 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRED: A Mix-lingual Relation Extraction Dataset
Paper and Code

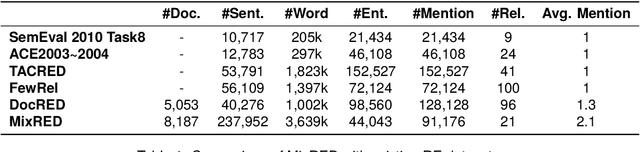
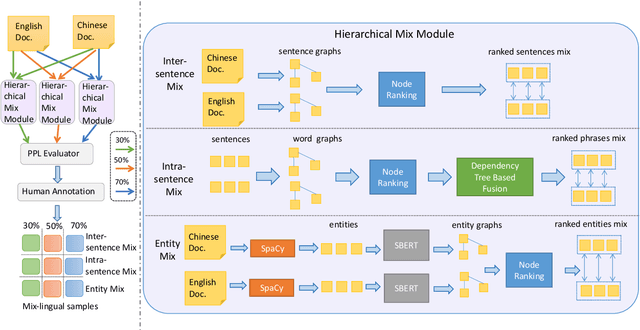
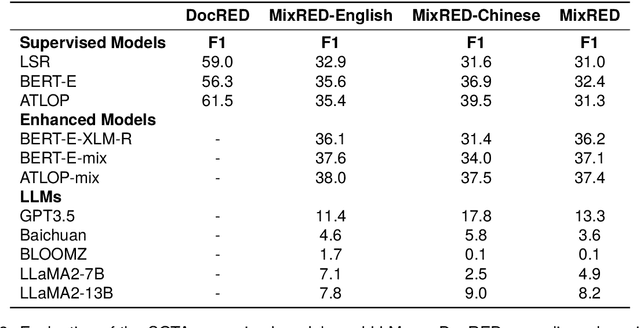
Relation extraction is a critical task in the field of natural language processing with numerous real-world applications. Existing research primarily focuses on monolingual relation extraction or cross-lingual enhancement for relation extraction. Yet, there remains a significant gap in understanding relation extraction in the mix-lingual (or code-switching) scenario, where individuals intermix contents from different languages within sentences, generating mix-lingual content. Due to the lack of a dedicated dataset, the effectiveness of existing relation extraction models in such a scenario is largely unexplored. To address this issue, we introduce a novel task of considering relation extraction in the mix-lingual scenario called MixRE and constructing the human-annotated dataset MixRED to support this task. In addition to constructing the MixRED dataset, we evaluate both state-of-the-art supervised models and large language models (LLMs) on MixRED, revealing their respective advantages and limitations in the mix-lingual scenario. Furthermore, we delve into factors influencing model performance within the MixRE task and uncover promising directions for enhancing the performance of both supervised models and LLMs in this novel task.