 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Configuration Encoding Matter in Learning Software Performance? An Empirical Study on Encoding Schemes
Paper and Code


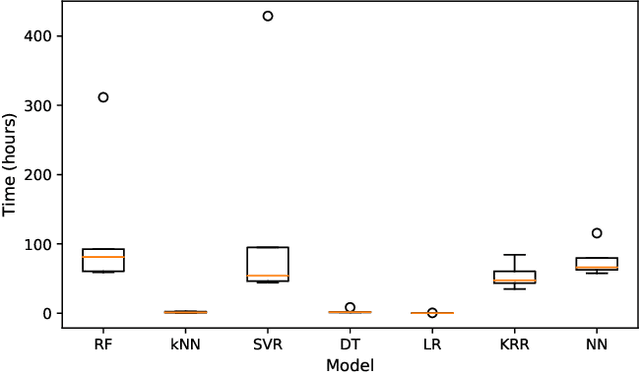

Learning and predicting the performance of a configurable software system helps to provide better quality assurance. One important engineering decision therein is how to encode the configuration into the model built. Despite the presence of different encoding schemes, there is still little understanding of which is better and under what circumstances, as the community often relies on some general beliefs that inform the decision in an ad-hoc manner. To bridge this gap, in this paper, we empirically compared the widely used encoding schemes for software performance learning, namely label, scaled label, and one-hot encoding. The study covers five systems, seven models, and three encoding schemes, leading to 105 cases of investigation. Our key findings reveal that: (1) conducting trial-and-error to find the best encoding scheme in a case by case manner can be rather expensive, requiring up to 400+ hours on some models and systems; (2) the one-hot encoding often leads to the most accurate results while the scaled label encoding is generally weak on accuracy over different models; (3) conversely, the scaled label encoding tends to result in the fastest training time across the models/systems while the one-hot encoding is the slowest; (4) for all models studied, label and scaled label encoding often lead to relatively less biased outcomes between accuracy and training time, but the paired model varies according to the system. We discuss the actionable suggestions derived from our findings, hoping to provide a better understanding of this topic for the community. To promote open science, the data and code of this work can be publicly accessed at https://github.com/ideas-labo/MSR2022-encoding-study.