 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Analysis of Available Source Code of Top Artificial Intelligence Conference Papers
Paper and Code
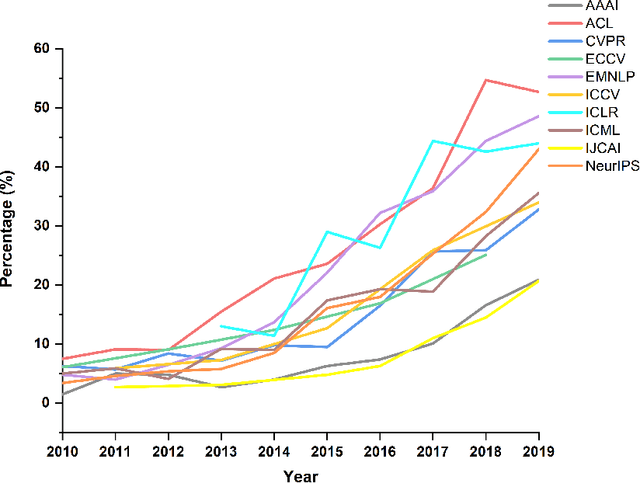
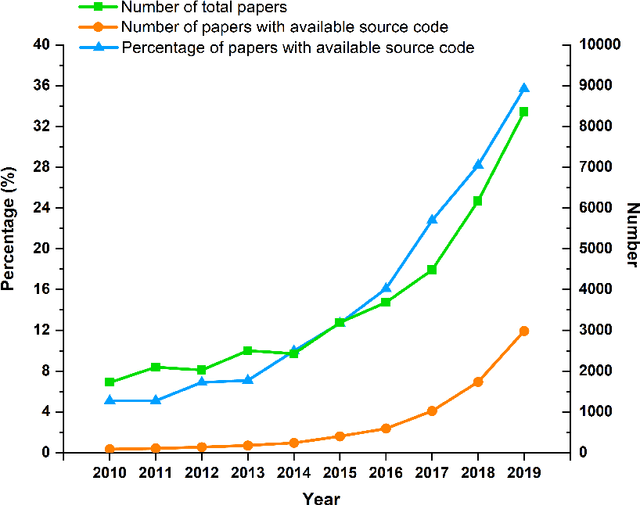


Source code is essential for researchers to reproduce the methods and replicate the results of artificial intelligence (AI) papers. Some organizations and researchers manually collect AI papers with available source code to contribute to the AI community. However, manual collection is a labor-intensive and time-consuming task. To address this issue, we propose a method to automatically identify papers with available source code and extract their source code repository URLs. With this method, we find that 20.5% of regular papers of 10 top AI conferences published from 2010 to 2019 are identified as papers with available source code and that 8.1% of these source code repositories are no longer accessible. We also create the XMU NLP Lab README Dataset, the largest dataset of labeled README files for source code document research. Through this dataset, we have discovered that quite a few README files have no installation instructions or usage tutorials provided. Further, a large-scale comprehensive statistical analysis is made for a general picture of the source code of AI conference papers. The proposed solution can also go beyond AI conference papers to analyze other scientific papers from both journals and conferences to shed light on more domains.