 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deep Learning Framework for Human Activity Recognition
Aug 21, 2024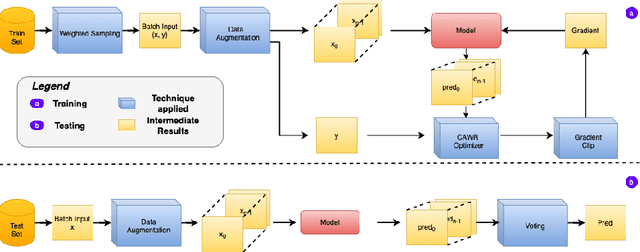
In the realm of human activity recognition (HAR), the integration of explainable Artificial Intelligence (XAI) emerges as a critical necessity to elucidate the decision-making processes of complex models, fostering transparency and trust. Traditional explanatory methods like Class Activation Mapping (CAM) and attention mechanisms, although effective in highlighting regions vital for decisions in various contexts, prove inadequate for HAR. This inadequacy stems from the inherently abstract nature of HAR data, rendering these explanations obscure. In contrast, state-of-th-art post-hoc interpretation techniques for time series can explain the model from other perspectives. However, this requires extra effort. It usually takes 10 to 20 seconds to generate an explanation. To overcome these challenges, we proposes a novel, model-agnostic framework that enhances both the interpretability and efficacy of HAR models through the strategic use of competitive data augmentation. This innovative approach does not rely on any particular model architecture, thereby broadening its applicability across various HAR models. By implementing competitive data augmentation, our framework provides intuitive and accessible explanations of model decisions, thereby significantly advancing the interpretability of HAR systems without compromising on performance.
Standardizing Your Training Process for Human Activity Recognition Models: A Comprehensive Review in the Tunable Factors
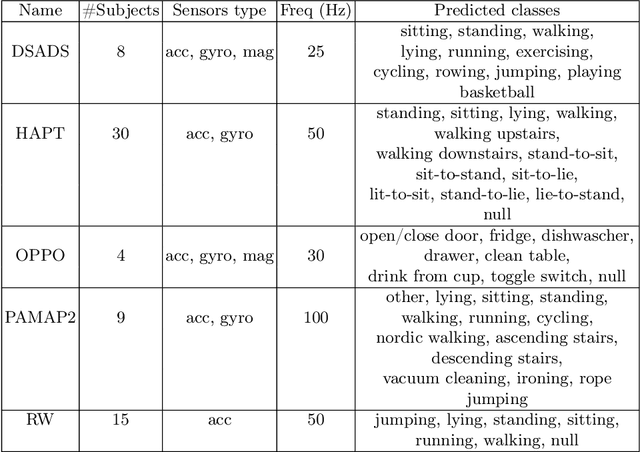
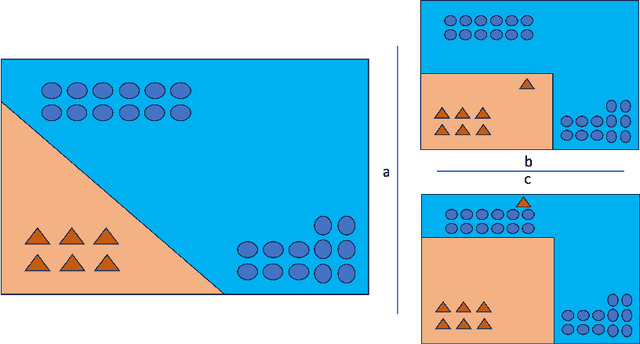
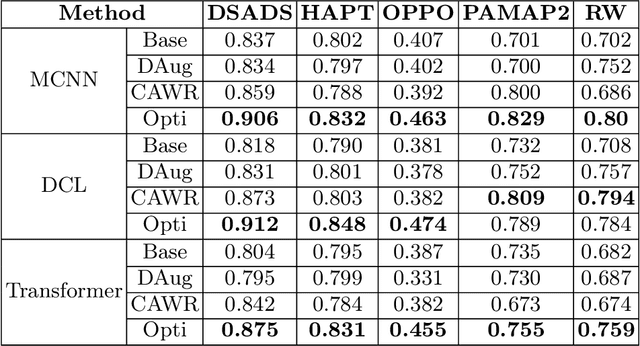
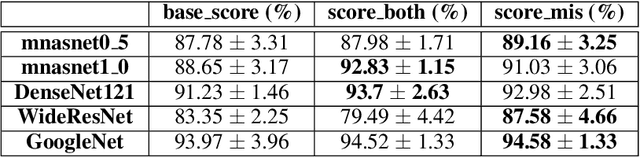
Jan 10, 2024In recent years, deep learning has emerged as a potent tool across a multitude of domains, leading to a surge in research pertaining to its application in the wearable human activity recognition (WHAR) domain. Despite the rapid development, concerns have been raised about the lack of standardization and consistency in the procedures used for experimental model training, which may affect the reproducibility and reliability of research results. In this paper, we provide an exhaustive review of contemporary deep learning research in the field of WHAR and collate information pertaining to the training procedure employed in various studies. Our findings suggest that a major trend is the lack of detail provided by model training protocols. Besides, to gain a clearer understanding of the impact of missing descriptions, we utilize a control variables approach to assess the impact of key tunable components (e.g., optimization techniques and early stopping criteria) on the inter-subject generalization capabilities of HAR models. With insights from the analyses, we define a novel integrated training procedure tailored to the WHAR model. Empirical results derived using five well-known \ac{whar} benchmark datasets and three classical HAR model architectures demonstrate the effectiveness of our proposed methodology: in particular, there is a significant improvement in macro F1 leave one subject out cross-validation performance.
randomHAR: Improving Ensemble Deep Learners for Human Activity Recognition with Sensor Selection and Reinforcement Learning
Jul 15, 2023Deep learning has proven to be an effective approach in the field of Human activity recognition (HAR), outperforming other architectures that require manual feature engineering. Despite recent advancements, challenges inherent to HAR data, such as noisy data, intra-class variability and inter-class similarity, remain. To address these challenges, we propose an ensemble method, called randomHAR. The general idea behind randomHAR is training a series of deep learning models with the same architecture on randomly selected sensor data from the given dataset. Besides, an agent is trained with the reinforcement learning algorithm to identify the optimal subset of the trained models that are utilized for runtime prediction. In contrast to existing work, this approach optimizes the ensemble process rather than the architecture of the constituent models. To assess the performance of the approach, we compare it against two HAR algorithms, including the current state of the art, on six HAR benchmark datasets. The result of the experiment demonstrates that the proposed approach outperforms the state-of-the-art method, ensembleLSTM.
Universal Distributional Decision-based Black-box Adversarial Attack with Reinforcement Learning
Nov 15, 2022
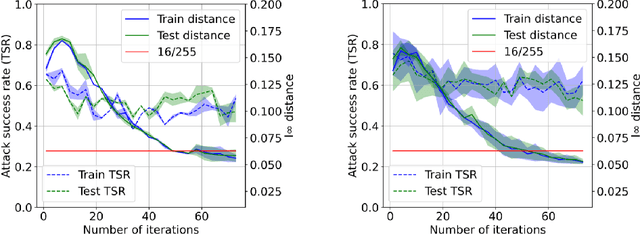
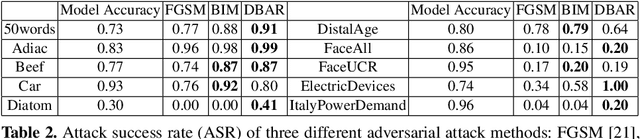
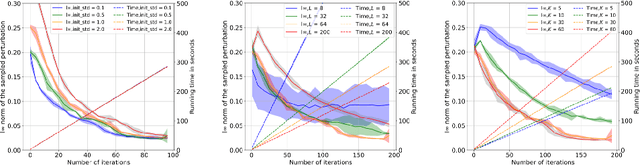
The vulnerability of the high-performance machine learning models implies a security risk in applications with real-world consequences. Research on adversarial attacks is beneficial in guiding the development of machine learning models on the one hand and finding targeted defenses on the other. However, most of the adversarial attacks today leverage the gradient or logit information from the models to generate adversarial perturbation. Works in the more realistic domain: decision-based attacks, which generate adversarial perturbation solely based on observing the output label of the targeted model, are still relatively rare and mostly use gradient-estimation strategies. In this work, we propose a pixel-wise decision-based attack algorithm that finds a distribution of adversarial perturbation through a reinforcement learning algorithm. We call this method Decision-based Black-box Attack with Reinforcement learning (DBAR). Experiments show that the proposed approach outperforms state-of-the-art decision-based attacks with a higher attack success rate and greater transferability.
McXai: Local model-agnostic explanation as two games
Jan 04, 2022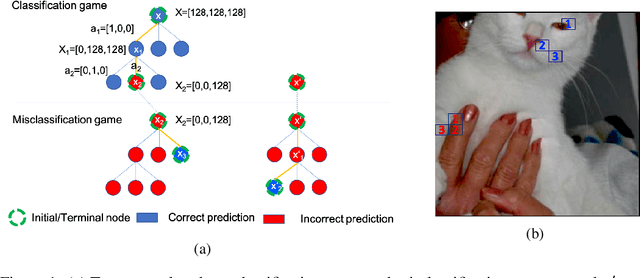
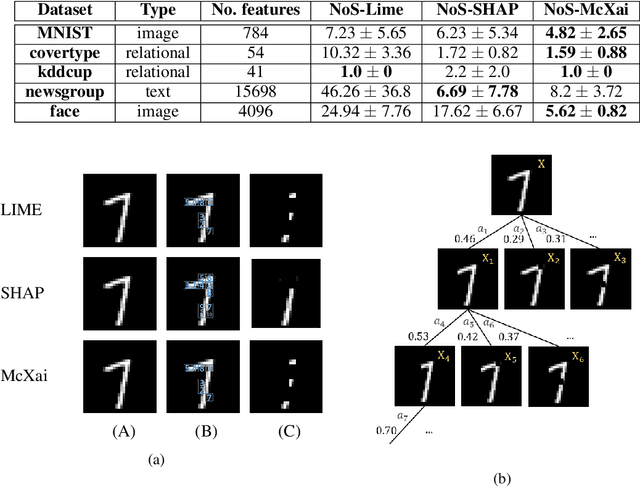
To this day, a variety of approaches for providing local interpretability of black-box machine learning models have been introduced. Unfortunately, all of these methods suffer from one or more of the following deficiencies: They are either difficult to understand themselves, they work on a per-feature basis and ignore the dependencies between features and/or they only focus on those features asserting the decision made by the model. To address these points, this work introduces a reinforcement learning-based approach called Monte Carlo tree search for eXplainable Artificial Intelligent (McXai) to explain the decisions of any black-box classification model (classifier). Our method leverages Monte Carlo tree search and models the process of generating explanations as two games. In one game, the reward is maximized by finding feature sets that support the decision of the classifier, while in the second game, finding feature sets leading to alternative decisions maximizes the reward. The result is a human friendly representation as a tree structure, in which each node represents a set of features to be studied with smaller explanations at the top of the tree. Our experiments show, that the features found by our method are more informative with respect to classifications than those found by classical approaches like LIME and SHAP. Furthermore, by also identifying misleading features, our approach is able to guide towards improved robustness of the black-box model in many situations.
Automatic Remaining Useful Life Estimation Framework with Embedded Convolutional LSTM as the Backbone
Aug 10, 2020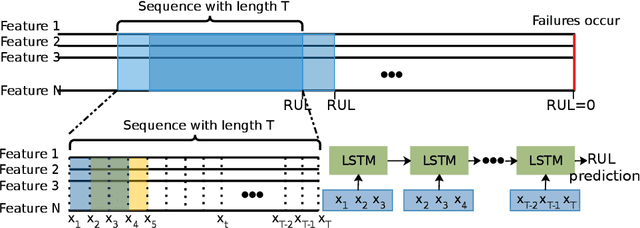
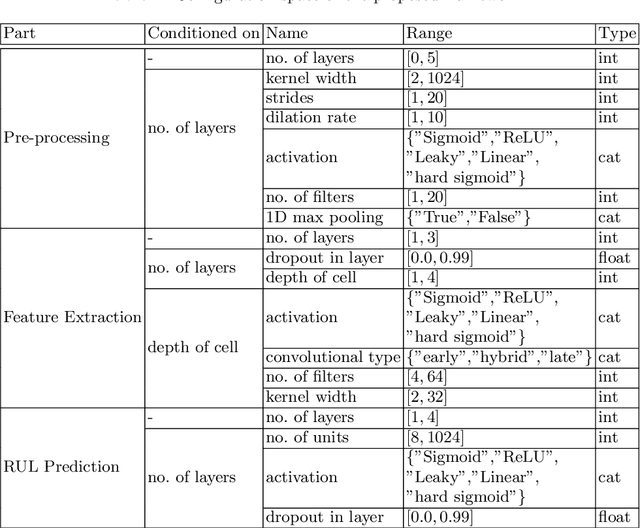
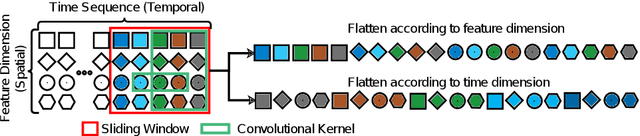

An essential task in predictive maintenance is the prediction of the Remaining Useful Life (RUL) through the analysis of multivariate time series. Using the sliding window method, Convolutional Neural Network (CNN) and conventional Recurrent Neural Network (RNN) approaches have produced impressive results on this matter, due to their ability to learn optimized features. However, sequence information is only partially modeled by CNN approaches. Due to the flatten mechanism in conventional RNNs, like Long Short Term Memories (LSTM), the temporal information within the window is not fully preserved. To exploit the multi-level temporal information, many approaches are proposed which combine CNN and RNN models. In this work, we propose a new LSTM variant called embedded convolutional LSTM (ECLSTM). In ECLSTM a group of different 1D convolutions is embedded into the LSTM structure. Through this, the temporal information is preserved between and within windows. Since the hyper-parameters of models require careful tuning, we also propose an automated prediction framework based on the Bayesian optimization with hyperband optimizer, which allows for efficient optimization of the network architecture. Finally, we show the superiority of our proposed ECLSTM approach over the state-of-the-art approaches on several widely used benchmark data sets for RUL Estimation.