Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreenStableYolo: Optimizing Inference Time and Image Quality of Text-to-Image Generation
Paper and Code
Jul 20, 2024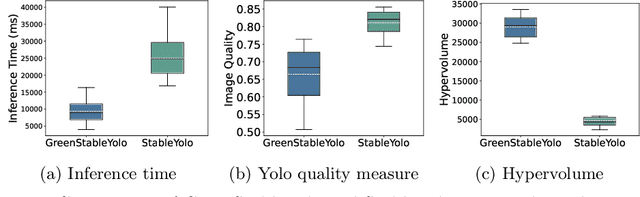
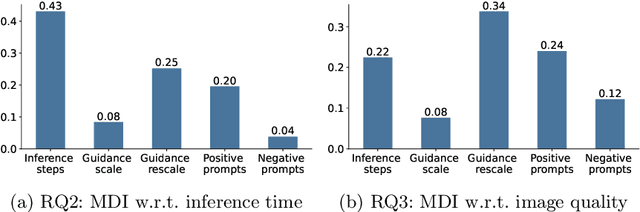
Tuning the parameters and prompts for improving AI-based text-to-image generation has remained a substantial yet unaddressed challenge. Hence we introduce GreenStableYolo, which improves the parameters and prompts for Stable Diffusion to both reduce GPU inference time and increase image generation quality using NSGA-II and Yolo. Our experiments show that despite a relatively slight trade-off (18%) in image quality compared to StableYolo (which only considers image quality), GreenStableYolo achieves a substantial reduction in inference time (266% less) and a 526% higher hypervolume, thereby advancing the state-of-the-art for text-to-image generation.
* This paper is published in the SSBSE Challenge Track 2024
View paper on