 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying the network backward: A Game Theoretic Attribution Framework
May 07, 2026Attribution methods explain which input features drive a model's prediction, making them central to model debugging and mechanistic interpretability. Yet backward attribution methods, including gradients, LRP, and transformer-specific rules, lack a shared framework in which to compare the underlying backward calculations. We introduce such a framework by recasting backward attribution as a two-player game on an extended network graph, building on Gaubert and Vlassopoulos' ReLU Net Game. Gradients and the full alpha-beta-LRP family arise as integrals over game trajectories under specific equilibria, so attribution maps become projections of trajectory distributions rather than the primary object. Desired explanation properties, such as localisation focus, robustness to input noise, or stable attention routing, can be specified as game-theoretic concepts, including policy regularization, risk aversion, and extended action sets, and translate directly into novel adaptations of the well-known backward rules. On ViT-B/16, one such selected adaptation of alpha-beta-LRP outperforms prior transformer-specific backward methods across all considered localisation metrics.
Hidden Monotonicity: Explaining Deep Neural Networks via their DC Decomposition
Jan 12, 2026It has been demonstrated in various contexts that monotonicity leads to better explainability in neural networks. However, not every function can be well approximated by a monotone neural network. We demonstrate that monotonicity can still be used in two ways to boost explainability. First, we use an adaptation of the decomposition of a trained ReLU network into two monotone and convex parts, thereby overcoming numerical obstacles from an inherent blowup of the weights in this procedure. Our proposed saliency methods -- SplitCAM and SplitLRP -- improve on state of the art results on both VGG16 and Resnet18 networks on ImageNet-S across all Quantus saliency metric categories. Second, we exhibit that training a model as the difference between two monotone neural networks results in a system with strong self-explainability properties.
Depth-Bounds for Neural Networks via the Braid Arrangement
Feb 13, 2025We contribute towards resolving the open question of how many hidden layers are required in ReLU networks for exactly representing all continuous and piecewise linear functions on $\mathbb{R}^d$. While the question has been resolved in special cases, the best known lower bound in general is still 2. We focus on neural networks that are compatible with certain polyhedral complexes, more precisely with the braid fan. For such neural networks, we prove a non-constant lower bound of $\Omega(\log\log d)$ hidden layers required to exactly represent the maximum of $d$ numbers. Additionally, under our assumption, we provide a combinatorial proof that 3 hidden layers are necessary to compute the maximum of 5 numbers; this had only been verified with an excessive computation so far. Finally, we show that a natural generalization of the best known upper bound to maxout networks is not tight, by demonstrating that a rank-3 maxout layer followed by a rank-2 maxout layer is sufficient to represent the maximum of 7 numbers.
Neural Networks and (Virtual) Extended Formulations
Nov 05, 2024Neural networks with piecewise linear activation functions, such as rectified linear units (ReLU) or maxout, are among the most fundamental models in modern machine learning. We make a step towards proving lower bounds on the size of such neural networks by linking their representative capabilities to the notion of the extension complexity $\mathrm{xc}(P)$ of a polytope $P$, a well-studied quantity in combinatorial optimization and polyhedral geometry. To this end, we propose the notion of virtual extension complexity $\mathrm{vxc}(P)=\min\{\mathrm{xc}(Q)+\mathrm{xc}(R)\mid P+Q=R\}$. This generalizes $\mathrm{xc}(P)$ and describes the number of inequalities needed to represent the linear optimization problem over $P$ as a difference of two linear programs. We prove that $\mathrm{vxc}(P)$ is a lower bound on the size of a neural network that optimizes over $P$. While it remains open to derive strong lower bounds on virtual extension complexity, we show that powerful results on the ordinary extension complexity can be converted into lower bounds for monotone neural networks, that is, neural networks with only nonnegative weights. Furthermore, we show that one can efficiently optimize over a polytope $P$ using a small virtual extended formulation. We therefore believe that virtual extension complexity deserves to be studied independently from neural networks, just like the ordinary extension complexity. As a first step in this direction, we derive an example showing that extension complexity can go down under Minkowski sum.
The Real Tropical Geometry of Neural Networks
Mar 18, 2024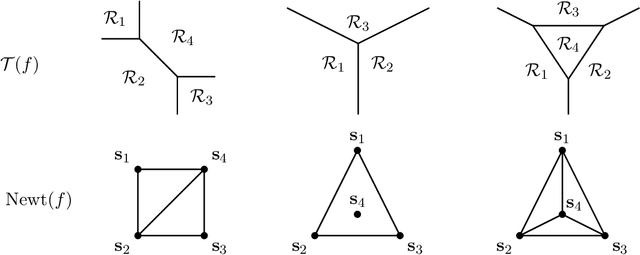
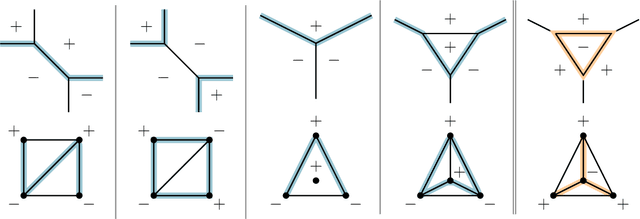
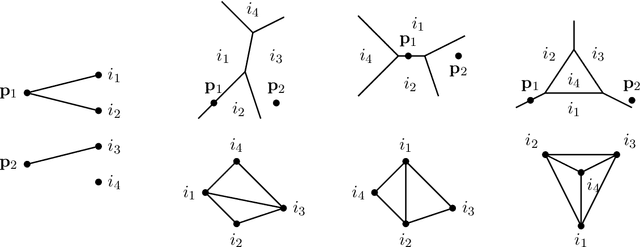
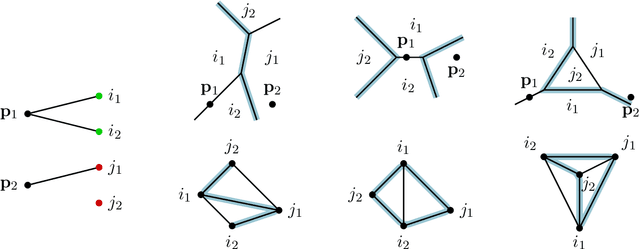
We consider a binary classifier defined as the sign of a tropical rational function, that is, as the difference of two convex piecewise linear functions. The parameter space of ReLU neural networks is contained as a semialgebraic set inside the parameter space of tropical rational functions. We initiate the study of two different subdivisions of this parameter space: a subdivision into semialgebraic sets, on which the combinatorial type of the decision boundary is fixed, and a subdivision into a polyhedral fan, capturing the combinatorics of the partitions of the dataset. The sublevel sets of the 0/1-loss function arise as subfans of this classification fan, and we show that the level-sets are not necessarily connected. We describe the classification fan i) geometrically, as normal fan of the activation polytope, and ii) combinatorially through a list of properties of associated bipartite graphs, in analogy to covector axioms of oriented matroids and tropical oriented matroids. Our findings extend and refine the connection between neural networks and tropical geometry by observing structures established in real tropical geometry, such as positive tropicalizations of hypersurfaces and tropical semialgebraic sets.
Lower Bounds on the Depth of Integral ReLU Neural Networks via Lattice Polytopes
Feb 24, 2023We prove that the set of functions representable by ReLU neural networks with integer weights strictly increases with the network depth while allowing arbitrary width. More precisely, we show that $\lceil\log_2(n)\rceil$ hidden layers are indeed necessary to compute the maximum of $n$ numbers, matching known upper bounds. Our results are based on the known duality between neural networks and Newton polytopes via tropical geometry. The integrality assumption implies that these Newton polytopes are lattice polytopes. Then, our depth lower bounds follow from a parity argument on the normalized volume of faces of such polytopes.