 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Product Relevance Model from Click-Through Data in E-Commerce
Paper and Code
Feb 14, 2021

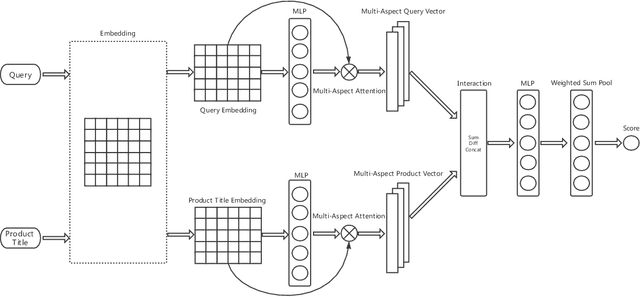
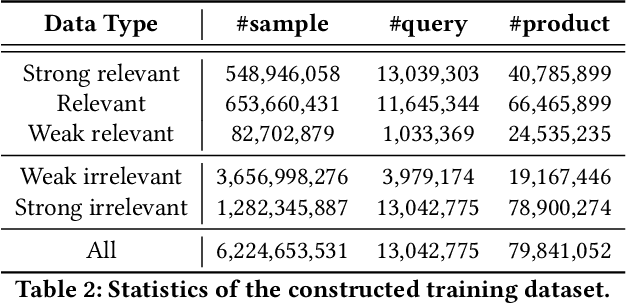
The search engine plays a fundamental role in online e-commerce systems, to help users find the products they want from the massive product collections. Relevance is an essential requirement for e-commerce search, since showing products that do not match search query intent will degrade user experience. With the existence of vocabulary gap between user language of queries and seller language of products, measuring semantic relevance is necessary and neural networks are engaged to address this task. However, semantic relevance is different from click-through rate prediction in that no direct training signal is available. Most previous attempts learn relevance models from user click-through data that are cheap and abundant. Unfortunately, click behavior is noisy and misleading, which is affected by not only relevance but also factors including price, image and attractive titles. Therefore, it is challenging but valuable to learn relevance models from click-through data. In this paper, we propose a new relevance learning framework that concentrates on how to train a relevance model from the weak supervision of click-through data. Different from previous efforts that treat samples as either relevant or irrelevant, we construct more fine-grained samples for training. We propose a novel way to consider samples of different relevance confidence, and come up with a new training objective to learn a robust relevance model with desirable score distribution. The proposed model is evaluated on offline annotated data and online A/B testing, and it achieves both promising performance and high computational efficiency. The model has already been deployed online, serving the search traffic of Taobao for over a year.