 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Camera Calibration Free BEV Representation for 3D Object Detection
Oct 31, 2022



In advanced paradigms of autonomous driving, learning Bird's Eye View (BEV) representation from surrounding views is crucial for multi-task framework. However, existing methods based on depth estimation or camera-driven attention are not stable to obtain transformation under noisy camera parameters, mainly with two challenges, accurate depth prediction and calibration. In this work, we present a completely Multi-Camera Calibration Free Transformer (CFT) for robust BEV representation, which focuses on exploring implicit mapping, not relied on camera intrinsics and extrinsics. To guide better feature learning from image views to BEV, CFT mines potential 3D information in BEV via our designed position-aware enhancement (PA). Instead of camera-driven point-wise or global transformation, for interaction within more effective region and lower computation cost, we propose a view-aware attention which also reduces redundant computation and promotes converge. CFT achieves 49.7% NDS on the nuScenes detection task leaderboard, which is the first work removing camera parameters, comparable to other geometry-guided methods. Without temporal input and other modal information, CFT achieves second highest performance with a smaller image input 1600 * 640. Thanks to view-attention variant, CFT reduces memory and transformer FLOPs for vanilla attention by about 12% and 60%, respectively, with improved NDS by 1.0%. Moreover, its natural robustness to noisy camera parameters makes CFT more competitive.
Efficient and Robust 2D-to-BEV Representation Learning via Geometry-guided Kernel Transformer
Jun 09, 2022
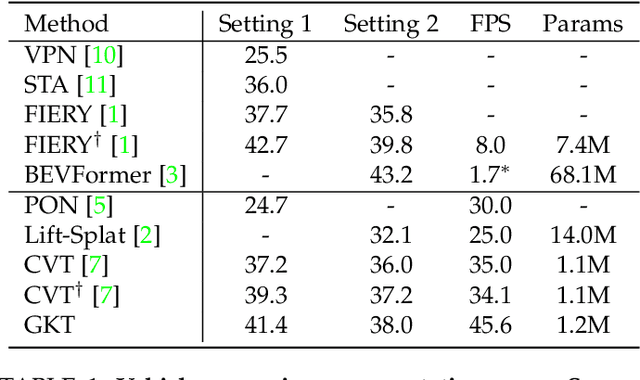


Learning Bird's Eye View (BEV) representation from surrounding-view cameras is of great importance for autonomous driving. In this work, we propose a Geometry-guided Kernel Transformer (GKT), a novel 2D-to-BEV representation learning mechanism. GKT leverages the geometric priors to guide the transformer to focus on discriminative regions and unfolds kernel features to generate BEV representation. For fast inference, we further introduce a look-up table (LUT) indexing method to get rid of the camera's calibrated parameters at runtime. GKT can run at $72.3$ FPS on 3090 GPU / $45.6$ FPS on 2080ti GPU and is robust to the camera deviation and the predefined BEV height. And GKT achieves the state-of-the-art real-time segmentation results, i.e., 38.0 mIoU (100m$\times$100m perception range at a 0.5m resolution) on the nuScenes val set. Given the efficiency, effectiveness, and robustness, GKT has great practical values in autopilot scenarios, especially for real-time running systems. Code and models will be available at \url{https://github.com/hustvl/GKT}.
Deep Online Correction for Monocular Visual Odometry
Mar 18, 2021



In this work, we propose a novel deep online correction (DOC) framework for monocular visual odometry. The whole pipeline has two stages: First, depth maps and initial poses are obtained from convolutional neural networks (CNNs) trained in self-supervised manners. Second, the poses predicted by CNNs are further improved by minimizing photometric errors via gradient updates of poses during inference phases. The benefits of our proposed method are twofold: 1) Different from online-learning methods, DOC does not need to calculate gradient propagation for parameters of CNNs. Thus, it saves more computation resources during inference phases. 2) Unlike hybrid methods that combine CNNs with traditional methods, DOC fully relies on deep learning (DL) frameworks. Though without complex back-end optimization modules, our method achieves outstanding performance with relative transform error (RTE) = 2.0% on KITTI Odometry benchmark for Seq. 09, which outperforms traditional monocular VO frameworks and is comparable to hybrid methods.
VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing
Jul 12, 2019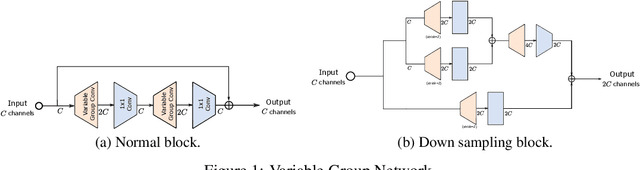
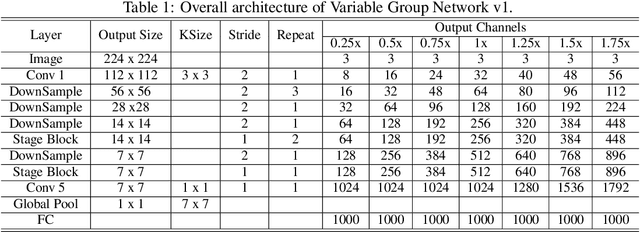
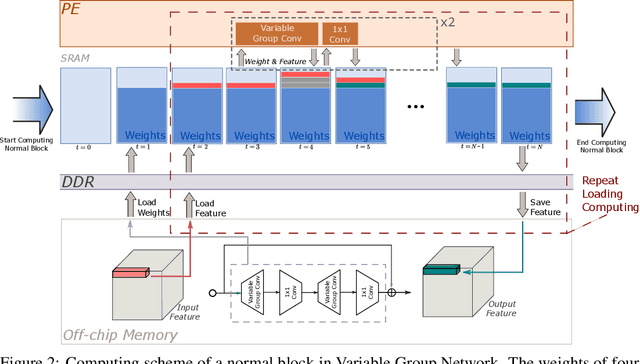
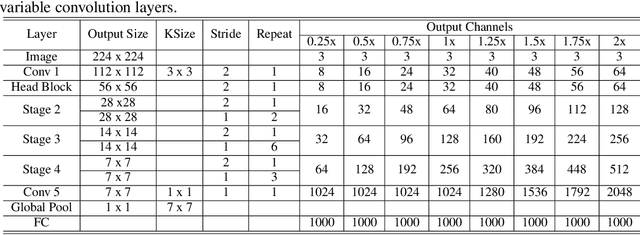
In this paper, we propose a novel network design mechanism for efficient embedded computing. Inspired by the limited computing patterns, we propose to fix the number of channels in a group convolution, instead of the existing practice that fixing the total group numbers. Our solution based network, named Variable Group Convolutional Network (VarGNet), can be optimized easier on hardware side, due to the more unified computing schemes among the layers. Extensive experiments on various vision tasks, including classification, detection, pixel-wise parsing and face recognition, have demonstrated the practical value of our VarGNet.