 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Online 3D Multi-Object Tracking through Camera-Radar Cross Check
Jul 18, 2024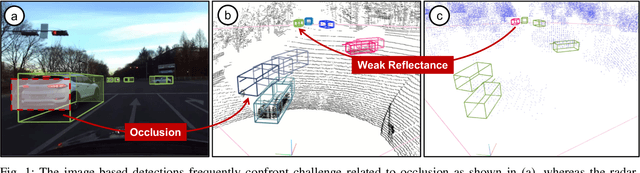
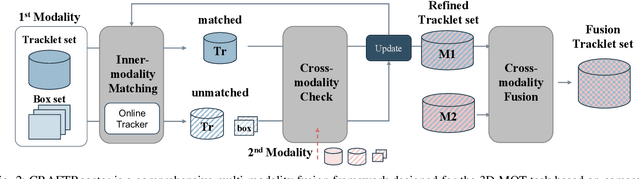
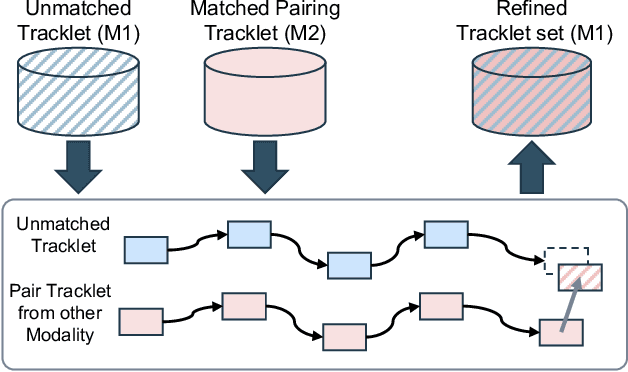
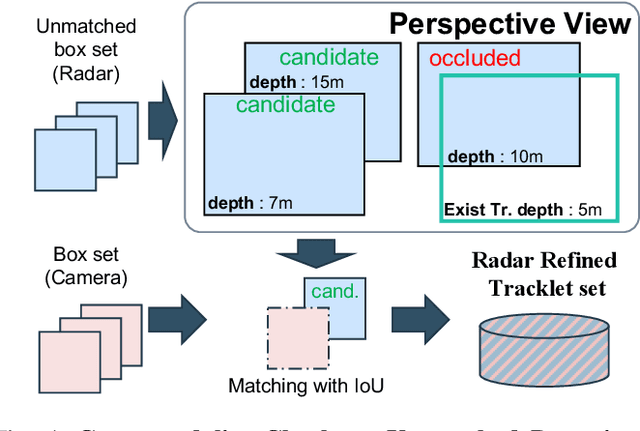
In the domain of autonomous driving, the integration of multi-modal perception techniques based on data from diverse sensors has demonstrated substantial progress. Effectively surpassing the capabilities of state-of-the-art single-modality detectors through sensor fusion remains an active challenge. This work leverages the respective advantages of cameras in perspective view and radars in Bird's Eye View (BEV) to greatly enhance overall detection and tracking performance. Our approach, Camera-Radar Associated Fusion Tracking Booster (CRAFTBooster), represents a pioneering effort to enhance radar-camera fusion in the tracking stage, contributing to improved 3D MOT accuracy. The superior experimental results on the K-Radaar dataset, which exhibit 5-6% on IDF1 tracking performance gain, validate the potential of effective sensor fusion in advancing autonomous driving.
The 2nd Workshop on Maritime Computer Vision 2024
Nov 23, 2023



The 2nd Workshop on Maritime Computer Vision (MaCVi) 2024 addresses maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicles (USV). Three challenges categories are considered: (i) UAV-based Maritime Object Tracking with Re-identification, (ii) USV-based Maritime Obstacle Segmentation and Detection, (iii) USV-based Maritime Boat Tracking. The USV-based Maritime Obstacle Segmentation and Detection features three sub-challenges, including a new embedded challenge addressing efficicent inference on real-world embedded devices. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 195 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi24.
Vision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving
Nov 17, 2023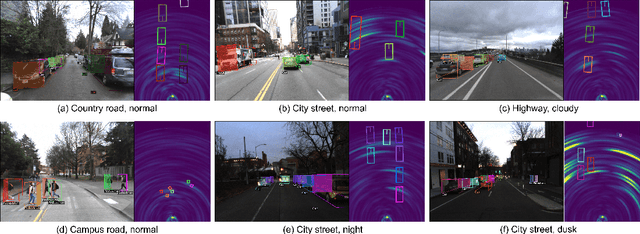
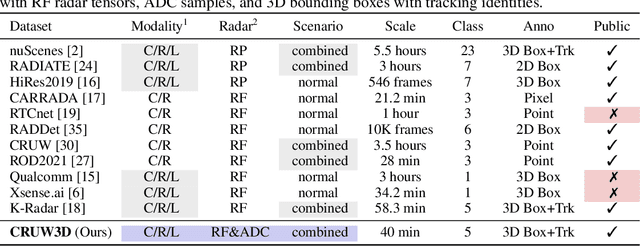

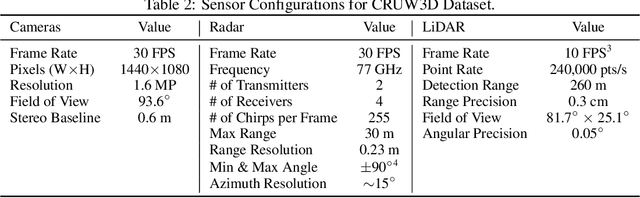
Sensor fusion is crucial for an accurate and robust perception system on autonomous vehicles. Most existing datasets and perception solutions focus on fusing cameras and LiDAR. However, the collaboration between camera and radar is significantly under-exploited. The incorporation of rich semantic information from the camera, and reliable 3D information from the radar can potentially achieve an efficient, cheap, and portable solution for 3D object perception tasks. It can also be robust to different lighting or all-weather driving scenarios due to the capability of mmWave radars. In this paper, we introduce the CRUW3D dataset, including 66K synchronized and well-calibrated camera, radar, and LiDAR frames in various driving scenarios. Unlike other large-scale autonomous driving datasets, our radar data is in the format of radio frequency (RF) tensors that contain not only 3D location information but also spatio-temporal semantic information. This kind of radar format can enable machine learning models to generate more reliable object perception results after interacting and fusing the information or features between the camera and radar.
CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar
Nov 04, 2023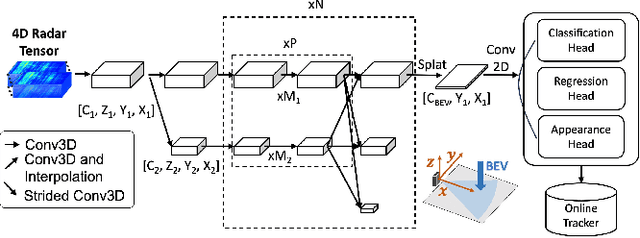
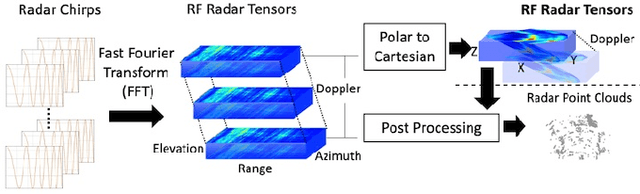
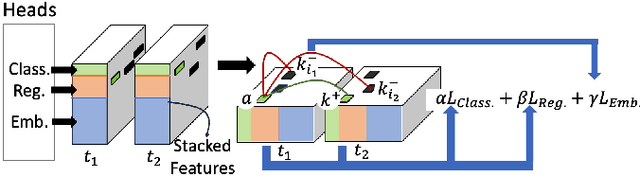
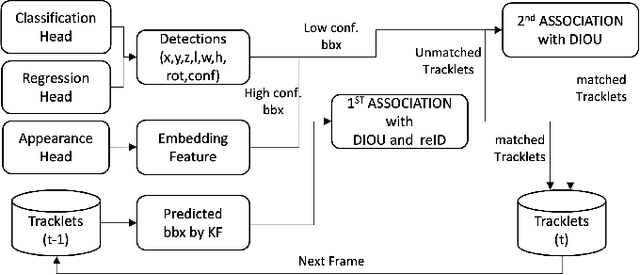
Robust perception is a vital component for ensuring safe autonomous and assisted driving. Automotive radar (77 to 81 GHz), which offers weather-resilient sensing, provides a complementary capability to the vision- or LiDAR-based autonomous driving systems. Raw radio-frequency (RF) radar tensors contain rich spatiotemporal semantics besides 3D location information. The majority of previous methods take in 3D (Doppler-range-azimuth) RF radar tensors, allowing prediction of an object's location, heading angle, and size in bird's-eye-view (BEV). However, they lack the ability to at the same time infer objects' size, orientation, and identity in the 3D space. To overcome this limitation, we propose an efficient joint architecture called CenterRadarNet, designed to facilitate high-resolution representation learning from 4D (Doppler-range-azimuth-elevation) radar data for 3D object detection and re-identification (re-ID) tasks. As a single-stage 3D object detector, CenterRadarNet directly infers the BEV object distribution confidence maps, corresponding 3D bounding box attributes, and appearance embedding for each pixel. Moreover, we build an online tracker utilizing the learned appearance embedding for re-ID. CenterRadarNet achieves the state-of-the-art result on the K-Radar 3D object detection benchmark. In addition, we present the first 3D object-tracking result using radar on the K-Radar dataset V2. In diverse driving scenarios, CenterRadarNet shows consistent, robust performance, emphasizing its wide applicability.