 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaoSR-AGRL: Adaptive Guided Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance prediction is fundamental to e-commerce search and has become even more critical in the era of AI-powered shopping, where semantic understanding and complex reasoning directly shape the user experience and business conversion. Large Language Models (LLMs) enable generative, reasoning-based approaches, typically aligned via supervised fine-tuning (SFT) or preference optimization methods like Direct Preference Optimization (DPO). However, the increasing complexity of business rules and user queries exposes the inability of existing methods to endow models with robust reasoning capacity for long-tail and challenging cases. Efforts to address this via reinforcement learning strategies like Group Relative Policy Optimization (GRPO) often suffer from sparse terminal rewards, offering insufficient guidance for multi-step reasoning and slowing convergence. To address these challenges, we propose TaoSR-AGRL, an Adaptive Guided Reinforcement Learning framework for LLM-based relevance prediction in Taobao Search Relevance. TaoSR-AGRL introduces two key innovations: (1) Rule-aware Reward Shaping, which decomposes the final relevance judgment into dense, structured rewards aligned with domain-specific relevance criteria; and (2) Adaptive Guided Replay, which identifies low-accuracy rollouts during training and injects targeted ground-truth guidance to steer the policy away from stagnant, rule-violating reasoning patterns toward compliant trajectories. TaoSR-AGRL was evaluated on large-scale real-world datasets and through online side-by-side human evaluations on Taobao Search. It consistently outperforms DPO and standard GRPO baselines in offline experiments, improving relevance accuracy, rule adherence, and training stability. The model trained with TaoSR-AGRL has been successfully deployed in the main search scenario on Taobao, serving hundreds of millions of users.
TaoSR-SHE: Stepwise Hybrid Examination Reinforcement Learning Framework for E-commerce Search Relevance
Oct 09, 2025Query-product relevance analysis is a foundational technology in e-commerce search engines and has become increasingly important in AI-driven e-commerce. The recent emergence of large language models (LLMs), particularly their chain-of-thought (CoT) reasoning capabilities, offers promising opportunities for developing relevance systems that are both more interpretable and more robust. However, existing training paradigms have notable limitations: SFT and DPO suffer from poor generalization on long-tail queries and from a lack of fine-grained, stepwise supervision to enforce rule-aligned reasoning. In contrast, reinforcement learning with verification rewards (RLVR) suffers from sparse feedback, which provides insufficient signal to correct erroneous intermediate steps, thereby undermining logical consistency and limiting performance in complex inference scenarios. To address these challenges, we introduce the Stepwise Hybrid Examination Reinforcement Learning framework for Taobao Search Relevance (TaoSR-SHE). At its core is Stepwise Reward Policy Optimization (SRPO), a reinforcement learning algorithm that leverages step-level rewards generated by a hybrid of a high-quality generative stepwise reward model and a human-annotated offline verifier, prioritizing learning from critical correct and incorrect reasoning steps. TaoSR-SHE further incorporates two key techniques: diversified data filtering to encourage exploration across varied reasoning paths and mitigate policy entropy collapse, and multi-stage curriculum learning to foster progressive capability growth. Extensive experiments on real-world search benchmarks show that TaoSR-SHE improves both reasoning quality and relevance-prediction accuracy in large-scale e-commerce settings, outperforming SFT, DPO, GRPO, and other baselines, while also enhancing interpretability and robustness.
TaoSR1: The Thinking Model for E-commerce Relevance Search
Aug 17, 2025



Query-product relevance prediction is a core task in e-commerce search. BERT-based models excel at semantic matching but lack complex reasoning capabilities. While Large Language Models (LLMs) are explored, most still use discriminative fine-tuning or distill to smaller models for deployment. We propose a framework to directly deploy LLMs for this task, addressing key challenges: Chain-of-Thought (CoT) error accumulation, discriminative hallucination, and deployment feasibility. Our framework, TaoSR1, involves three stages: (1) Supervised Fine-Tuning (SFT) with CoT to instill reasoning; (2) Offline sampling with a pass@N strategy and Direct Preference Optimization (DPO) to improve generation quality; and (3) Difficulty-based dynamic sampling with Group Relative Policy Optimization (GRPO) to mitigate discriminative hallucination. Additionally, post-CoT processing and a cumulative probability-based partitioning method enable efficient online deployment. TaoSR1 significantly outperforms baselines on offline datasets and achieves substantial gains in online side-by-side human evaluations, introducing a novel paradigm for applying CoT reasoning to relevance classification.
Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce
Jul 12, 2024

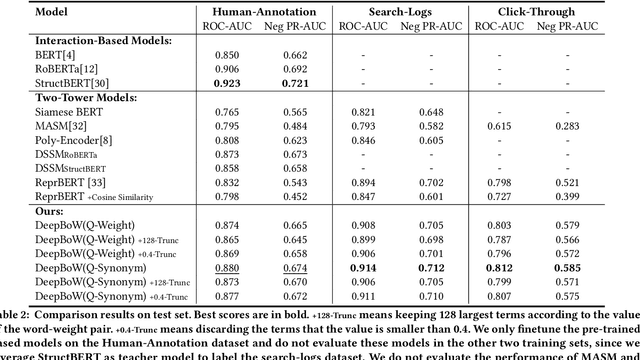

Text relevance or text matching of query and product is an essential technique for the e-commerce search system to ensure that the displayed products can match the intent of the query. Many studies focus on improving the performance of the relevance model in search system. Recently, pre-trained language models like BERT have achieved promising performance on the text relevance task. While these models perform well on the offline test dataset, there are still obstacles to deploy the pre-trained language model to the online system as their high latency. The two-tower model is extensively employed in industrial scenarios, owing to its ability to harmonize performance with computational efficiency. Regrettably, such models present an opaque ``black box'' nature, which prevents developers from making special optimizations. In this paper, we raise deep Bag-of-Words (DeepBoW) model, an efficient and interpretable relevance architecture for Chinese e-commerce. Our approach proposes to encode the query and the product into the sparse BoW representation, which is a set of word-weight pairs. The weight means the important or the relevant score between the corresponding word and the raw text. The relevance score is measured by the accumulation of the matched word between the sparse BoW representation of the query and the product. Compared to popular dense distributed representation that usually suffers from the drawback of black-box, the most advantage of the proposed representation model is highly explainable and interventionable, which is a superior advantage to the deployment and operation of online search engines. Moreover, the online efficiency of the proposed model is even better than the most efficient inner product form of dense representation ...
Learning a Product Relevance Model from Click-Through Data in E-Commerce
Feb 14, 2021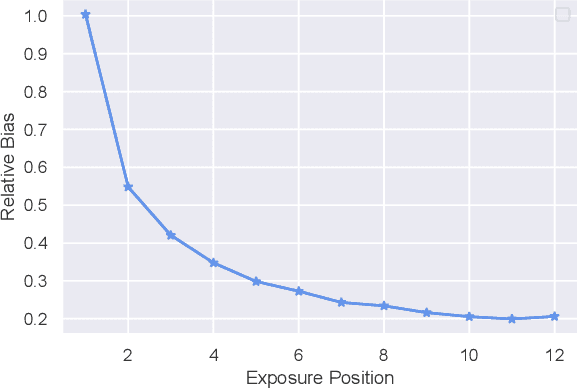

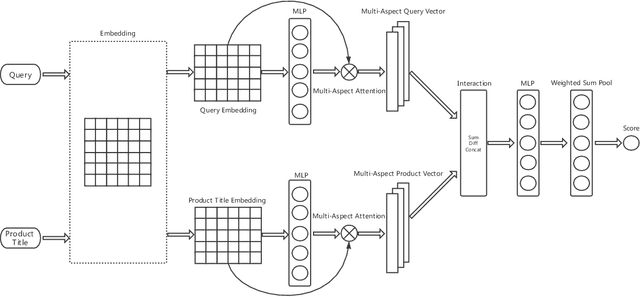
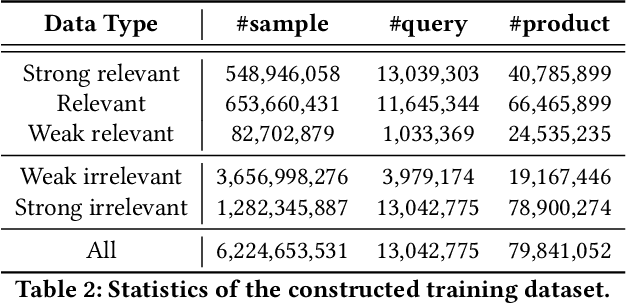
The search engine plays a fundamental role in online e-commerce systems, to help users find the products they want from the massive product collections. Relevance is an essential requirement for e-commerce search, since showing products that do not match search query intent will degrade user experience. With the existence of vocabulary gap between user language of queries and seller language of products, measuring semantic relevance is necessary and neural networks are engaged to address this task. However, semantic relevance is different from click-through rate prediction in that no direct training signal is available. Most previous attempts learn relevance models from user click-through data that are cheap and abundant. Unfortunately, click behavior is noisy and misleading, which is affected by not only relevance but also factors including price, image and attractive titles. Therefore, it is challenging but valuable to learn relevance models from click-through data. In this paper, we propose a new relevance learning framework that concentrates on how to train a relevance model from the weak supervision of click-through data. Different from previous efforts that treat samples as either relevant or irrelevant, we construct more fine-grained samples for training. We propose a novel way to consider samples of different relevance confidence, and come up with a new training objective to learn a robust relevance model with desirable score distribution. The proposed model is evaluated on offline annotated data and online A/B testing, and it achieves both promising performance and high computational efficiency. The model has already been deployed online, serving the search traffic of Taobao for over a year.