 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-VTON: Towards General Purpose Virtual Try-on via Collaborative Local-Flow Global-Parsing Learning
Mar 24, 2023Image-based Virtual Try-ON aims to transfer an in-shop garment onto a specific person. Existing methods employ a global warping module to model the anisotropic deformation for different garment parts, which fails to preserve the semantic information of different parts when receiving challenging inputs (e.g, intricate human poses, difficult garments). Moreover, most of them directly warp the input garment to align with the boundary of the preserved region, which usually requires texture squeezing to meet the boundary shape constraint and thus leads to texture distortion. The above inferior performance hinders existing methods from real-world applications. To address these problems and take a step towards real-world virtual try-on, we propose a General-Purpose Virtual Try-ON framework, named GP-VTON, by developing an innovative Local-Flow Global-Parsing (LFGP) warping module and a Dynamic Gradient Truncation (DGT) training strategy. Specifically, compared with the previous global warping mechanism, LFGP employs local flows to warp garments parts individually, and assembles the local warped results via the global garment parsing, resulting in reasonable warped parts and a semantic-correct intact garment even with challenging inputs.On the other hand, our DGT training strategy dynamically truncates the gradient in the overlap area and the warped garment is no more required to meet the boundary constraint, which effectively avoids the texture squeezing problem. Furthermore, our GP-VTON can be easily extended to multi-category scenario and jointly trained by using data from different garment categories. Extensive experiments on two high-resolution benchmarks demonstrate our superiority over the existing state-of-the-art methods.
Towards Hard-pose Virtual Try-on via 3D-aware Global Correspondence Learning
Nov 25, 2022



In this paper, we target image-based person-to-person virtual try-on in the presence of diverse poses and large viewpoint variations. Existing methods are restricted in this setting as they estimate garment warping flows mainly based on 2D poses and appearance, which omits the geometric prior of the 3D human body shape. Moreover, current garment warping methods are confined to localized regions, which makes them ineffective in capturing long-range dependencies and results in inferior flows with artifacts. To tackle these issues, we present 3D-aware global correspondences, which are reliable flows that jointly encode global semantic correlations, local deformations, and geometric priors of 3D human bodies. Particularly, given an image pair depicting the source and target person, (a) we first obtain their pose-aware and high-level representations via two encoders, and introduce a coarse-to-fine decoder with multiple refinement modules to predict the pixel-wise global correspondence. (b) 3D parametric human models inferred from images are incorporated as priors to regularize the correspondence refinement process so that our flows can be 3D-aware and better handle variations of pose and viewpoint. (c) Finally, an adversarial generator takes the garment warped by the 3D-aware flow, and the image of the target person as inputs, to synthesize the photo-realistic try-on result. Extensive experiments on public benchmarks and our HardPose test set demonstrate the superiority of our method against the SOTA try-on approaches.
PASTA-GAN++: A Versatile Framework for High-Resolution Unpaired Virtual Try-on
Jul 27, 2022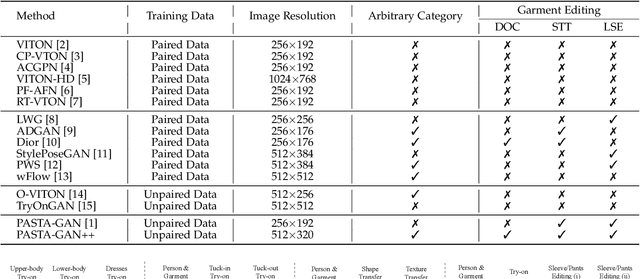

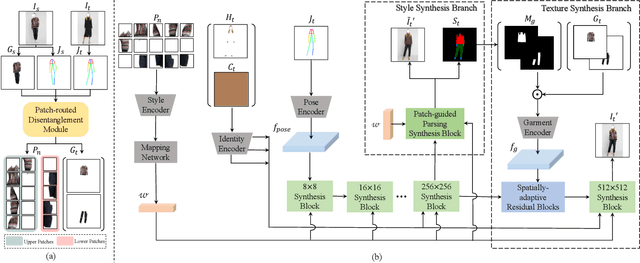

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. In this work, we take a step forwards to explore versatile virtual try-on solutions, which we argue should possess three main properties, namely, they should support unsupervised training, arbitrary garment categories, and controllable garment editing. To this end, we propose a characteristic-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN++ (PASTA-GAN++), to achieve a versatile system for high-resolution unpaired virtual try-on. Specifically, our PASTA-GAN++ consists of an innovative patch-routed disentanglement module to decouple the intact garment into normalized patches, which is capable of retaining garment style information while eliminating the garment spatial information, thus alleviating the overfitting issue during unsupervised training. Furthermore, PASTA-GAN++ introduces a patch-based garment representation and a patch-guided parsing synthesis block, allowing it to handle arbitrary garment categories and support local garment editing. Finally, to obtain try-on results with realistic texture details, PASTA-GAN++ incorporates a novel spatially-adaptive residual module to inject the coarse warped garment feature into the generator. Extensive experiments on our newly collected UnPaired virtual Try-on (UPT) dataset demonstrate the superiority of PASTA-GAN++ over existing SOTAs and its ability for controllable garment editing.
Towards Scalable Unpaired Virtual Try-On via Patch-Routed Spatially-Adaptive GAN
Nov 20, 2021
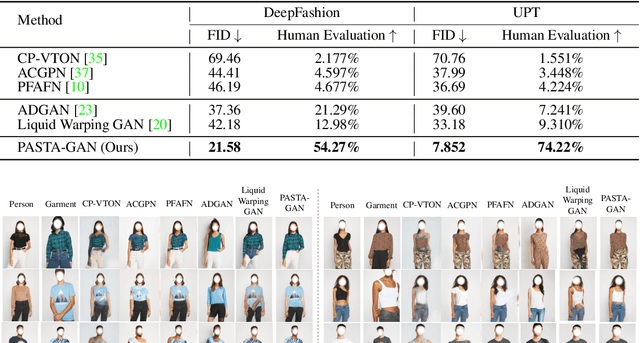
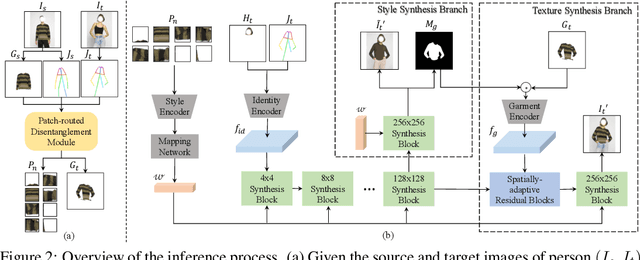

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. Yet, as most try-on approaches fit in-shop garments onto a target person, they require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability. While a few recent works attempt to transfer garments directly from one person to another, alleviating the need to collect paired datasets, their performance is impacted by the lack of paired (supervised) information. In particular, disentangling style and spatial information of the garment becomes a challenge, which existing methods either address by requiring auxiliary data or extensive online optimization procedures, thereby still inhibiting their scalability. To achieve a \emph{scalable} virtual try-on system that can transfer arbitrary garments between a source and a target person in an unsupervised manner, we thus propose a texture-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN (PASTA-GAN), that facilitates real-world unpaired virtual try-on. Specifically, to disentangle the style and spatial information of each garment, PASTA-GAN consists of an innovative patch-routed disentanglement module for successfully retaining garment texture and shape characteristics. Guided by the source person keypoints, the patch-routed disentanglement module first decouples garments into normalized patches, thus eliminating the inherent spatial information of the garment, and then reconstructs the normalized patches to the warped garment complying with the target person pose. Given the warped garment, PASTA-GAN further introduces novel spatially-adaptive residual blocks that guide the generator to synthesize more realistic garment details.