 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaoSR-SHE: Stepwise Hybrid Examination Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance analysis is a foundational technology in e-commerce search engines and has become increasingly important in AI-driven e-commerce. The recent emergence of large language models (LLMs), particularly their chain-of-thought (CoT) reasoning capabilities, offers promising opportunities for developing relevance systems that are both more interpretable and more robust. However, existing training paradigms have notable limitations: SFT and DPO suffer from poor generalization on long-tail queries and from a lack of fine-grained, stepwise supervision to enforce rule-aligned reasoning. In contrast, reinforcement learning with verification rewards (RLVR) suffers from sparse feedback, which provides insufficient signal to correct erroneous intermediate steps, thereby undermining logical consistency and limiting performance in complex inference scenarios. To address these challenges, we introduce the Stepwise Hybrid Examination Reinforcement Learning framework for Taobao Search Relevance (TaoSR-SHE). At its core is Stepwise Reward Policy Optimization (SRPO), a reinforcement learning algorithm that leverages step-level rewards generated by a hybrid of a high-quality generative stepwise reward model and a human-annotated offline verifier, prioritizing learning from critical correct and incorrect reasoning steps. TaoSR-SHE further incorporates two key techniques: diversified data filtering to encourage exploration across varied reasoning paths and mitigate policy entropy collapse, and multi-stage curriculum learning to foster progressive capability growth. Extensive experiments on real-world search benchmarks show that TaoSR-SHE improves both reasoning quality and relevance-prediction accuracy in large-scale e-commerce settings, outperforming SFT, DPO, GRPO, and other baselines, while also enhancing interpretability and robustness.
TaoSR-AGRL: Adaptive Guided Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance prediction is fundamental to e-commerce search and has become even more critical in the era of AI-powered shopping, where semantic understanding and complex reasoning directly shape the user experience and business conversion. Large Language Models (LLMs) enable generative, reasoning-based approaches, typically aligned via supervised fine-tuning (SFT) or preference optimization methods like Direct Preference Optimization (DPO). However, the increasing complexity of business rules and user queries exposes the inability of existing methods to endow models with robust reasoning capacity for long-tail and challenging cases. Efforts to address this via reinforcement learning strategies like Group Relative Policy Optimization (GRPO) often suffer from sparse terminal rewards, offering insufficient guidance for multi-step reasoning and slowing convergence. To address these challenges, we propose TaoSR-AGRL, an Adaptive Guided Reinforcement Learning framework for LLM-based relevance prediction in Taobao Search Relevance. TaoSR-AGRL introduces two key innovations: (1) Rule-aware Reward Shaping, which decomposes the final relevance judgment into dense, structured rewards aligned with domain-specific relevance criteria; and (2) Adaptive Guided Replay, which identifies low-accuracy rollouts during training and injects targeted ground-truth guidance to steer the policy away from stagnant, rule-violating reasoning patterns toward compliant trajectories. TaoSR-AGRL was evaluated on large-scale real-world datasets and through online side-by-side human evaluations on Taobao Search. It consistently outperforms DPO and standard GRPO baselines in offline experiments, improving relevance accuracy, rule adherence, and training stability. The model trained with TaoSR-AGRL has been successfully deployed in the main search scenario on Taobao, serving hundreds of millions of users.
TaoSR1: The Thinking Model for E-commerce Relevance Search
Aug 17, 2025



Query-product relevance prediction is a core task in e-commerce search. BERT-based models excel at semantic matching but lack complex reasoning capabilities. While Large Language Models (LLMs) are explored, most still use discriminative fine-tuning or distill to smaller models for deployment. We propose a framework to directly deploy LLMs for this task, addressing key challenges: Chain-of-Thought (CoT) error accumulation, discriminative hallucination, and deployment feasibility. Our framework, TaoSR1, involves three stages: (1) Supervised Fine-Tuning (SFT) with CoT to instill reasoning; (2) Offline sampling with a pass@N strategy and Direct Preference Optimization (DPO) to improve generation quality; and (3) Difficulty-based dynamic sampling with Group Relative Policy Optimization (GRPO) to mitigate discriminative hallucination. Additionally, post-CoT processing and a cumulative probability-based partitioning method enable efficient online deployment. TaoSR1 significantly outperforms baselines on offline datasets and achieves substantial gains in online side-by-side human evaluations, introducing a novel paradigm for applying CoT reasoning to relevance classification.
Tunable Soft Prompts are Messengers in Federated Learning
Nov 12, 2023



Federated learning (FL) enables multiple participants to collaboratively train machine learning models using decentralized data sources, alleviating privacy concerns that arise from directly sharing local data. However, the lack of model privacy protection in FL becomes an unneglectable challenge, especially when people want to federally finetune models based on a proprietary large language model. In this study, we propose a novel FL training approach that accomplishes information exchange among participants via tunable soft prompts. These soft prompts, updated and transmitted between the server and clients, assume the role of the global model parameters and serve as messengers to deliver useful knowledge from the local data and global model. As the global model itself is not required to be shared and the local training is conducted based on an auxiliary model with fewer parameters than the global model, the proposed approach provides protection for the global model while reducing communication and computation costs in FL. Extensive experiments show the effectiveness of the proposed approach compared to several baselines. We have released the source code at \url{https://github.com/alibaba/FederatedScope/tree/fedsp/federatedscope/nlp/fedsp}.
Counterfactual Debiasing for Generating Factually Consistent Text Summaries
May 18, 2023Despite substantial progress in abstractive text summarization to generate fluent and informative texts, the factual inconsistency in the generated summaries remains an important yet challenging problem to be solved. In this paper, we construct causal graphs for abstractive text summarization and identify the intrinsic causes of the factual inconsistency, i.e., the language bias and irrelevancy bias, and further propose a debiasing framework, named CoFactSum, to alleviate the causal effects of these biases by counterfactual estimation. Specifically, the proposed CoFactSum provides two counterfactual estimation strategies, i.e., Explicit Counterfactual Masking with an explicit dynamic masking strategy, and Implicit Counterfactual Training with an implicit discriminative cross-attention mechanism. Meanwhile, we design a Debiasing Degree Adjustment mechanism to dynamically adapt the debiasing degree at each decoding step. Extensive experiments on two widely-used summarization datasets demonstrate the effectiveness of CoFactSum in enhancing the factual consistency of generated summaries compared with several baselines.
Collaborating Heterogeneous Natural Language Processing Tasks via Federated Learning
Dec 12, 2022The increasing privacy concerns on personal private text data promote the development of federated learning (FL) in recent years. However, the existing studies on applying FL in NLP are not suitable to coordinate participants with heterogeneous or private learning objectives. In this study, we further broaden the application scope of FL in NLP by proposing an Assign-Then-Contrast (denoted as ATC) framework, which enables clients with heterogeneous NLP tasks to construct an FL course and learn useful knowledge from each other. Specifically, the clients are suggested to first perform local training with the unified tasks assigned by the server rather than using their own learning objectives, which is called the Assign training stage. After that, in the Contrast training stage, clients train with different local learning objectives and exchange knowledge with other clients who contribute consistent and useful model updates. We conduct extensive experiments on six widely-used datasets covering both Natural Language Understanding (NLU) and Natural Language Generation (NLG) tasks, and the proposed ATC framework achieves significant improvements compared with various baseline methods. The source code is available at \url{https://github.com/alibaba/FederatedScope/tree/master/federatedscope/nlp/hetero_tasks}.
A Benchmark for Federated Hetero-Task Learning
Jun 21, 2022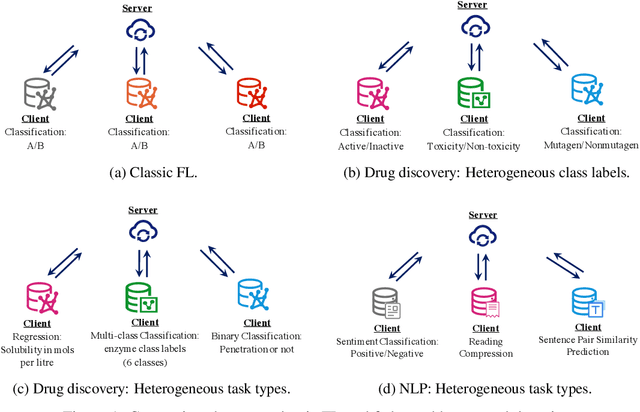
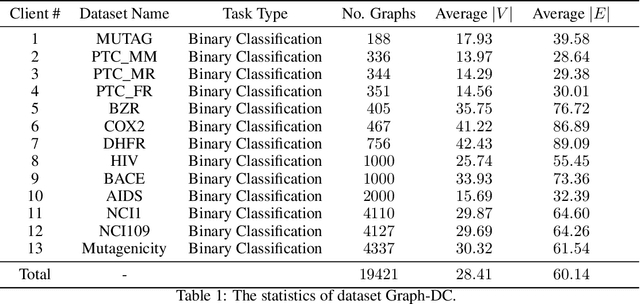
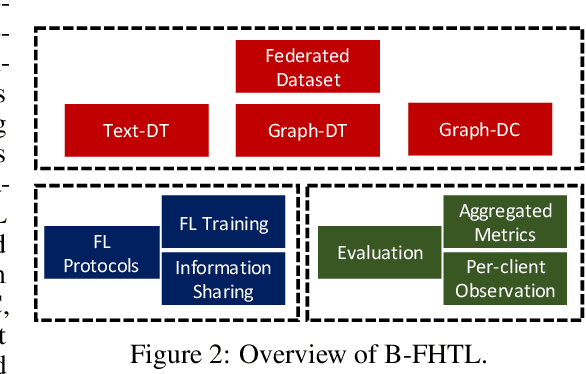
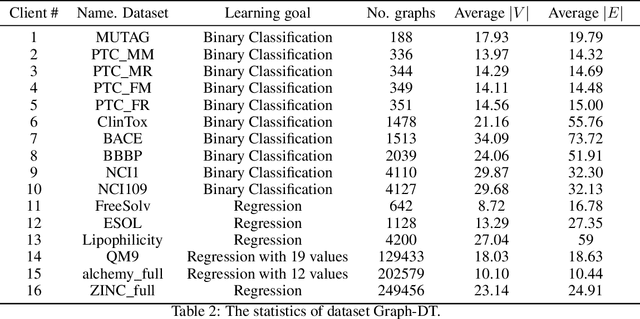
To investigate the heterogeneity in federated learning in real-world scenarios, we generalize the classic federated learning to federated hetero-task learning, which emphasizes the inconsistency across the participants in federated learning in terms of both data distribution and learning tasks. We also present B-FHTL, a federated hetero-task learning benchmark consisting of simulation dataset, FL protocols and a unified evaluation mechanism. B-FHTL dataset contains three well-designed federated learning tasks with increasing heterogeneity. Each task simulates the clients with different non-IID data and learning tasks. To ensure fair comparison among different FL algorithms, B-FHTL builds in a full suite of FL protocols by providing high-level APIs to avoid privacy leakage, and presets most common evaluation metrics spanning across different learning tasks, such as regression, classification, text generation and etc. Furthermore, we compare the FL algorithms in fields of federated multi-task learning, federated personalization and federated meta learning within B-FHTL, and highlight the influence of heterogeneity and difficulties of federated hetero-task learning. Our benchmark, including the federated dataset, protocols, the evaluation mechanism and the preliminary experiment, is open-sourced at https://github.com/alibaba/FederatedScope/tree/master/benchmark/B-FHTL
A Survey of Natural Language Generation
Dec 22, 2021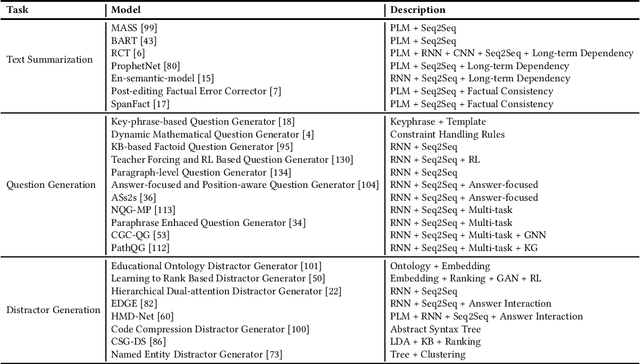

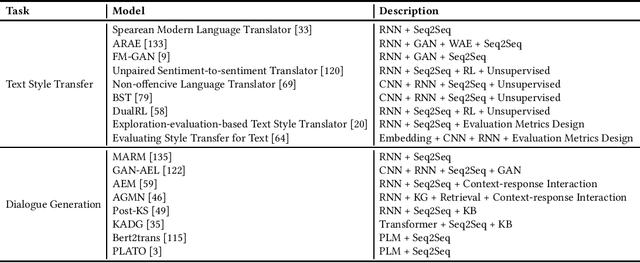
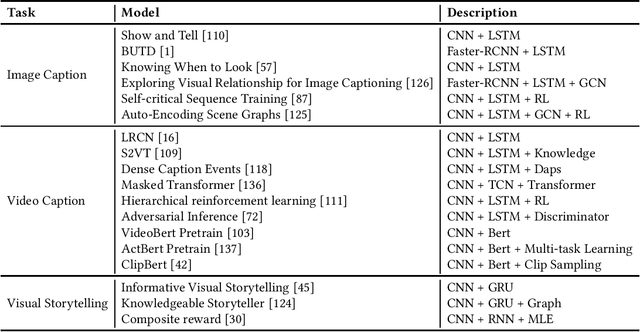
This paper offers a comprehensive review of the research on Natural Language Generation (NLG) over the past two decades, especially in relation to data-to-text generation and text-to-text generation deep learning methods, as well as new applications of NLG technology. This survey aims to (a) give the latest synthesis of deep learning research on the NLG core tasks, as well as the architectures adopted in the field; (b) detail meticulously and comprehensively various NLG tasks and datasets, and draw attention to the challenges in NLG evaluation, focusing on different evaluation methods and their relationships; (c) highlight some future emphasis and relatively recent research issues that arise due to the increasing synergy between NLG and other artificial intelligence areas, such as computer vision, text and computational creativity.
HRKD: Hierarchical Relational Knowledge Distillation for Cross-domain Language Model Compression
Oct 16, 2021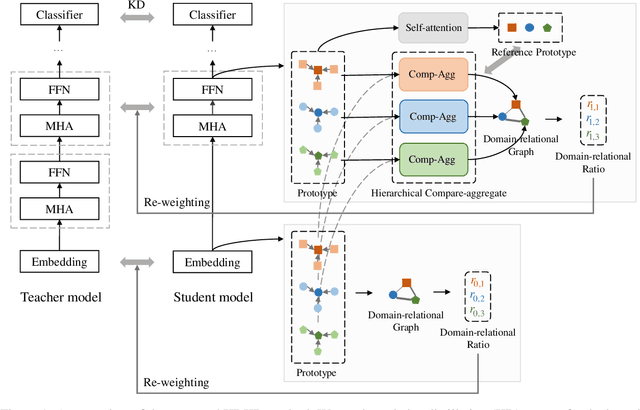
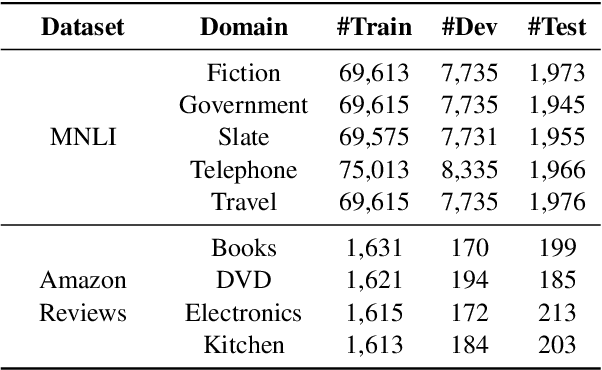
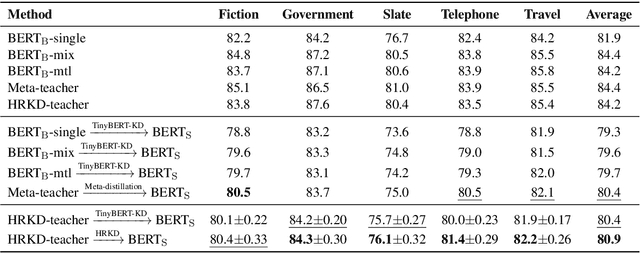
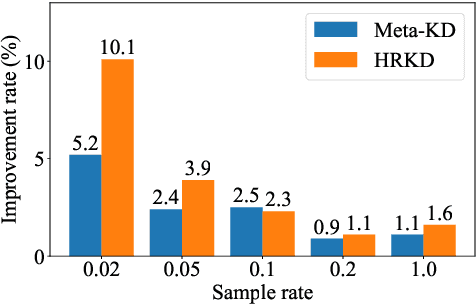
On many natural language processing tasks, large pre-trained language models (PLMs) have shown overwhelming performances compared with traditional neural network methods. Nevertheless, their huge model size and low inference speed have hindered the deployment on resource-limited devices in practice. In this paper, we target to compress PLMs with knowledge distillation, and propose a hierarchical relational knowledge distillation (HRKD) method to capture both hierarchical and domain relational information. Specifically, to enhance the model capability and transferability, we leverage the idea of meta-learning and set up domain-relational graphs to capture the relational information across different domains. And to dynamically select the most representative prototypes for each domain, we propose a hierarchical compare-aggregate mechanism to capture hierarchical relationships. Extensive experiments on public multi-domain datasets demonstrate the superior performance of our HRKD method as well as its strong few-shot learning ability. For reproducibility, we release the code at https://github.com/cheneydon/hrkd.
EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation
Sep 16, 2021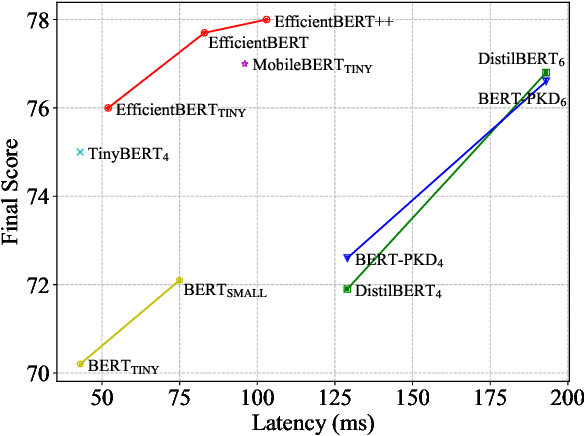

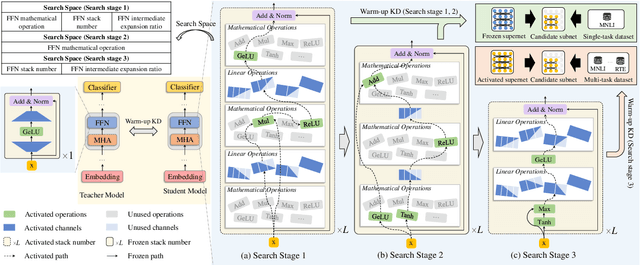
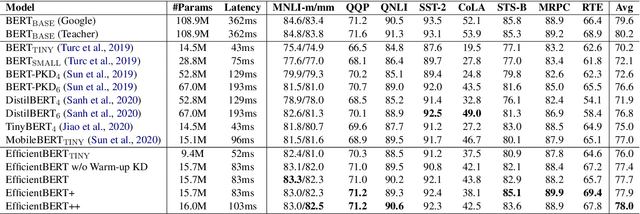
Pre-trained language models have shown remarkable results on various NLP tasks. Nevertheless, due to their bulky size and slow inference speed, it is hard to deploy them on edge devices. In this paper, we have a critical insight that improving the feed-forward network (FFN) in BERT has a higher gain than improving the multi-head attention (MHA) since the computational cost of FFN is 2$\sim$3 times larger than MHA. Hence, to compact BERT, we are devoted to designing efficient FFN as opposed to previous works that pay attention to MHA. Since FFN comprises a multilayer perceptron (MLP) that is essential in BERT optimization, we further design a thorough search space towards an advanced MLP and perform a coarse-to-fine mechanism to search for an efficient BERT architecture. Moreover, to accelerate searching and enhance model transferability, we employ a novel warm-up knowledge distillation strategy at each search stage. Extensive experiments show our searched EfficientBERT is 6.9$\times$ smaller and 4.4$\times$ faster than BERT$\rm_{BASE}$, and has competitive performances on GLUE and SQuAD Benchmarks. Concretely, EfficientBERT attains a 77.7 average score on GLUE \emph{test}, 0.7 higher than MobileBERT$\rm_{TINY}$, and achieves an 85.3/74.5 F1 score on SQuAD v1.1/v2.0 \emph{dev}, 3.2/2.7 higher than TinyBERT$_4$ even without data augmentation. The code is released at https://github.com/cheneydon/efficient-bert.