 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgebraic Robustness Verification of Neural Networks
Feb 05, 2026We formulate formal robustness verification of neural networks as an algebraic optimization problem. We leverage the Euclidean Distance (ED) degree, which is the generic number of complex critical points of the distance minimization problem to a classifier's decision boundary, as an architecture-dependent measure of the intrinsic complexity of robustness verification. To make this notion operational, we define the associated ED discriminant, which characterizes input points at which the number of real critical points changes, distinguishing test instances that are easier or harder to verify. We provide an explicit algorithm for computing this discriminant. We further introduce the parameter discriminant of a neural network, identifying parameters where the ED degree drops and the decision boundary exhibits reduced algebraic complexity. We derive closed-form expressions for the ED degree for several classes of neural architectures, as well as formulas for the expected number of real critical points in the infinite-width limit. Finally, we present an exact robustness certification algorithm based on numerical homotopy continuation, establishing a concrete link between metric algebraic geometry and neural network verification.
Constraining the outputs of ReLU neural networks
Aug 05, 2025We introduce a class of algebraic varieties naturally associated with ReLU neural networks, arising from the piecewise linear structure of their outputs across activation regions in input space, and the piecewise multilinear structure in parameter space. By analyzing the rank constraints on the network outputs within each activation region, we derive polynomial equations that characterize the functions representable by the network. We further investigate conditions under which these varieties attain their expected dimension, providing insight into the expressive and structural properties of ReLU networks.
Understanding Learning Invariance in Deep Linear Networks
Jun 16, 2025Equivariant and invariant machine learning models exploit symmetries and structural patterns in data to improve sample efficiency. While empirical studies suggest that data-driven methods such as regularization and data augmentation can perform comparably to explicitly invariant models, theoretical insights remain scarce. In this paper, we provide a theoretical comparison of three approaches for achieving invariance: data augmentation, regularization, and hard-wiring. We focus on mean squared error regression with deep linear networks, which parametrize rank-bounded linear maps and can be hard-wired to be invariant to specific group actions. We show that the critical points of the optimization problems for hard-wiring and data augmentation are identical, consisting solely of saddles and the global optimum. By contrast, regularization introduces additional critical points, though they remain saddles except for the global optimum. Moreover, we demonstrate that the regularization path is continuous and converges to the hard-wired solution.
Demystifying Topological Message-Passing with Relational Structures: A Case Study on Oversquashing in Simplicial Message-Passing
Jun 06, 2025Topological deep learning (TDL) has emerged as a powerful tool for modeling higher-order interactions in relational data. However, phenomena such as oversquashing in topological message-passing remain understudied and lack theoretical analysis. We propose a unifying axiomatic framework that bridges graph and topological message-passing by viewing simplicial and cellular complexes and their message-passing schemes through the lens of relational structures. This approach extends graph-theoretic results and algorithms to higher-order structures, facilitating the analysis and mitigation of oversquashing in topological message-passing networks. Through theoretical analysis and empirical studies on simplicial networks, we demonstrate the potential of this framework to advance TDL.
Implicit Bias of Mirror Descent for Shallow Neural Networks in Univariate Regression
Oct 05, 2024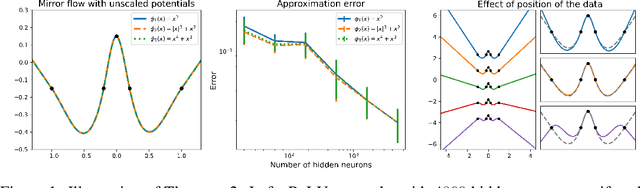
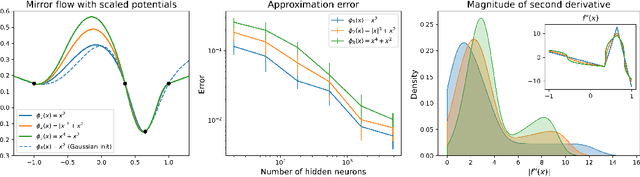
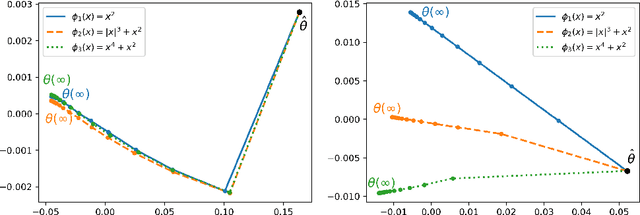
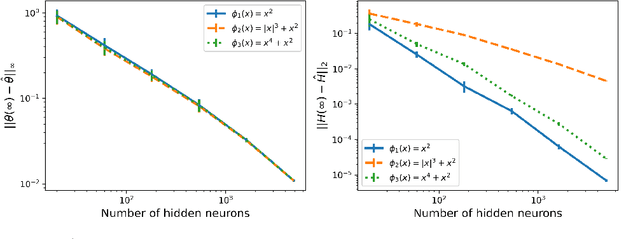
We examine the implicit bias of mirror flow in univariate least squares error regression with wide and shallow neural networks. For a broad class of potential functions, we show that mirror flow exhibits lazy training and has the same implicit bias as ordinary gradient flow when the network width tends to infinity. For ReLU networks, we characterize this bias through a variational problem in function space. Our analysis includes prior results for ordinary gradient flow as a special case and lifts limitations which required either an intractable adjustment of the training data or networks with skip connections. We further introduce scaled potentials and show that for these, mirror flow still exhibits lazy training but is not in the kernel regime. For networks with absolute value activations, we show that mirror flow with scaled potentials induces a rich class of biases, which generally cannot be captured by an RKHS norm. A takeaway is that whereas the parameter initialization determines how strongly the curvature of the learned function is penalized at different locations of the input space, the scaled potential determines how the different magnitudes of the curvature are penalized.
Bounds for the smallest eigenvalue of the NTK for arbitrary spherical data of arbitrary dimension
May 23, 2024Bounds on the smallest eigenvalue of the neural tangent kernel (NTK) are a key ingredient in the analysis of neural network optimization and memorization. However, existing results require distributional assumptions on the data and are limited to a high-dimensional setting, where the input dimension $d_0$ scales at least logarithmically in the number of samples $n$. In this work we remove both of these requirements and instead provide bounds in terms of a measure of the collinearity of the data: notably these bounds hold with high probability even when $d_0$ is held constant versus $n$. We prove our results through a novel application of the hemisphere transform.
Fisher-Rao Gradient Flows of Linear Programs and State-Action Natural Policy Gradients
Mar 28, 2024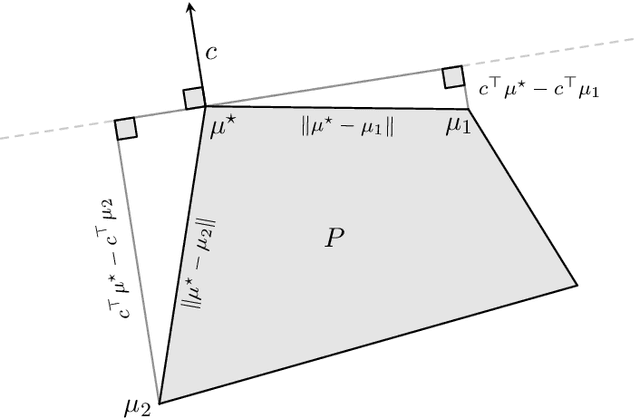
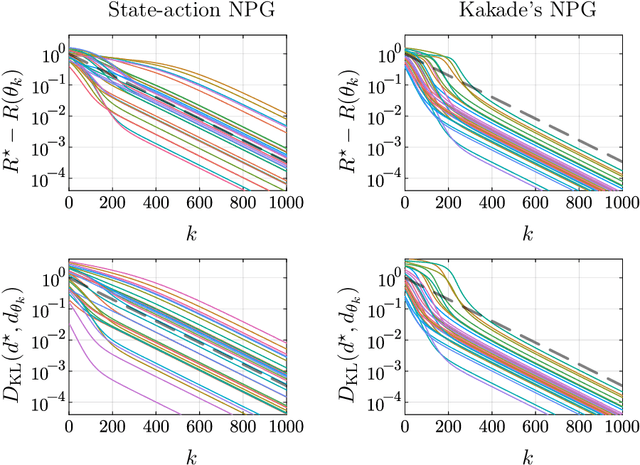
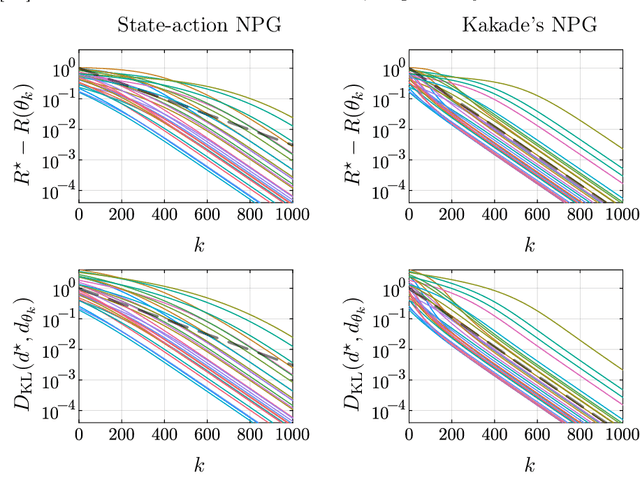
Kakade's natural policy gradient method has been studied extensively in the last years showing linear convergence with and without regularization. We study another natural gradient method which is based on the Fisher information matrix of the state-action distributions and has received little attention from the theoretical side. Here, the state-action distributions follow the Fisher-Rao gradient flow inside the state-action polytope with respect to a linear potential. Therefore, we study Fisher-Rao gradient flows of linear programs more generally and show linear convergence with a rate that depends on the geometry of the linear program. Equivalently, this yields an estimate on the error induced by entropic regularization of the linear program which improves existing results. We extend these results and show sublinear convergence for perturbed Fisher-Rao gradient flows and natural gradient flows up to an approximation error. In particular, these general results cover the case of state-action natural policy gradients.
The Real Tropical Geometry of Neural Networks
Mar 18, 2024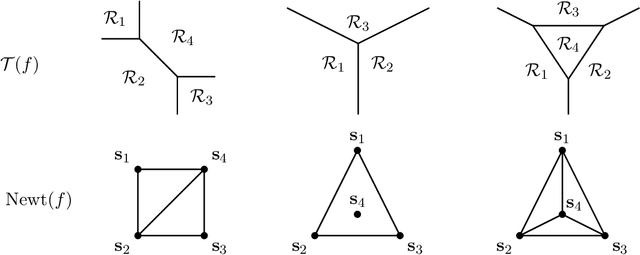
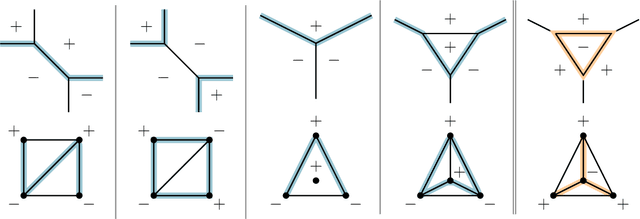
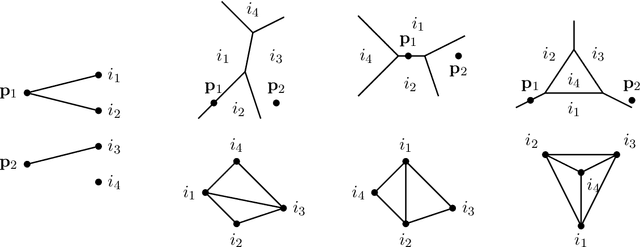
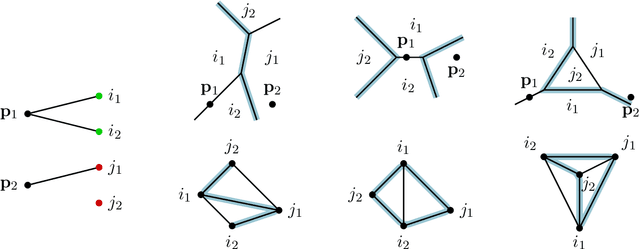
We consider a binary classifier defined as the sign of a tropical rational function, that is, as the difference of two convex piecewise linear functions. The parameter space of ReLU neural networks is contained as a semialgebraic set inside the parameter space of tropical rational functions. We initiate the study of two different subdivisions of this parameter space: a subdivision into semialgebraic sets, on which the combinatorial type of the decision boundary is fixed, and a subdivision into a polyhedral fan, capturing the combinatorics of the partitions of the dataset. The sublevel sets of the 0/1-loss function arise as subfans of this classification fan, and we show that the level-sets are not necessarily connected. We describe the classification fan i) geometrically, as normal fan of the activation polytope, and ii) combinatorially through a list of properties of associated bipartite graphs, in analogy to covector axioms of oriented matroids and tropical oriented matroids. Our findings extend and refine the connection between neural networks and tropical geometry by observing structures established in real tropical geometry, such as positive tropicalizations of hypersurfaces and tropical semialgebraic sets.
Benign overfitting in leaky ReLU networks with moderate input dimension
Mar 11, 2024The problem of benign overfitting asks whether it is possible for a model to perfectly fit noisy training data and still generalize well. We study benign overfitting in two-layer leaky ReLU networks trained with the hinge loss on a binary classification task. We consider input data which can be decomposed into the sum of a common signal and a random noise component, which lie on subspaces orthogonal to one another. We characterize conditions on the signal to noise ratio (SNR) of the model parameters giving rise to benign versus non-benign, or harmful, overfitting: in particular, if the SNR is high then benign overfitting occurs, conversely if the SNR is low then harmful overfitting occurs. We attribute both benign and non-benign overfitting to an approximate margin maximization property and show that leaky ReLU networks trained on hinge loss with Gradient Descent (GD) satisfy this property. In contrast to prior work we do not require near orthogonality conditions on the training data: notably, for input dimension $d$ and training sample size $n$, while prior work shows asymptotically optimal error when $d = \Omega(n^2 \log n)$, here we require only $d = \Omega\left(n \log \frac{1}{\epsilon}\right)$ to obtain error within $\epsilon$ of optimal.
Mildly Overparameterized ReLU Networks Have a Favorable Loss Landscape
May 31, 2023We study the loss landscape of two-layer mildly overparameterized ReLU neural networks on a generic finite input dataset for the squared error loss. Our approach involves bounding the dimension of the sets of local and global minima using the rank of the Jacobian of the parameterization map. Using results on random binary matrices, we show most activation patterns correspond to parameter regions with no bad differentiable local minima. Furthermore, for one-dimensional input data, we show most activation regions realizable by the network contain a high dimensional set of global minima and no bad local minima. We experimentally confirm these results by finding a phase transition from most regions having full rank to many regions having deficient rank depending on the amount of overparameterization.