 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Compact Spaces with Approximately Normalized Transformers
May 28, 2025In deep learning, regularization and normalization are common solutions for challenges such as overfitting, numerical instabilities, and the increasing variance in the residual stream. An alternative approach is to force all parameters and representations to lie on a hypersphere. This removes the need for regularization and increases convergence speed, but comes with additional costs. In this work, we propose a more holistic but approximate normalization (anTransformer). Our approach constrains the norm of parameters and normalizes all representations via scalar multiplications motivated by the tight concentration of the norms of high-dimensional random vectors. When applied to GPT training, we observe a 40% faster convergence compared to models with QK normalization, with less than 3% additional runtime. Deriving scaling laws for anGPT, we found our method enables training with larger batch sizes and fewer hyperparameters, while matching the favorable scaling characteristics of classic GPT architectures.
Tiny Deep Ensemble: Uncertainty Estimation in Edge AI Accelerators via Ensembling Normalization Layers with Shared Weights
May 07, 2024



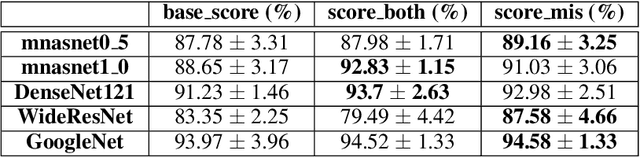
The applications of artificial intelligence (AI) are rapidly evolving, and they are also commonly used in safety-critical domains, such as autonomous driving and medical diagnosis, where functional safety is paramount. In AI-driven systems, uncertainty estimation allows the user to avoid overconfidence predictions and achieve functional safety. Therefore, the robustness and reliability of model predictions can be improved. However, conventional uncertainty estimation methods, such as the deep ensemble method, impose high computation and, accordingly, hardware (latency and energy) overhead because they require the storage and processing of multiple models. Alternatively, Monte Carlo dropout (MC-dropout) methods, although having low memory overhead, necessitate numerous ($\sim 100$) forward passes, leading to high computational overhead and latency. Thus, these approaches are not suitable for battery-powered edge devices with limited computing and memory resources. In this paper, we propose the Tiny-Deep Ensemble approach, a low-cost approach for uncertainty estimation on edge devices. In our approach, only normalization layers are ensembled $M$ times, with all ensemble members sharing common weights and biases, leading to a significant decrease in storage requirements and latency. Moreover, our approach requires only one forward pass in a hardware architecture that allows batch processing for inference and uncertainty estimation. Furthermore, it has approximately the same memory overhead compared to a single model. Therefore, latency and memory overhead are reduced by a factor of up to $\sim M\times$. Nevertheless, our method does not compromise accuracy, with an increase in inference accuracy of up to $\sim 1\%$ and a reduction in RMSE of $17.17\%$ in various benchmark datasets, tasks, and state-of-the-art architectures.
Embedding Hardware Approximations in Discrete Genetic-based Training for Printed MLPs
Feb 05, 2024



Printed Electronics (PE) stands out as a promisingtechnology for widespread computing due to its distinct attributes, such as low costs and flexible manufacturing. Unlike traditional silicon-based technologies, PE enables stretchable, conformal,and non-toxic hardware. However, PE are constrained by larger feature sizes, making it challenging to implement complex circuits such as machine learning (ML) classifiers. Approximate computing has been proven to reduce the hardware cost of ML circuits such as Multilayer Perceptrons (MLPs). In this paper, we maximize the benefits of approximate computing by integrating hardware approximation into the MLP training process. Due to the discrete nature of hardware approximation, we propose and implement a genetic-based, approximate, hardware-aware training approach specifically designed for printed MLPs. For a 5% accuracy loss, our MLPs achieve over 5x area and power reduction compared to the baseline while outperforming state of-the-art approximate and stochastic printed MLPs.
Testing Spintronics Implemented Monte Carlo Dropout-Based Bayesian Neural Networks
Jan 09, 2024



Bayesian Neural Networks (BayNNs) can inherently estimate predictive uncertainty, facilitating informed decision-making. Dropout-based BayNNs are increasingly implemented in spintronics-based computation-in-memory architectures for resource-constrained yet high-performance safety-critical applications. Although uncertainty estimation is important, the reliability of Dropout generation and BayNN computation is equally important for target applications but is overlooked in existing works. However, testing BayNNs is significantly more challenging compared to conventional NNs, due to their stochastic nature. In this paper, we present for the first time the model of the non-idealities of the spintronics-based Dropout module and analyze their impact on uncertainty estimates and accuracy. Furthermore, we propose a testing framework based on repeatability ranking for Dropout-based BayNN with up to $100\%$ fault coverage while using only $0.2\%$ of training data as test vectors.
Scale-Dropout: Estimating Uncertainty in Deep Neural Networks Using Stochastic Scale
Nov 27, 2023



Uncertainty estimation in Neural Networks (NNs) is vital in improving reliability and confidence in predictions, particularly in safety-critical applications. Bayesian Neural Networks (BayNNs) with Dropout as an approximation offer a systematic approach to quantifying uncertainty, but they inherently suffer from high hardware overhead in terms of power, memory, and computation. Thus, the applicability of BayNNs to edge devices with limited resources or to high-performance applications is challenging. Some of the inherent costs of BayNNs can be reduced by accelerating them in hardware on a Computation-In-Memory (CIM) architecture with spintronic memories and binarizing their parameters. However, numerous stochastic units are required to implement conventional dropout-based BayNN. In this paper, we propose the Scale Dropout, a novel regularization technique for Binary Neural Networks (BNNs), and Monte Carlo-Scale Dropout (MC-Scale Dropout)-based BayNNs for efficient uncertainty estimation. Our approach requires only one stochastic unit for the entire model, irrespective of the model size, leading to a highly scalable Bayesian NN. Furthermore, we introduce a novel Spintronic memory-based CIM architecture for the proposed BayNN that achieves more than $100\times$ energy savings compared to the state-of-the-art. We validated our method to show up to a $1\%$ improvement in predictive performance and superior uncertainty estimates compared to related works.
New Horizons in Parameter Regularization: A Constraint Approach
Nov 15, 2023



This work presents constrained parameter regularization (CPR), an alternative to traditional weight decay. Instead of applying a constant penalty uniformly to all parameters, we enforce an upper bound on a statistical measure (e.g., the L$_2$-norm) of individual parameter groups. This reformulates learning as a constrained optimization problem. To solve this, we utilize an adaptation of the augmented Lagrangian method. Our approach allows for varying regularization strengths across different parameter groups, removing the need for explicit penalty coefficients in the regularization terms. CPR only requires two hyperparameters and introduces no measurable runtime overhead. We offer empirical evidence of CPR's effectiveness through experiments in the "grokking" phenomenon, image classification, and language modeling. Our findings show that CPR can counteract the effects of grokking, and it consistently matches or surpasses the performance of traditional weight decay.
Spatial-SpinDrop: Spatial Dropout-based Binary Bayesian Neural Network with Spintronics Implementation
Jun 16, 2023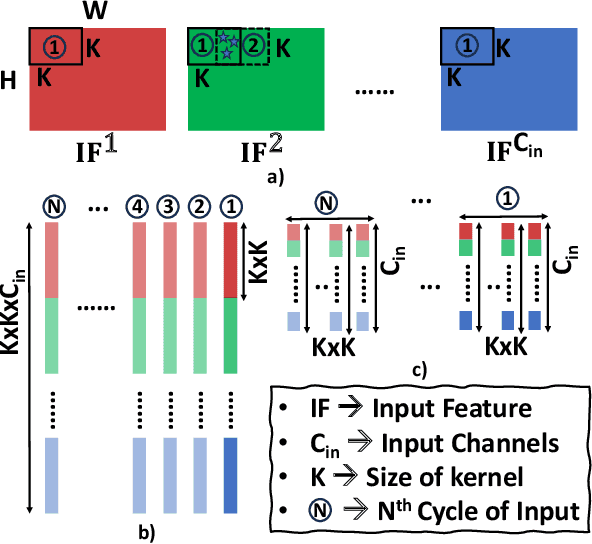
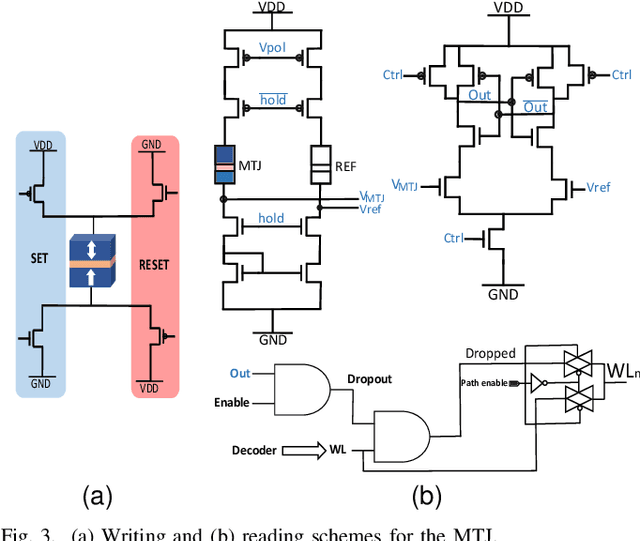
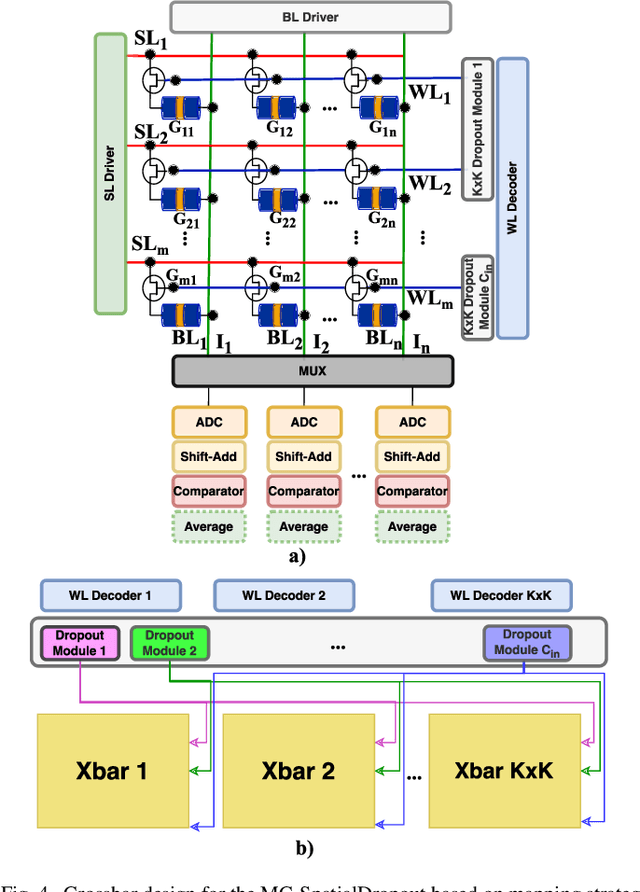
Recently, machine learning systems have gained prominence in real-time, critical decision-making domains, such as autonomous driving and industrial automation. Their implementations should avoid overconfident predictions through uncertainty estimation. Bayesian Neural Networks (BayNNs) are principled methods for estimating predictive uncertainty. However, their computational costs and power consumption hinder their widespread deployment in edge AI. Utilizing Dropout as an approximation of the posterior distribution, binarizing the parameters of BayNNs, and further to that implementing them in spintronics-based computation-in-memory (CiM) hardware arrays provide can be a viable solution. However, designing hardware Dropout modules for convolutional neural network (CNN) topologies is challenging and expensive, as they may require numerous Dropout modules and need to use spatial information to drop certain elements. In this paper, we introduce MC-SpatialDropout, a spatial dropout-based approximate BayNNs with spintronics emerging devices. Our method utilizes the inherent stochasticity of spintronic devices for efficient implementation of the spatial dropout module compared to existing implementations. Furthermore, the number of dropout modules per network layer is reduced by a factor of $9\times$ and energy consumption by a factor of $94.11\times$, while still achieving comparable predictive performance and uncertainty estimates compared to related works.
Universal Distributional Decision-based Black-box Adversarial Attack with Reinforcement Learning
Nov 15, 2022
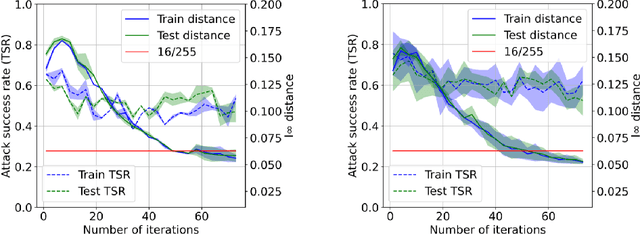
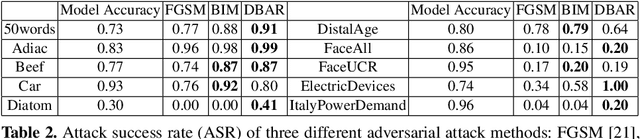
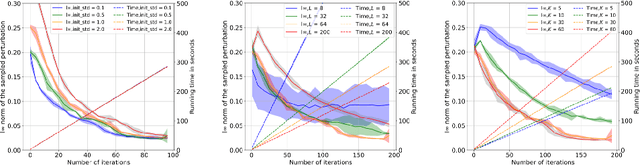
The vulnerability of the high-performance machine learning models implies a security risk in applications with real-world consequences. Research on adversarial attacks is beneficial in guiding the development of machine learning models on the one hand and finding targeted defenses on the other. However, most of the adversarial attacks today leverage the gradient or logit information from the models to generate adversarial perturbation. Works in the more realistic domain: decision-based attacks, which generate adversarial perturbation solely based on observing the output label of the targeted model, are still relatively rare and mostly use gradient-estimation strategies. In this work, we propose a pixel-wise decision-based attack algorithm that finds a distribution of adversarial perturbation through a reinforcement learning algorithm. We call this method Decision-based Black-box Attack with Reinforcement learning (DBAR). Experiments show that the proposed approach outperforms state-of-the-art decision-based attacks with a higher attack success rate and greater transferability.
McXai: Local model-agnostic explanation as two games
Jan 04, 2022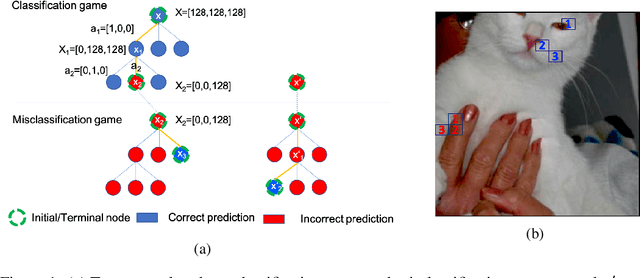
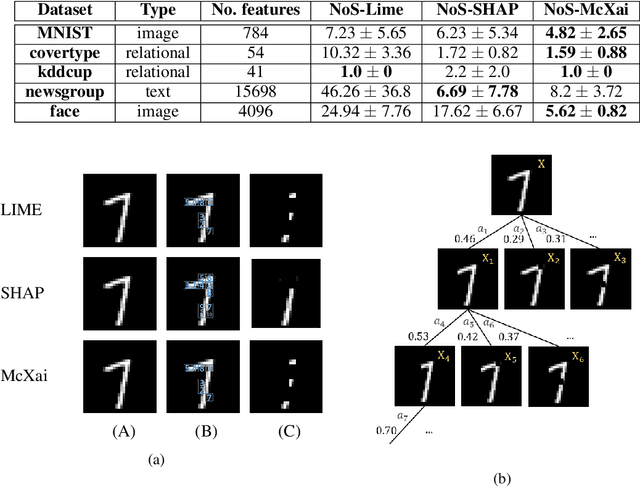
To this day, a variety of approaches for providing local interpretability of black-box machine learning models have been introduced. Unfortunately, all of these methods suffer from one or more of the following deficiencies: They are either difficult to understand themselves, they work on a per-feature basis and ignore the dependencies between features and/or they only focus on those features asserting the decision made by the model. To address these points, this work introduces a reinforcement learning-based approach called Monte Carlo tree search for eXplainable Artificial Intelligent (McXai) to explain the decisions of any black-box classification model (classifier). Our method leverages Monte Carlo tree search and models the process of generating explanations as two games. In one game, the reward is maximized by finding feature sets that support the decision of the classifier, while in the second game, finding feature sets leading to alternative decisions maximizes the reward. The result is a human friendly representation as a tree structure, in which each node represents a set of features to be studied with smaller explanations at the top of the tree. Our experiments show, that the features found by our method are more informative with respect to classifications than those found by classical approaches like LIME and SHAP. Furthermore, by also identifying misleading features, our approach is able to guide towards improved robustness of the black-box model in many situations.
Automatic Remaining Useful Life Estimation Framework with Embedded Convolutional LSTM as the Backbone
Aug 10, 2020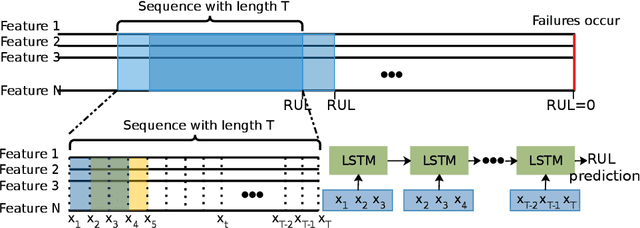
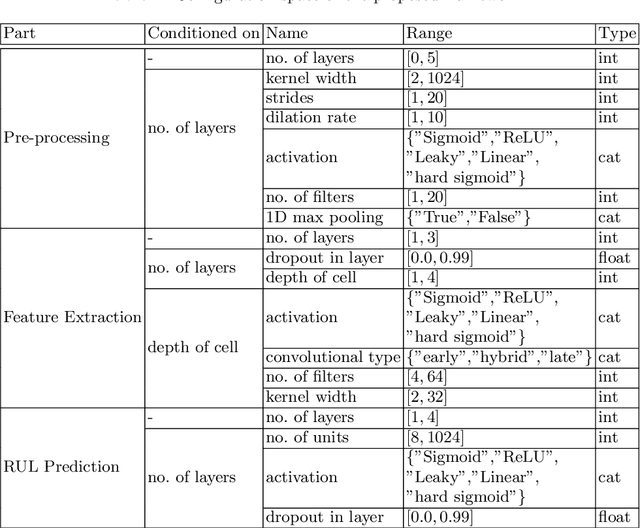
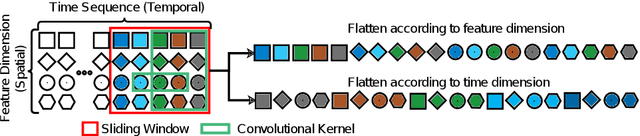

An essential task in predictive maintenance is the prediction of the Remaining Useful Life (RUL) through the analysis of multivariate time series. Using the sliding window method, Convolutional Neural Network (CNN) and conventional Recurrent Neural Network (RNN) approaches have produced impressive results on this matter, due to their ability to learn optimized features. However, sequence information is only partially modeled by CNN approaches. Due to the flatten mechanism in conventional RNNs, like Long Short Term Memories (LSTM), the temporal information within the window is not fully preserved. To exploit the multi-level temporal information, many approaches are proposed which combine CNN and RNN models. In this work, we propose a new LSTM variant called embedded convolutional LSTM (ECLSTM). In ECLSTM a group of different 1D convolutions is embedded into the LSTM structure. Through this, the temporal information is preserved between and within windows. Since the hyper-parameters of models require careful tuning, we also propose an automated prediction framework based on the Bayesian optimization with hyperband optimizer, which allows for efficient optimization of the network architecture. Finally, we show the superiority of our proposed ECLSTM approach over the state-of-the-art approaches on several widely used benchmark data sets for RUL Estimation.