 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Camera Calibration Free BEV Representation for 3D Object Detection
Oct 31, 2022



In advanced paradigms of autonomous driving, learning Bird's Eye View (BEV) representation from surrounding views is crucial for multi-task framework. However, existing methods based on depth estimation or camera-driven attention are not stable to obtain transformation under noisy camera parameters, mainly with two challenges, accurate depth prediction and calibration. In this work, we present a completely Multi-Camera Calibration Free Transformer (CFT) for robust BEV representation, which focuses on exploring implicit mapping, not relied on camera intrinsics and extrinsics. To guide better feature learning from image views to BEV, CFT mines potential 3D information in BEV via our designed position-aware enhancement (PA). Instead of camera-driven point-wise or global transformation, for interaction within more effective region and lower computation cost, we propose a view-aware attention which also reduces redundant computation and promotes converge. CFT achieves 49.7% NDS on the nuScenes detection task leaderboard, which is the first work removing camera parameters, comparable to other geometry-guided methods. Without temporal input and other modal information, CFT achieves second highest performance with a smaller image input 1600 * 640. Thanks to view-attention variant, CFT reduces memory and transformer FLOPs for vanilla attention by about 12% and 60%, respectively, with improved NDS by 1.0%. Moreover, its natural robustness to noisy camera parameters makes CFT more competitive.
Vision-based Uneven BEV Representation Learning with Polar Rasterization and Surface Estimation
Jul 05, 2022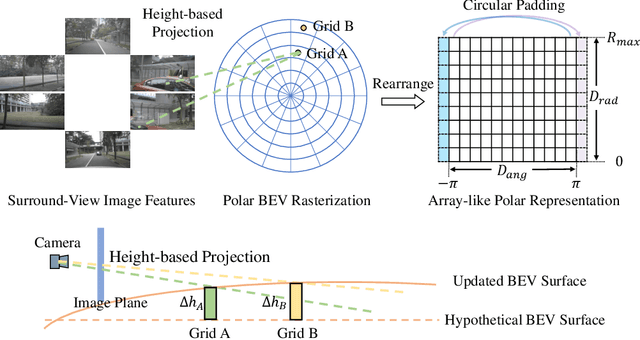



In this work, we propose PolarBEV for vision-based uneven BEV representation learning. To adapt to the foreshortening effect of camera imaging, we rasterize the BEV space both angularly and radially, and introduce polar embedding decomposition to model the associations among polar grids. Polar grids are rearranged to an array-like regular representation for efficient processing. Besides, to determine the 2D-to-3D correspondence, we iteratively update the BEV surface based on a hypothetical plane, and adopt height-based feature transformation. PolarBEV keeps real-time inference speed on a single 2080Ti GPU, and outperforms other methods for both BEV semantic segmentation and BEV instance segmentation. Thorough ablations are presented to validate the design. The code will be released at \url{https://github.com/SuperZ-Liu/PolarBEV}.
Deep Online Correction for Monocular Visual Odometry
Mar 18, 2021



In this work, we propose a novel deep online correction (DOC) framework for monocular visual odometry. The whole pipeline has two stages: First, depth maps and initial poses are obtained from convolutional neural networks (CNNs) trained in self-supervised manners. Second, the poses predicted by CNNs are further improved by minimizing photometric errors via gradient updates of poses during inference phases. The benefits of our proposed method are twofold: 1) Different from online-learning methods, DOC does not need to calculate gradient propagation for parameters of CNNs. Thus, it saves more computation resources during inference phases. 2) Unlike hybrid methods that combine CNNs with traditional methods, DOC fully relies on deep learning (DL) frameworks. Though without complex back-end optimization modules, our method achieves outstanding performance with relative transform error (RTE) = 2.0% on KITTI Odometry benchmark for Seq. 09, which outperforms traditional monocular VO frameworks and is comparable to hybrid methods.