 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Single Image Super-Resolution with Entropy Attention and Receptive Field Augmentation
Aug 08, 2024
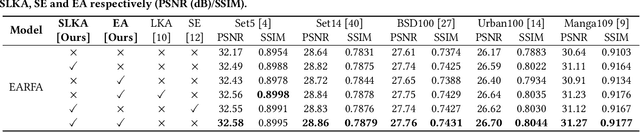

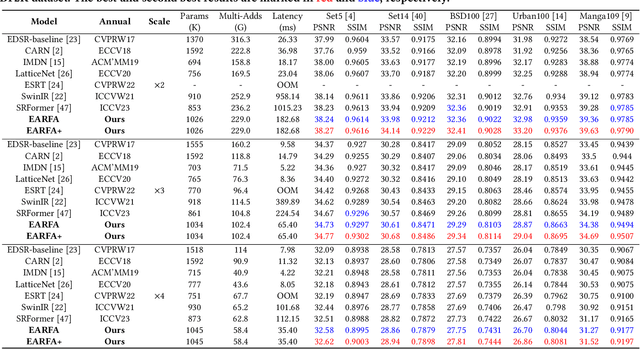
Transformer-based deep models for single image super-resolution (SISR) have greatly improved the performance of lightweight SISR tasks in recent years. However, they often suffer from heavy computational burden and slow inference due to the complex calculation of multi-head self-attention (MSA), seriously hindering their practical application and deployment. In this work, we present an efficient SR model to mitigate the dilemma between model efficiency and SR performance, which is dubbed Entropy Attention and Receptive Field Augmentation network (EARFA), and composed of a novel entropy attention (EA) and a shifting large kernel attention (SLKA). From the perspective of information theory, EA increases the entropy of intermediate features conditioned on a Gaussian distribution, providing more informative input for subsequent reasoning. On the other hand, SLKA extends the receptive field of SR models with the assistance of channel shifting, which also favors to boost the diversity of hierarchical features. Since the implementation of EA and SLKA does not involve complex computations (such as extensive matrix multiplications), the proposed method can achieve faster nonlinear inference than Transformer-based SR models while maintaining better SR performance. Extensive experiments show that the proposed model can significantly reduce the delay of model inference while achieving the SR performance comparable with other advanced models.
Large Kernel Distillation Network for Efficient Single Image Super-Resolution
Jul 19, 2024Efficient and lightweight single-image super-resolution (SISR) has achieved remarkable performance in recent years. One effective approach is the use of large kernel designs, which have been shown to improve the performance of SISR models while reducing their computational requirements. However, current state-of-the-art (SOTA) models still face problems such as high computational costs. To address these issues, we propose the Large Kernel Distillation Network (LKDN) in this paper. Our approach simplifies the model structure and introduces more efficient attention modules to reduce computational costs while also improving performance. Specifically, we employ the reparameterization technique to enhance model performance without adding extra cost. We also introduce a new optimizer from other tasks to SISR, which improves training speed and performance. Our experimental results demonstrate that LKDN outperforms existing lightweight SR methods and achieves SOTA performance.
FC$^2$N: Fully Channel-Concatenated Network for Single Image Super-Resolution
Jul 09, 2019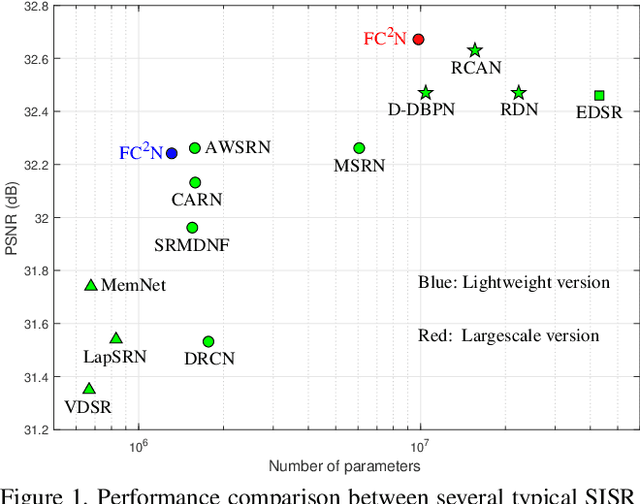

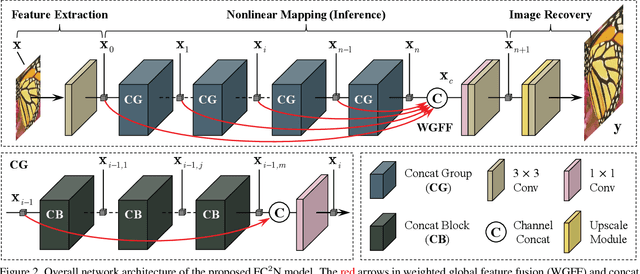
Most current image super-resolution (SR) methods based on deep convolutional neural networks (CNNs) use residual learning in network structural design, which contributes to effective back propagation, thus improving SR performance by increasing model scale. However, deep residual network suffers some redundancy in model representational capacity by introducing short paths, thus hindering the full mining of model capacity. In addition, blindly enlarging the model scale will cause more problems in model training, even with residual learning. In this work, a novel network architecture is introduced to fully exploit the representational capacity of the model, where all skip connections are implemented by weighted channel concatenation, followed by a 1$\times$1 conv layer. Based on this weighted skip connection, we construct the building modules of our model, and improve the global feature fusion (GFF). Unlike most previous models, all skip connections in our network are channel-concatenated and no residual connection is adopted. It is therefore termed as fully channel-concatenated network (FC$^2$N). Due to the full exploitation of model capacity, the proposed FC$^2$N achieves better performance than other advanced models with fewer model parameters. Extensive experiments demonstrate the superiority of our method to other methods, in terms of both quantitative metrics and visual quality.
Channel Splitting Network for Single MR Image Super-Resolution
Oct 15, 2018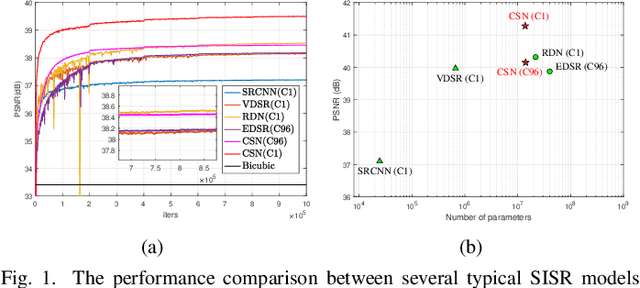

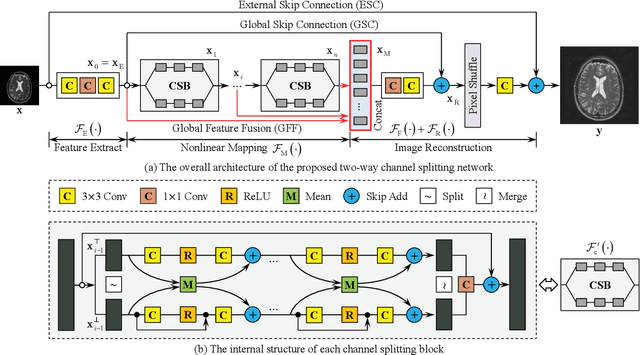

High resolution magnetic resonance (MR) imaging is desirable in many clinical applications due to its contribution to more accurate subsequent analyses and early clinical diagnoses. Single image super resolution (SISR) is an effective and cost efficient alternative technique to improve the spatial resolution of MR images. In the past few years, SISR methods based on deep learning techniques, especially convolutional neural networks (CNNs), have achieved state-of-the-art performance on natural images. However, the information is gradually weakened and training becomes increasingly difficult as the network deepens. The problem is more serious for medical images because lacking high quality and effective training samples makes deep models prone to underfitting or overfitting. Nevertheless, many current models treat the hierarchical features on different channels equivalently, which is not helpful for the models to deal with the hierarchical features discriminatively and targetedly. To this end, we present a novel channel splitting network (CSN) to ease the representational burden of deep models. The proposed CSN model divides the hierarchical features into two branches, i.e., residual branch and dense branch, with different information transmissions. The residual branch is able to promote feature reuse, while the dense branch is beneficial to the exploration of new features. Besides, we also adopt the merge-and-run mapping to facilitate information integration between different branches. Extensive experiments on various MR images, including proton density (PD), T1 and T2 images, show that the proposed CSN model achieves superior performance over other state-of-the-art SISR methods.