 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Dynamic Scenes in Ego Centric 4D Point Clouds
Aug 12, 2025Understanding dynamic 4D scenes from an egocentric perspective-modeling changes in 3D spatial structure over time-is crucial for human-machine interaction, autonomous navigation, and embodied intelligence. While existing egocentric datasets contain dynamic scenes, they lack unified 4D annotations and task-driven evaluation protocols for fine-grained spatio-temporal reasoning, especially on motion of objects and human, together with their interactions. To address this gap, we introduce EgoDynamic4D, a novel QA benchmark on highly dynamic scenes, comprising RGB-D video, camera poses, globally unique instance masks, and 4D bounding boxes. We construct 927K QA pairs accompanied by explicit Chain-of-Thought (CoT), enabling verifiable, step-by-step spatio-temporal reasoning. We design 12 dynamic QA tasks covering agent motion, human-object interaction, trajectory prediction, relation understanding, and temporal-causal reasoning, with fine-grained, multidimensional metrics. To tackle these tasks, we propose an end-to-end spatio-temporal reasoning framework that unifies dynamic and static scene information, using instance-aware feature encoding, time and camera encoding, and spatially adaptive down-sampling to compress large 4D scenes into token sequences manageable by LLMs. Experiments on EgoDynamic4D show that our method consistently outperforms baselines, validating the effectiveness of multimodal temporal modeling for egocentric dynamic scene understanding.
Pointmap Association and Piecewise-Plane Constraint for Consistent and Compact 3D Gaussian Segmentation Field
Feb 22, 2025Achieving a consistent and compact 3D segmentation field is crucial for maintaining semantic coherence across views and accurately representing scene structures. Previous 3D scene segmentation methods rely on video segmentation models to address inconsistencies across views, but the absence of spatial information often leads to object misassociation when object temporarily disappear and reappear. Furthermore, in the process of 3D scene reconstruction, segmentation and optimization are often treated as separate tasks. As a result, optimization typically lacks awareness of semantic category information, which can result in floaters with ambiguous segmentation. To address these challenges, we introduce CCGS, a method designed to achieve both view consistent 2D segmentation and a compact 3D Gaussian segmentation field. CCGS incorporates pointmap association and a piecewise-plane constraint. First, we establish pixel correspondence between adjacent images by minimizing the Euclidean distance between their pointmaps. We then redefine object mask overlap accordingly. The Hungarian algorithm is employed to optimize mask association by minimizing the total matching cost, while allowing for partial matches. To further enhance compactness, the piecewise-plane constraint restricts point displacement within local planes during optimization, thereby preserving structural integrity. Experimental results on ScanNet and Replica datasets demonstrate that CCGS outperforms existing methods in both 2D panoptic segmentation and 3D Gaussian segmentation.
Ego3DT: Tracking Every 3D Object in Ego-centric Videos
Oct 11, 2024
The growing interest in embodied intelligence has brought ego-centric perspectives to contemporary research. One significant challenge within this realm is the accurate localization and tracking of objects in ego-centric videos, primarily due to the substantial variability in viewing angles. Addressing this issue, this paper introduces a novel zero-shot approach for the 3D reconstruction and tracking of all objects from the ego-centric video. We present Ego3DT, a novel framework that initially identifies and extracts detection and segmentation information of objects within the ego environment. Utilizing information from adjacent video frames, Ego3DT dynamically constructs a 3D scene of the ego view using a pre-trained 3D scene reconstruction model. Additionally, we have innovated a dynamic hierarchical association mechanism for creating stable 3D tracking trajectories of objects in ego-centric videos. Moreover, the efficacy of our approach is corroborated by extensive experiments on two newly compiled datasets, with 1.04x - 2.90x in HOTA, showcasing the robustness and accuracy of our method in diverse ego-centric scenarios.
CityCraft: A Real Crafter for 3D City Generation
Jun 07, 2024



City scene generation has gained significant attention in autonomous driving, smart city development, and traffic simulation. It helps enhance infrastructure planning and monitoring solutions. Existing methods have employed a two-stage process involving city layout generation, typically using Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), or Transformers, followed by neural rendering. These techniques often exhibit limited diversity and noticeable artifacts in the rendered city scenes. The rendered scenes lack variety, resembling the training images, resulting in monotonous styles. Additionally, these methods lack planning capabilities, leading to less realistic generated scenes. In this paper, we introduce CityCraft, an innovative framework designed to enhance both the diversity and quality of urban scene generation. Our approach integrates three key stages: initially, a diffusion transformer (DiT) model is deployed to generate diverse and controllable 2D city layouts. Subsequently, a Large Language Model(LLM) is utilized to strategically make land-use plans within these layouts based on user prompts and language guidelines. Based on the generated layout and city plan, we utilize the asset retrieval module and Blender for precise asset placement and scene construction. Furthermore, we contribute two new datasets to the field: 1)CityCraft-OSM dataset including 2D semantic layouts of urban areas, corresponding satellite images, and detailed annotations. 2) CityCraft-Buildings dataset, featuring thousands of diverse, high-quality 3D building assets. CityCraft achieves state-of-the-art performance in generating realistic 3D cities.
See and Think: Embodied Agent in Virtual Environment
Dec 03, 2023



Large language models (LLMs) have achieved impressive progress on several open-world tasks. Recently, using LLMs to build embodied agents has been a hotspot. In this paper, we propose STEVE, a comprehensive and visionary embodied agent in the Minecraft virtual environment. STEVE consists of three key components: vision perception, language instruction, and code action. Vision perception involves the interpretation of visual information in the environment, which is then integrated into the LLMs component with agent state and task instruction. Language instruction is responsible for iterative reasoning and decomposing complex tasks into manageable guidelines. Code action generates executable skill actions based on retrieval in skill database, enabling the agent to interact effectively within the Minecraft environment. We also collect STEVE-21K dataset, which includes 600$+$ vision-environment pairs, 20K knowledge question-answering pairs, and 200$+$ skill-code pairs. We conduct continuous block search, knowledge question and answering, and tech tree mastery to evaluate the performance. Extensive experiments show that STEVE achieves at most $1.5 \times$ faster unlocking key tech trees and $2.5 \times$ quicker in block search tasks compared to previous state-of-the-art methods.
Vision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving
Nov 17, 2023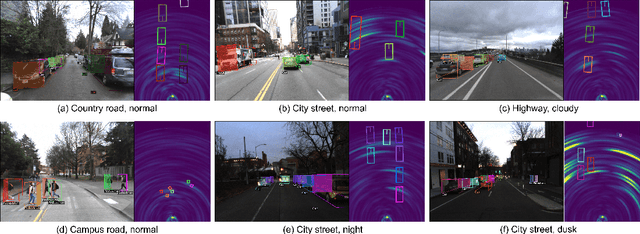
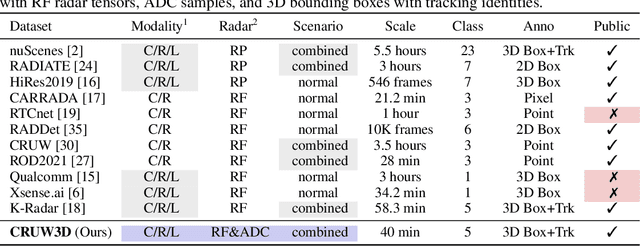

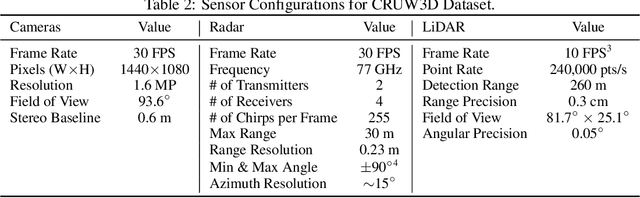
Sensor fusion is crucial for an accurate and robust perception system on autonomous vehicles. Most existing datasets and perception solutions focus on fusing cameras and LiDAR. However, the collaboration between camera and radar is significantly under-exploited. The incorporation of rich semantic information from the camera, and reliable 3D information from the radar can potentially achieve an efficient, cheap, and portable solution for 3D object perception tasks. It can also be robust to different lighting or all-weather driving scenarios due to the capability of mmWave radars. In this paper, we introduce the CRUW3D dataset, including 66K synchronized and well-calibrated camera, radar, and LiDAR frames in various driving scenarios. Unlike other large-scale autonomous driving datasets, our radar data is in the format of radio frequency (RF) tensors that contain not only 3D location information but also spatio-temporal semantic information. This kind of radar format can enable machine learning models to generate more reliable object perception results after interacting and fusing the information or features between the camera and radar.
A Survey of Deep Learning in Sports Applications: Perception, Comprehension, and Decision
Jul 07, 2023Deep learning has the potential to revolutionize sports performance, with applications ranging from perception and comprehension to decision. This paper presents a comprehensive survey of deep learning in sports performance, focusing on three main aspects: algorithms, datasets and virtual environments, and challenges. Firstly, we discuss the hierarchical structure of deep learning algorithms in sports performance which includes perception, comprehension and decision while comparing their strengths and weaknesses. Secondly, we list widely used existing datasets in sports and highlight their characteristics and limitations. Finally, we summarize current challenges and point out future trends of deep learning in sports. Our survey provides valuable reference material for researchers interested in deep learning in sports applications.
DiffFashion: Reference-based Fashion Design with Structure-aware Transfer by Diffusion Models
Feb 14, 2023Image-based fashion design with AI techniques has attracted increasing attention in recent years. We focus on a new fashion design task, where we aim to transfer a reference appearance image onto a clothing image while preserving the structure of the clothing image. It is a challenging task since there are no reference images available for the newly designed output fashion images. Although diffusion-based image translation or neural style transfer (NST) has enabled flexible style transfer, it is often difficult to maintain the original structure of the image realistically during the reverse diffusion, especially when the referenced appearance image greatly differs from the common clothing appearance. To tackle this issue, we present a novel diffusion model-based unsupervised structure-aware transfer method to semantically generate new clothes from a given clothing image and a reference appearance image. In specific, we decouple the foreground clothing with automatically generated semantic masks by conditioned labels. And the mask is further used as guidance in the denoising process to preserve the structure information. Moreover, we use the pre-trained vision Transformer (ViT) for both appearance and structure guidance. Our experimental results show that the proposed method outperforms state-of-the-art baseline models, generating more realistic images in the fashion design task. Code and demo can be found at https://github.com/Rem105-210/DiffFashion.