 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Word Shift Graphs: A Method for Visualizing and Explaining Pairwise Comparisons Between Texts
Aug 05, 2020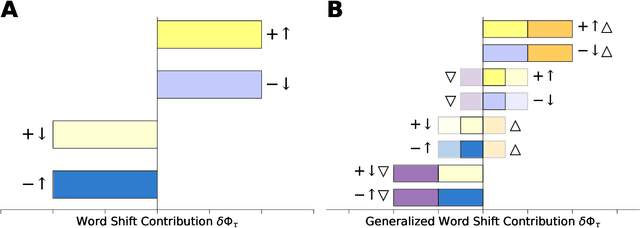
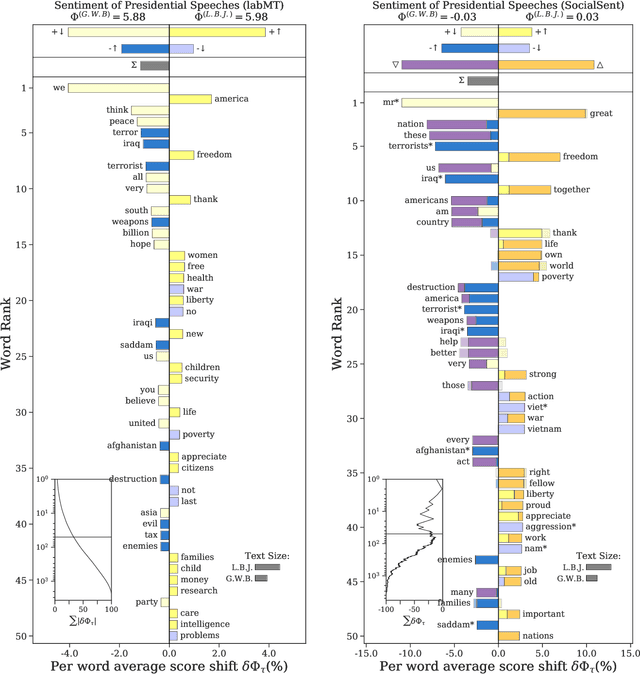
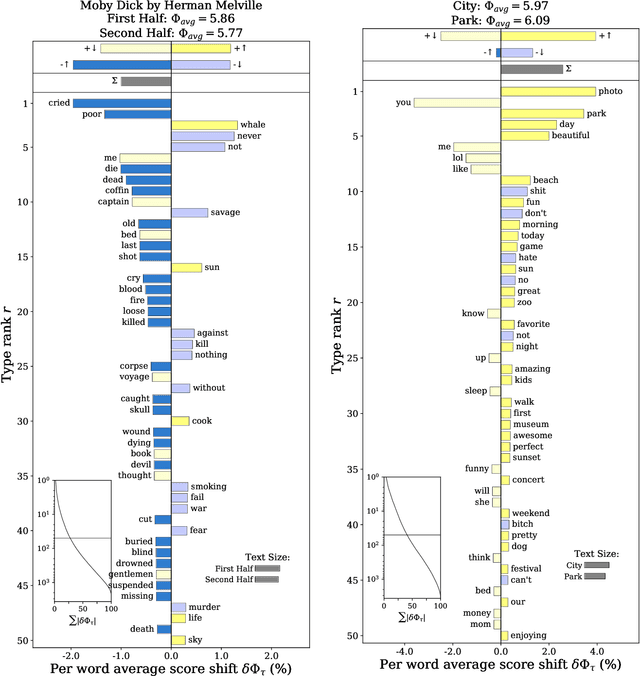
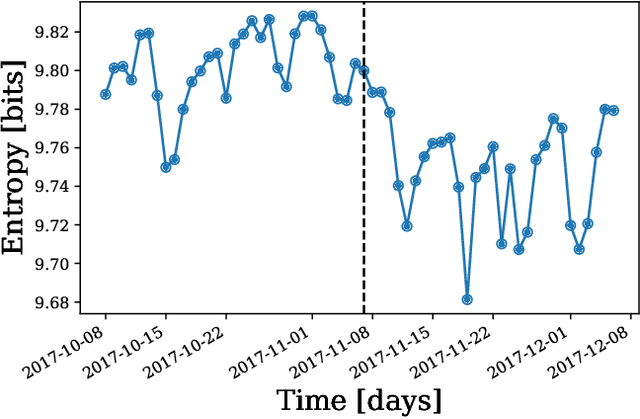
A common task in computational text analyses is to quantify how two corpora differ according to a measurement like word frequency, sentiment, or information content. However, collapsing the texts' rich stories into a single number is often conceptually perilous, and it is difficult to confidently interpret interesting or unexpected textual patterns without looming concerns about data artifacts or measurement validity. To better capture fine-grained differences between texts, we introduce generalized word shift graphs, visualizations which yield a meaningful and interpretable summary of how individual words contribute to the variation between two texts for any measure that can be formulated as a weighted average. We show that this framework naturally encompasses many of the most commonly used approaches for comparing texts, including relative frequencies, dictionary scores, and entropy-based measures like the Kullback-Leibler and Jensen-Shannon divergences. Through several case studies, we demonstrate how generalized word shift graphs can be flexibly applied across domains for diagnostic investigation, hypothesis generation, and substantive interpretation. By providing a detailed lens into textual shifts between corpora, generalized word shift graphs help computational social scientists, digital humanists, and other text analysis practitioners fashion more robust scientific narratives.
Anchored Correlation Explanation: Topic Modeling with Minimal Domain Knowledge
Sep 03, 2018While generative models such as Latent Dirichlet Allocation (LDA) have proven fruitful in topic modeling, they often require detailed assumptions and careful specification of hyperparameters. Such model complexity issues only compound when trying to generalize generative models to incorporate human input. We introduce Correlation Explanation (CorEx), an alternative approach to topic modeling that does not assume an underlying generative model, and instead learns maximally informative topics through an information-theoretic framework. This framework naturally generalizes to hierarchical and semi-supervised extensions with no additional modeling assumptions. In particular, word-level domain knowledge can be flexibly incorporated within CorEx through anchor words, allowing topic separability and representation to be promoted with minimal human intervention. Across a variety of datasets, metrics, and experiments, we demonstrate that CorEx produces topics that are comparable in quality to those produced by unsupervised and semi-supervised variants of LDA.
* 21 pages, 7 figures. 2018/09/03: Updated citation for HA/DR dataset
Divergent discourse between protests and counter-protests: #BlackLivesMatter and #AllLivesMatter
May 20, 2017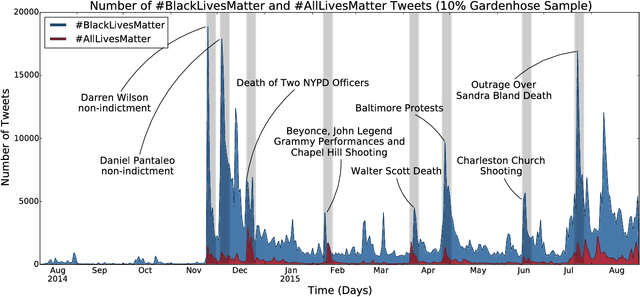
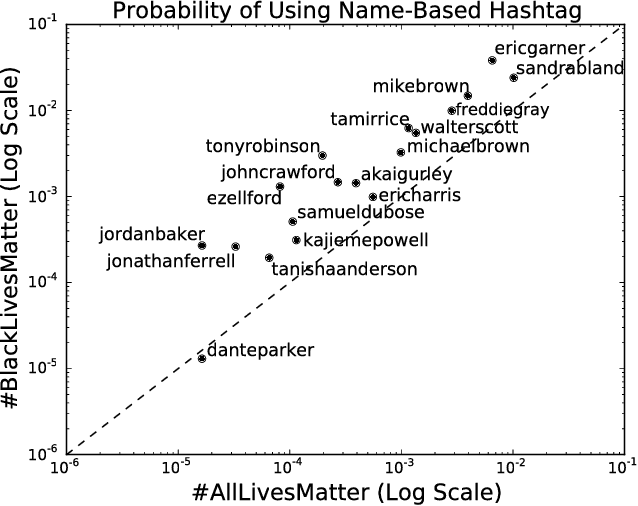
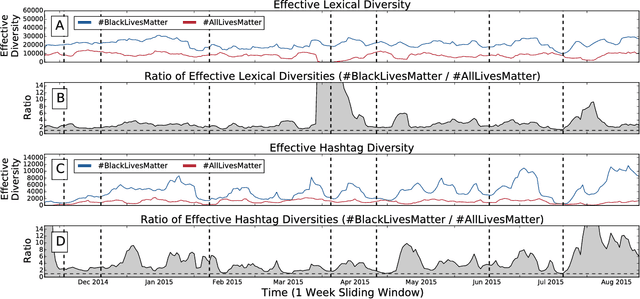
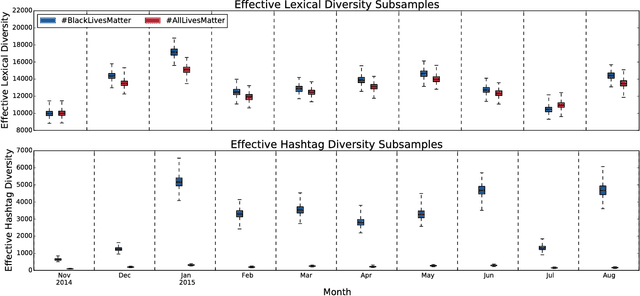
Since the shooting of Black teenager Michael Brown by White police officer Darren Wilson in Ferguson, Missouri, the protest hashtag #BlackLivesMatter has amplified critiques of extrajudicial killings of Black Americans. In response to #BlackLivesMatter, other Twitter users have adopted #AllLivesMatter, a counter-protest hashtag whose content argues that equal attention should be given to all lives regardless of race. Through a multi-level analysis of over 860,000 tweets, we study how these protests and counter-protests diverge by quantifying aspects of their discourse. We find that #AllLivesMatter facilitates opposition between #BlackLivesMatter and hashtags such as #PoliceLivesMatter and #BlueLivesMatter in such a way that historically echoes the tension between Black protesters and law enforcement. In addition, we show that a significant portion of #AllLivesMatter use stems from hijacking by #BlackLivesMatter advocates. Beyond simply injecting #AllLivesMatter with #BlackLivesMatter content, these hijackers use the hashtag to directly confront the counter-protest notion of "All lives matter." Our findings suggest that Black Lives Matter movement was able to grow, exhibit diverse conversations, and avoid derailment on social media by making discussion of counter-protest opinions a central topic of #AllLivesMatter, rather than the movement itself.