monolingual relation extraction or cross-lingual enhancement for relation extraction. Yet, there remains a significant gap in understanding relation extraction in the mix-lingual (or code-switching) scenario, where individuals intermix contents from different languages within sentences, generating mix-lingual content. Due to the lack of a dedicated dataset, the effectiveness of existing relation extraction models in such a scenario is largely unexplored. To address this issue, we introduce a novel task of considering relation extraction in the mix-lingual scenario called MixRE and constructing the human-annotated dataset MixRED to support this task. In addition to constructing the MixRED dataset, we evaluate both state-of-the-art supervised models and large language models (LLMs) on MixRED, revealing their respective advantages and limitations in the mix-lingual scenario. Furthermore, we delve into factors influencing model performance within the MixRE task and uncover promising directions for enhancing the performance of both supervised models and LLMs in this novel task.
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents
Jan 17, 2024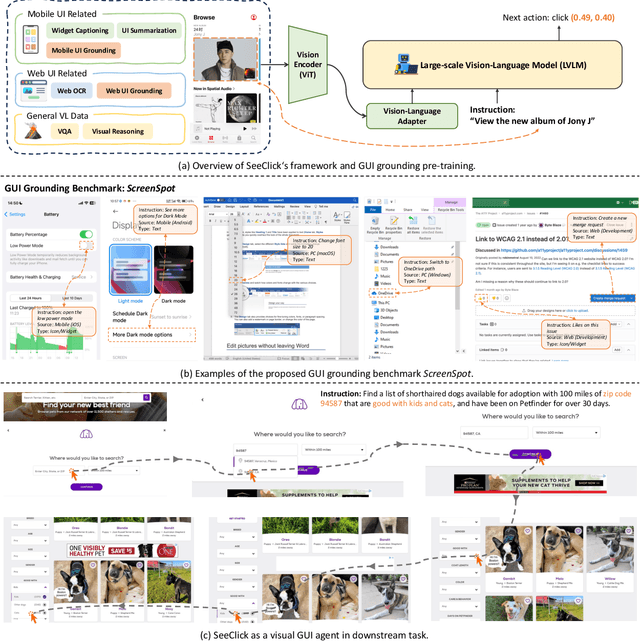
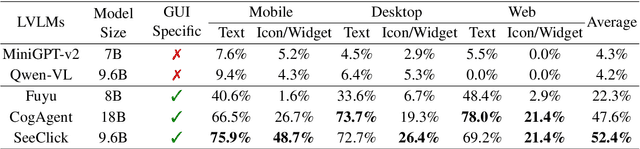
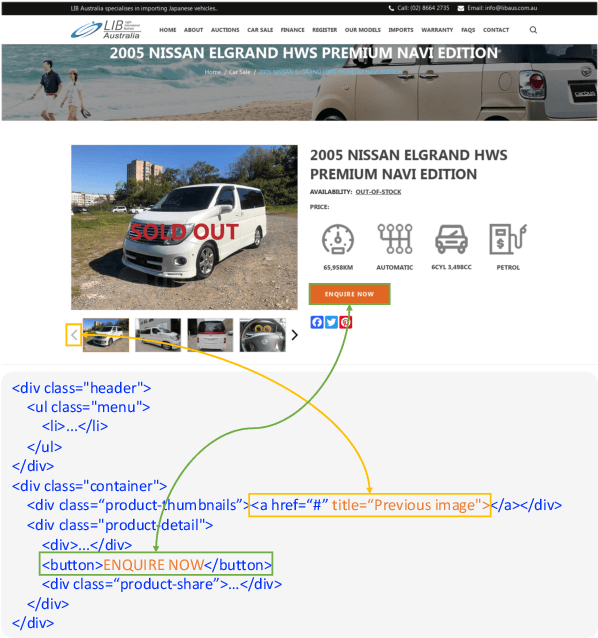
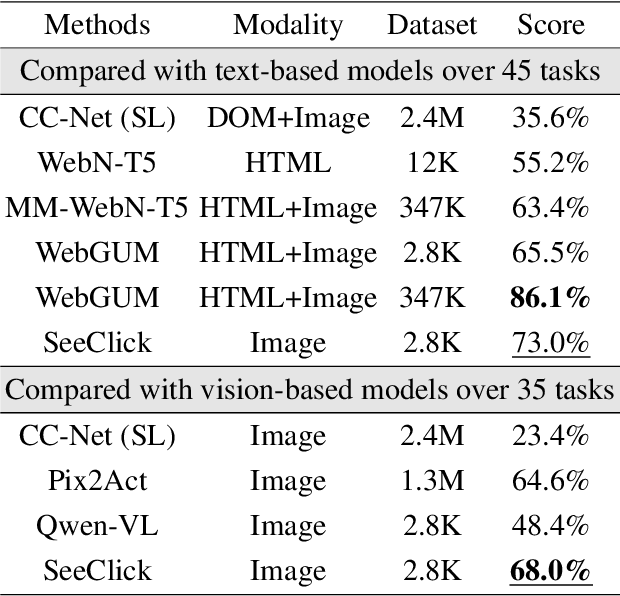
Graphical User Interface (GUI) agents are designed to automate complex tasks on digital devices, such as smartphones and desktops. Most existing GUI agents interact with the environment through extracted structured data, which can be notably lengthy (e.g., HTML) and occasionally inaccessible (e.g., on desktops). To alleviate this issue, we propose a visual GUI agent -- SeeClick, which only relies on screenshots for task automation. In our preliminary study, we have discovered a key challenge in developing visual GUI agents: GUI grounding -- the capacity to accurately locate screen elements based on instructions. To tackle this challenge, we propose to enhance SeeClick with GUI grounding pre-training and devise a method to automate the curation of GUI grounding data. Along with the efforts above, we have also created ScreenSpot, the first realistic GUI grounding dataset that encompasses mobile, desktop, and web environments. After pre-training, SeeClick demonstrates significant improvement in ScreenSpot over various baselines. Moreover, comprehensive evaluations on three widely used benchmarks consistently support our finding that advancements in GUI grounding directly correlate with enhanced performance in downstream GUI agent tasks. The model, data and code are available at https://github.com/njucckevin/SeeClick.