 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Joint Multimodal Entity-Relation Extraction via Knowledge-Enhanced Cross-modal Prompt Model
Paper and Code
Oct 18, 2024


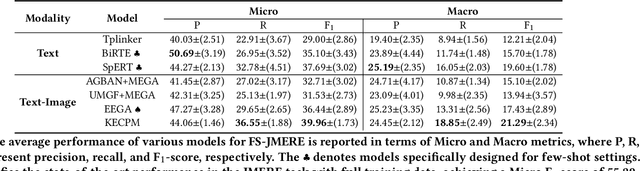
Joint Multimodal Entity-Relation Extraction (JMERE) is a challenging task that aims to extract entities and their relations from text-image pairs in social media posts. Existing methods for JMERE require large amounts of labeled data. However, gathering and annotating fine-grained multimodal data for JMERE poses significant challenges. Initially, we construct diverse and comprehensive multimodal few-shot datasets fitted to the original data distribution. To address the insufficient information in the few-shot setting, we introduce the \textbf{K}nowledge-\textbf{E}nhanced \textbf{C}ross-modal \textbf{P}rompt \textbf{M}odel (KECPM) for JMERE. This method can effectively address the problem of insufficient information in the few-shot setting by guiding a large language model to generate supplementary background knowledge. Our proposed method comprises two stages: (1) a knowledge ingestion stage that dynamically formulates prompts based on semantic similarity guide ChatGPT generating relevant knowledge and employs self-reflection to refine the knowledge; (2) a knowledge-enhanced language model stage that merges the auxiliary knowledge with the original input and utilizes a transformer-based model to align with JMERE's required output format. We extensively evaluate our approach on a few-shot dataset derived from the JMERE dataset, demonstrating its superiority over strong baselines in terms of both micro and macro F$_1$ scores. Additionally, we present qualitative analyses and case studies to elucidate the effectiveness of our model.