 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Monocular Metric Depth Estimation
Jan 21, 2025Monocular Depth Estimation (MDE) is a fundamental computer vision task underpinning applications such as spatial understanding, 3D reconstruction, and autonomous driving. While deep learning-based MDE methods can predict relative depth from a single image, their lack of metric scale information often results in scale inconsistencies, limiting their utility in downstream tasks like visual SLAM, 3D reconstruction, and novel view synthesis. Monocular Metric Depth Estimation (MMDE) addresses these challenges by enabling precise, scene-scale depth inference. MMDE improves depth consistency, enhances sequential task stability, simplifies integration into downstream applications, and broadens practical use cases. This paper provides a comprehensive review of depth estimation technologies, highlighting the evolution from geometry-based methods to state-of-the-art deep learning approaches. It emphasizes advancements in scale-agnostic methods, which are crucial for enabling zero-shot generalization as the foundational capability for MMDE. Recent progress in zero-shot MMDE research is explored, focusing on challenges such as model generalization and the loss of detail at scene boundaries. Innovative strategies to address these issues include unlabelled data augmentation, image patching, architectural optimization, and generative techniques. These advancements, analyzed in detail, demonstrate significant contributions to overcoming existing limitations. Finally, this paper synthesizes recent developments in zero-shot MMDE, identifies unresolved challenges, and outlines future research directions. By offering a clear roadmap and cutting-edge insights, this work aims to deepen understanding of MMDE, inspire novel applications, and drive technological innovation.
Robustifying DARTS by Eliminating Information Bypass Leakage via Explicit Sparse Regularization
Jun 12, 2023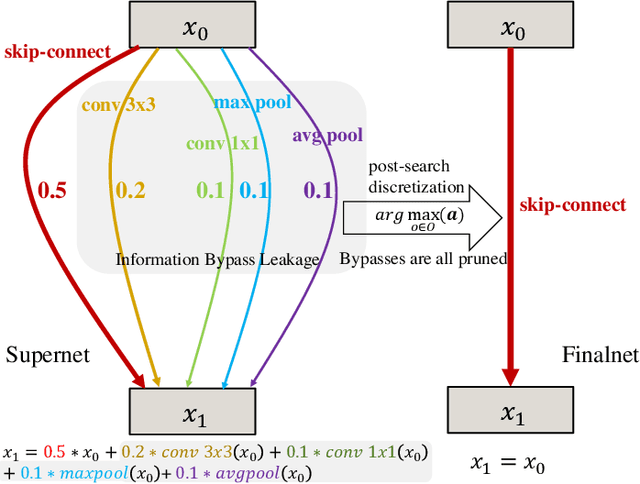


Differentiable architecture search (DARTS) is a promising end to end NAS method which directly optimizes the architecture parameters through general gradient descent. However, DARTS is brittle to the catastrophic failure incurred by the skip connection in the search space. Recent studies also cast doubt on the basic underlying hypotheses of DARTS which are argued to be inherently prone to the performance discrepancy between the continuous-relaxed supernet in the training phase and the discretized finalnet in the evaluation phase. We figure out that the robustness problem and the skepticism can both be explained by the information bypass leakage during the training of the supernet. This naturally highlights the vital role of the sparsity of architecture parameters in the training phase which has not been well developed in the past. We thus propose a novel sparse-regularized approximation and an efficient mixed-sparsity training scheme to robustify DARTS by eliminating the information bypass leakage. We subsequently conduct extensive experiments on multiple search spaces to demonstrate the effectiveness of our method.
Rethink DARTS Search Space and Renovate a New Benchmark
Jun 12, 2023DARTS search space (DSS) has become a canonical benchmark for NAS whereas some emerging works pointed out the issue of narrow accuracy range and claimed it would hurt the method ranking. We observe some recent studies already suffer from this issue that overshadows the meaning of scores. In this work, we first propose and orchestrate a suite of improvements to frame a larger and harder DSS, termed LHD, while retaining high efficiency in search. We step forward to renovate a LHD-based new benchmark, taking care of both discernibility and accessibility. Specifically, we re-implement twelve baselines and evaluate them across twelve conditions by combining two underexpolored influential factors: transductive robustness and discretization policy, to reasonably construct a benchmark upon multi-condition evaluation. Considering that the tabular benchmarks are always insufficient to adequately evaluate the methods of neural architecture search (NAS), our work can serve as a crucial basis for the future progress of NAS. https://github.com/chaoji90/LHD
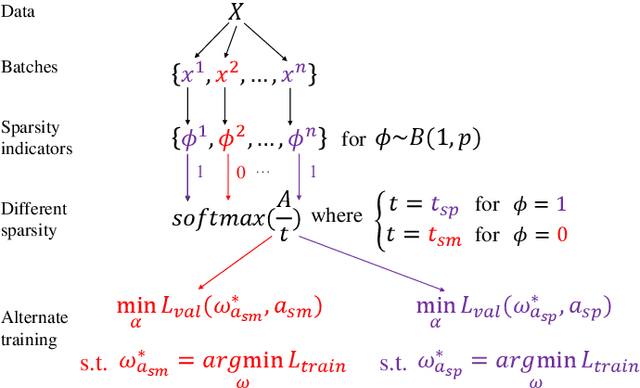
Small Temperature is All You Need for Differentiable Architecture Search
Jun 12, 2023Differentiable architecture search (DARTS) yields highly efficient gradient-based neural architecture search (NAS) by relaxing the discrete operation selection to optimize continuous architecture parameters that maps NAS from the discrete optimization to a continuous problem. DARTS then remaps the relaxed supernet back to the discrete space by one-off post-search pruning to obtain the final architecture (finalnet). Some emerging works argue that this remap is inherently prone to mismatch the network between training and evaluation which leads to performance discrepancy and even model collapse in extreme cases. We propose to close the gap between the relaxed supernet in training and the pruned finalnet in evaluation through utilizing small temperature to sparsify the continuous distribution in the training phase. To this end, we first formulate sparse-noisy softmax to get around gradient saturation. We then propose an exponential temperature schedule to better control the outbound distribution and elaborate an entropy-based adaptive scheme to finally achieve the enhancement. We conduct extensive experiments to verify the efficiency and efficacy of our method.
Delve into the Performance Degradation of Differentiable Architecture Search
Sep 28, 2021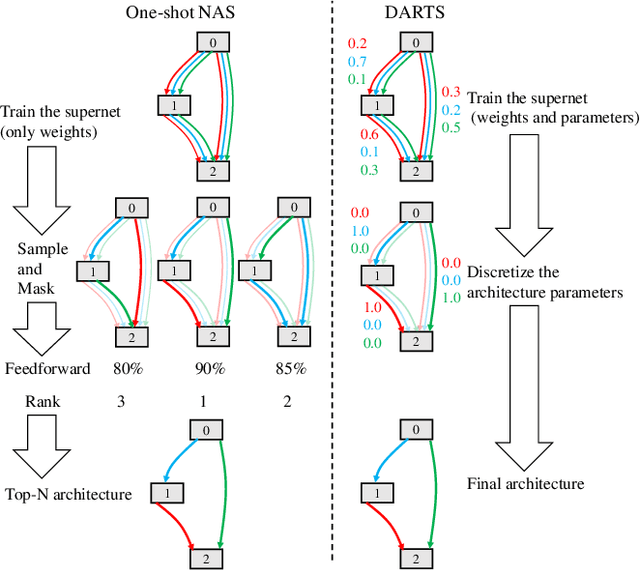
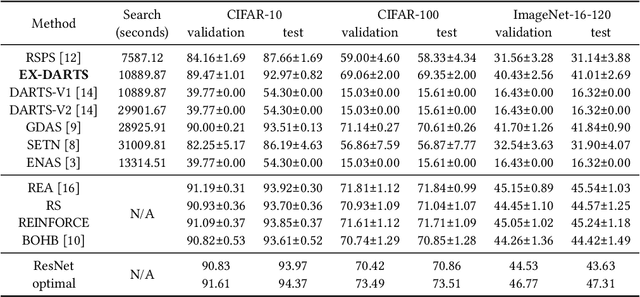
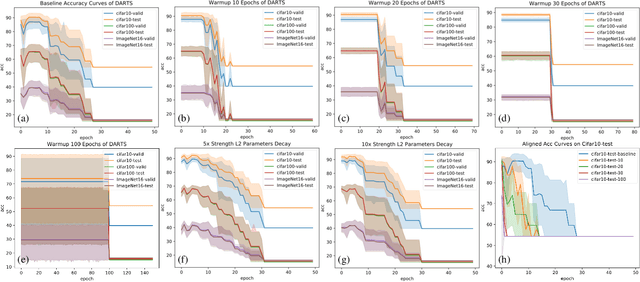
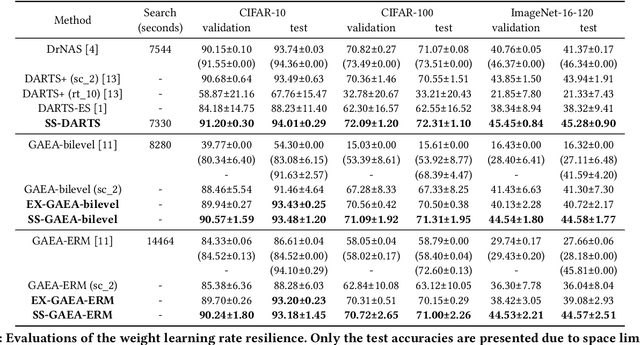
Differentiable architecture search (DARTS) is widely considered to be easy to overfit the validation set which leads to performance degradation. We first employ a series of exploratory experiments to verify that neither high-strength architecture parameters regularization nor warmup training scheme can effectively solve this problem. Based on the insights from the experiments, we conjecture that the performance of DARTS does not depend on the well-trained supernet weights and argue that the architecture parameters should be trained by the gradients which are obtained in the early stage rather than the final stage of training. This argument is then verified by exchanging the learning rate schemes of weights and parameters. Experimental results show that the simple swap of the learning rates can effectively solve the degradation and achieve competitive performance. Further empirical evidence suggests that the degradation is not a simple problem of the validation set overfitting but exhibit some links between the degradation and the operation selection bias within bilevel optimization dynamics. We demonstrate the generalization of this bias and propose to utilize this bias to achieve an operation-magnitude-based selective stop.