 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Lifelong Self-Adaptation for Configurable Systems
Jan 01, 2025



Modern configurable systems provide tremendous opportunities for engineering future intelligent software systems. A key difficulty thereof is how to effectively self-adapt the configuration of a running system such that its performance (e.g., runtime and throughput) can be optimized under time-varying workloads. This unfortunately remains unaddressed in existing approaches as they either overlook the available past knowledge or rely on static exploitation of past knowledge without reasoning the usefulness of information when planning for self-adaptation. In this paper, we tackle this challenging problem by proposing DLiSA, a framework that self-adapts configurable systems. DLiSA comes with two properties: firstly, it supports lifelong planning, and thereby the planning process runs continuously throughout the lifetime of the system, allowing dynamic exploitation of the accumulated knowledge for rapid adaptation. Secondly, the planning for a newly emerged workload is boosted via distilled knowledge seeding, in which the knowledge is dynamically purified such that only useful past configurations are seeded when necessary, mitigating misleading information. Extensive experiments suggest that the proposed DLiSA significantly outperforms state-of-the-art approaches, demonstrating a performance improvement of up to 229% and a resource acceleration of up to 2.22x on generating promising adaptation configurations. All data and sources can be found at our repository: https://github.com/ideas-labo/dlisa.
GreenStableYolo: Optimizing Inference Time and Image Quality of Text-to-Image Generation
Jul 20, 2024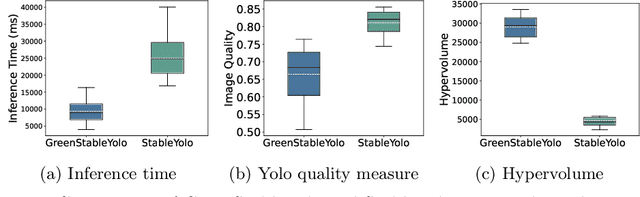
Tuning the parameters and prompts for improving AI-based text-to-image generation has remained a substantial yet unaddressed challenge. Hence we introduce GreenStableYolo, which improves the parameters and prompts for Stable Diffusion to both reduce GPU inference time and increase image generation quality using NSGA-II and Yolo. Our experiments show that despite a relatively slight trade-off (18%) in image quality compared to StableYolo (which only considers image quality), GreenStableYolo achieves a substantial reduction in inference time (266% less) and a 526% higher hypervolume, thereby advancing the state-of-the-art for text-to-image generation.