 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPS: A Framework for Accurate Program Sampling Using Graph Neural Network
Apr 18, 2023With the end of Moore's Law, there is a growing demand for rapid architectural innovations in modern processors, such as RISC-V custom extensions, to continue performance scaling. Program sampling is a crucial step in microprocessor design, as it selects representative simulation points for workload simulation. While SimPoint has been the de-facto approach for decades, its limited expressiveness with Basic Block Vector (BBV) requires time-consuming human tuning, often taking months, which impedes fast innovation and agile hardware development. This paper introduces Neural Program Sampling (NPS), a novel framework that learns execution embeddings using dynamic snapshots of a Graph Neural Network. NPS deploys AssemblyNet for embedding generation, leveraging an application's code structures and runtime states. AssemblyNet serves as NPS's graph model and neural architecture, capturing a program's behavior in aspects such as data computation, code path, and data flow. AssemblyNet is trained with a data prefetch task that predicts consecutive memory addresses. In the experiments, NPS outperforms SimPoint by up to 63%, reducing the average error by 38%. Additionally, NPS demonstrates strong robustness with increased accuracy, reducing the expensive accuracy tuning overhead. Furthermore, NPS shows higher accuracy and generality than the state-of-the-art GNN approach in code behavior learning, enabling the generation of high-quality execution embeddings.
Predicting the Output Structure of Sparse Matrix Multiplication with Sampled Compression Ratio
Jul 28, 2022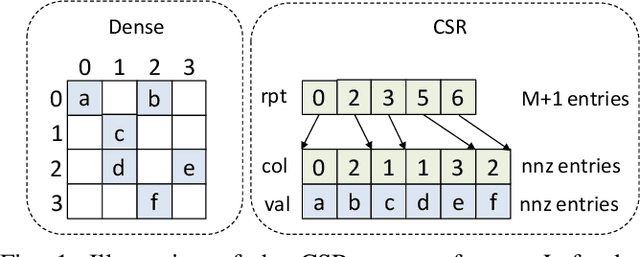
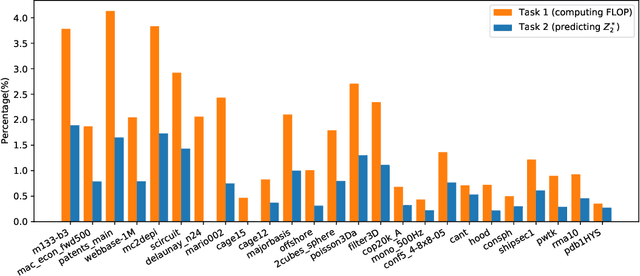
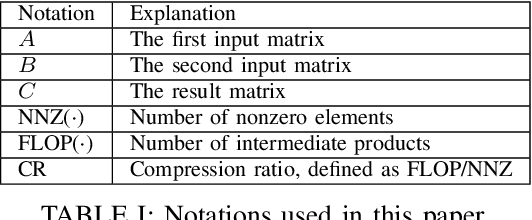
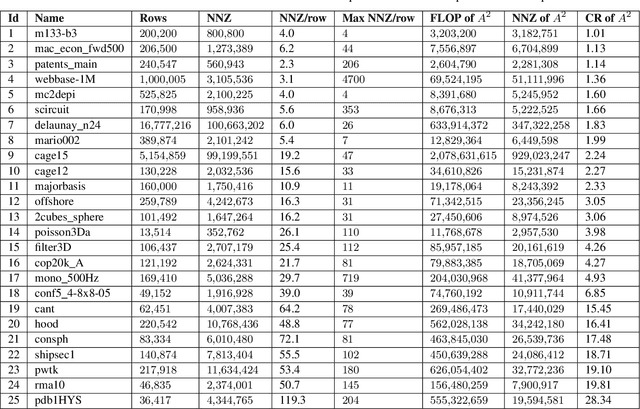
Sparse general matrix multiplication (SpGEMM) is a fundamental building block in numerous scientific applications. One critical task of SpGEMM is to compute or predict the structure of the output matrix (i.e., the number of nonzero elements per output row) for efficient memory allocation and load balance, which impact the overall performance of SpGEMM. Existing work either precisely calculates the output structure or adopts upper-bound or sampling-based methods to predict the output structure. However, these methods either take much execution time or are not accurate enough. In this paper, we propose a novel sampling-based method with better accuracy and low costs compared to the existing sampling-based method. The proposed method first predicts the compression ratio of SpGEMM by leveraging the number of intermediate products (denoted as FLOP) and the number of nonzero elements (denoted as NNZ) of the same sampled result matrix. And then, the predicted output structure is obtained by dividing the FLOP per output row by the predicted compression ratio. We also propose a reference design of the existing sampling-based method with optimized computing overheads to demonstrate the better accuracy of the proposed method. We construct 625 test cases with various matrix dimensions and sparse structures to evaluate the prediction accuracy. Experimental results show that the absolute relative errors of the proposed method and the reference design are 1.56\% and 8.12\%, respectively, on average, and 25\% and 156\%, respectively, in the worst case.