 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Paper and Code
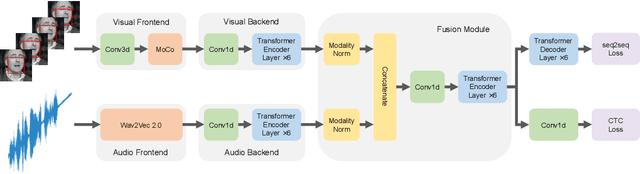
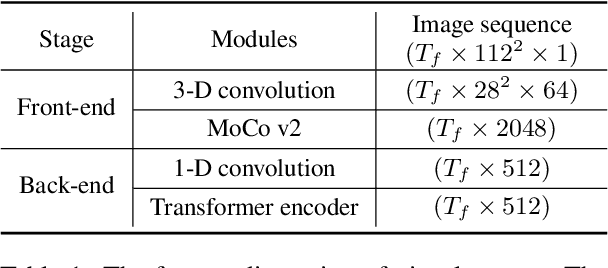


Training Transformer-based models demands a large amount of data, while obtaining aligned and labelled data in multimodality is rather cost-demanding, especially for audio-visual speech recognition (AVSR). Thus it makes a lot of sense to make use of unlabelled unimodal data. On the other side, although the effectiveness of large-scale self-supervised learning is well established in both audio and visual modalities, how to integrate those pre-trained models into a multimodal scenario remains underexplored. In this work, we successfully leverage unimodal self-supervised learning to promote the multimodal AVSR. In particular, audio and visual front-ends are trained on large-scale unimodal datasets, then we integrate components of both front-ends into a larger multimodal framework which learns to recognize parallel audio-visual data into characters through a combination of CTC and seq2seq decoding. We show that both components inherited from unimodal self-supervised learning cooperate well, resulting in that the multimodal framework yields competitive results through fine-tuning. Our model is experimentally validated on both word-level and sentence-level tasks. Especially, even without an external language model, our proposed model raises the state-of-the-art performances on the widely accepted Lip Reading Sentences 2 (LRS2) dataset by a large margin, with a relative improvement of 30%.