 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
Feb 03, 2026Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
Structured Reasoning for Large Language Models
Jan 12, 2026Large language models (LLMs) achieve strong performance by generating long chains of thought, but longer traces always introduce redundant or ineffective reasoning steps. One typical behavior is that they often perform unnecessary verification and revisions even if they have reached the correct answers. This limitation stems from the unstructured nature of reasoning trajectories and the lack of targeted supervision for critical reasoning abilities. To address this, we propose Structured Reasoning (SCR), a framework that decouples reasoning trajectories into explicit, evaluable, and trainable components. We mainly implement SCR using a Generate-Verify-Revise paradigm. Specifically, we construct structured training data and apply Dynamic Termination Supervision to guide the model in deciding when to terminate reasoning. To avoid interference between learning signals for different reasoning abilities, we adopt a progressive two-stage reinforcement learning strategy: the first stage targets initial generation and self-verification, and the second stage focuses on revision. Extensive experiments on three backbone models show that SCR substantially improves reasoning efficiency and self-verification. Besides, compared with existing reasoning paradigms, it reduces output token length by up to 50%.
FC$^2$N: Fully Channel-Concatenated Network for Single Image Super-Resolution
Jul 09, 2019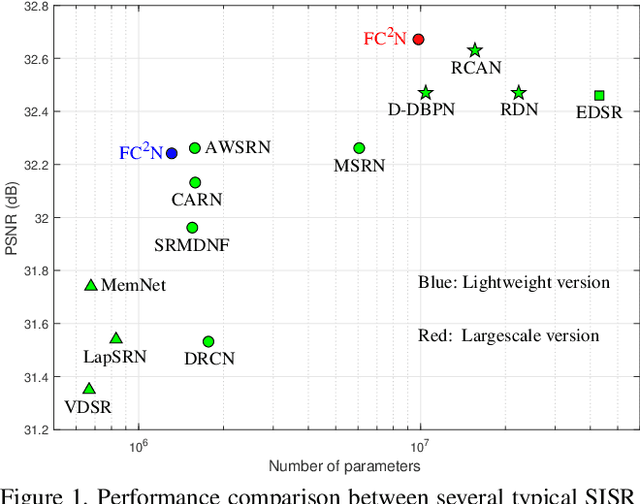

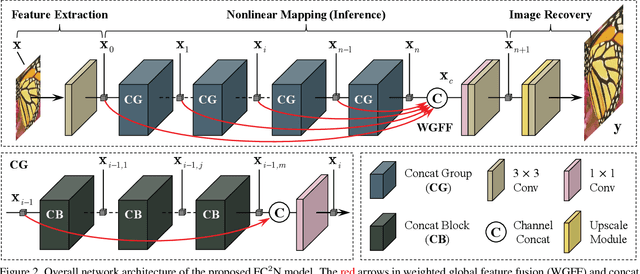
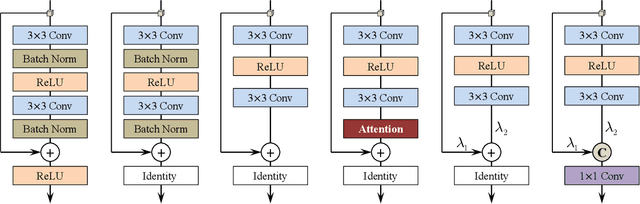
Most current image super-resolution (SR) methods based on deep convolutional neural networks (CNNs) use residual learning in network structural design, which contributes to effective back propagation, thus improving SR performance by increasing model scale. However, deep residual network suffers some redundancy in model representational capacity by introducing short paths, thus hindering the full mining of model capacity. In addition, blindly enlarging the model scale will cause more problems in model training, even with residual learning. In this work, a novel network architecture is introduced to fully exploit the representational capacity of the model, where all skip connections are implemented by weighted channel concatenation, followed by a 1$\times$1 conv layer. Based on this weighted skip connection, we construct the building modules of our model, and improve the global feature fusion (GFF). Unlike most previous models, all skip connections in our network are channel-concatenated and no residual connection is adopted. It is therefore termed as fully channel-concatenated network (FC$^2$N). Due to the full exploitation of model capacity, the proposed FC$^2$N achieves better performance than other advanced models with fewer model parameters. Extensive experiments demonstrate the superiority of our method to other methods, in terms of both quantitative metrics and visual quality.