 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Sense Of Distributed Representations With Activation Spectroscopy
Jan 26, 2025In the study of neural network interpretability, there is growing evidence to suggest that relevant features are encoded across many neurons in a distributed fashion. Making sense of these distributed representations without knowledge of the network's encoding strategy is a combinatorial task that is not guaranteed to be tractable. This work explores one feasible path to both detecting and tracing the joint influence of neurons in a distributed representation. We term this approach Activation Spectroscopy (ActSpec), owing to its analysis of the pseudo-Boolean Fourier spectrum defined over the activation patterns of a network layer. The sub-network defined between a given layer and an output logit is cast as a special class of pseudo-Boolean function. The contributions of each subset of neurons in the specified layer can be quantified through the function's Fourier coefficients. We propose a combinatorial optimization procedure to search for Fourier coefficients that are simultaneously high-valued, and non-redundant. This procedure can be viewed as an extension of the Goldreich-Levin algorithm which incorporates additional problem-specific constraints. The resulting coefficients specify a collection of subsets, which are used to test the degree to which a representation is distributed. We verify our approach in a number of synthetic settings and compare against existing interpretability benchmarks. We conclude with a number of experimental evaluations on an MNIST classifier, and a transformer-based network for sentiment analysis.
Improving Generalization by Controlling Label-Noise Information in Neural Network Weights
Feb 19, 2020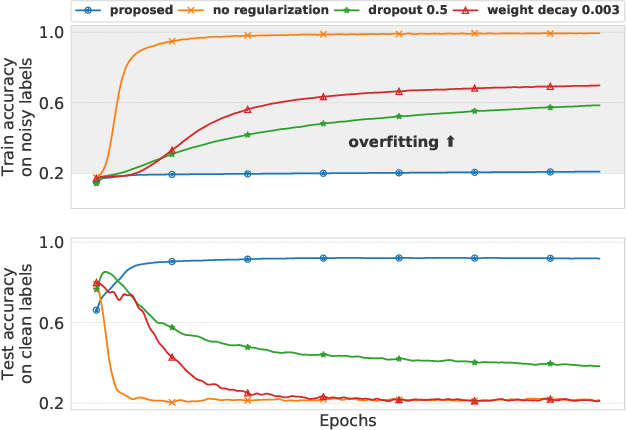
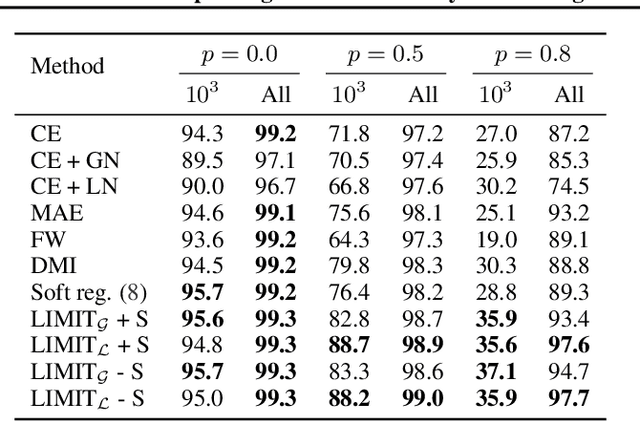
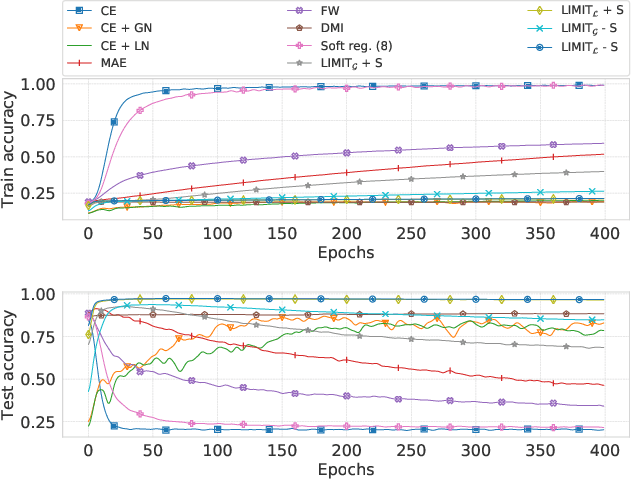
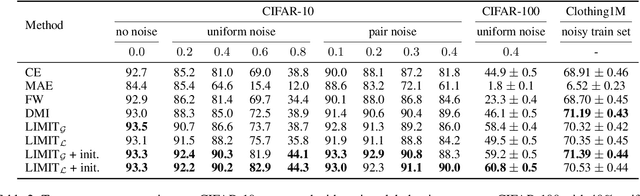
In the presence of noisy or incorrect labels, neural networks have the undesirable tendency to memorize information about the noise. Standard regularization techniques such as dropout, weight decay or data augmentation sometimes help, but do not prevent this behavior. If one considers neural network weights as random variables that depend on the data and stochasticity of training, the amount of memorized information can be quantified with the Shannon mutual information between weights and the vector of all training labels given inputs, $I(w : \mathbf{y} \mid \mathbf{x})$. We show that for any training algorithm, low values of this term correspond to reduction in memorization of label-noise and better generalization bounds. To obtain these low values, we propose training algorithms that employ an auxiliary network that predicts gradients in the final layers of a classifier without accessing labels. We illustrate the effectiveness of our approach on versions of MNIST, CIFAR-10, and CIFAR-100 corrupted with various noise models, and on a large-scale dataset Clothing1M that has noisy labels.
Anchored Correlation Explanation: Topic Modeling with Minimal Domain Knowledge
Sep 03, 2018While generative models such as Latent Dirichlet Allocation (LDA) have proven fruitful in topic modeling, they often require detailed assumptions and careful specification of hyperparameters. Such model complexity issues only compound when trying to generalize generative models to incorporate human input. We introduce Correlation Explanation (CorEx), an alternative approach to topic modeling that does not assume an underlying generative model, and instead learns maximally informative topics through an information-theoretic framework. This framework naturally generalizes to hierarchical and semi-supervised extensions with no additional modeling assumptions. In particular, word-level domain knowledge can be flexibly incorporated within CorEx through anchor words, allowing topic separability and representation to be promoted with minimal human intervention. Across a variety of datasets, metrics, and experiments, we demonstrate that CorEx produces topics that are comparable in quality to those produced by unsupervised and semi-supervised variants of LDA.
* 21 pages, 7 figures. 2018/09/03: Updated citation for HA/DR dataset
Sifting Common Information from Many Variables
Jun 16, 2017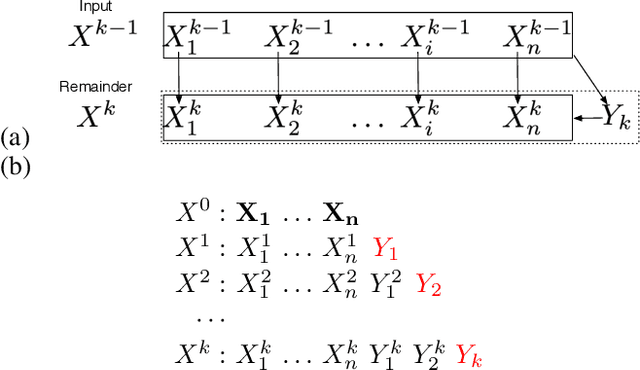
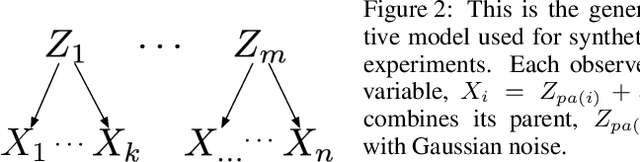
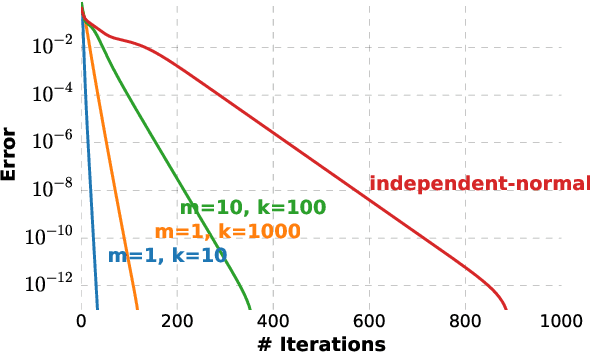
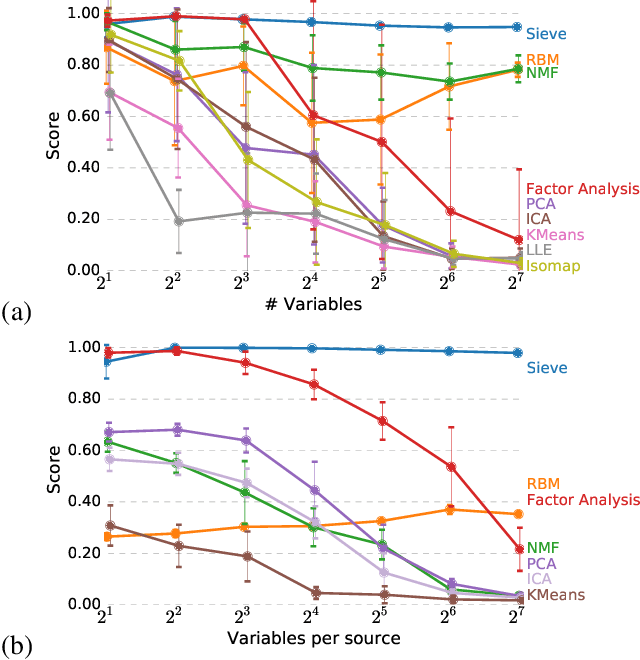
Measuring the relationship between any pair of variables is a rich and active area of research that is central to scientific practice. In contrast, characterizing the common information among any group of variables is typically a theoretical exercise with few practical methods for high-dimensional data. A promising solution would be a multivariate generalization of the famous Wyner common information, but this approach relies on solving an apparently intractable optimization problem. We leverage the recently introduced information sieve decomposition to formulate an incremental version of the common information problem that admits a simple fixed point solution, fast convergence, and complexity that is linear in the number of variables. This scalable approach allows us to demonstrate the usefulness of common information in high-dimensional learning problems. The sieve outperforms standard methods on dimensionality reduction tasks, solves a blind source separation problem that cannot be solved with ICA, and accurately recovers structure in brain imaging data.
Toward Interpretable Topic Discovery via Anchored Correlation Explanation
Jun 22, 2016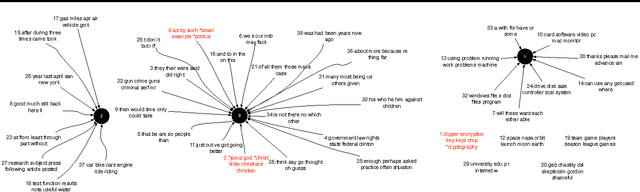


Many predictive tasks, such as diagnosing a patient based on their medical chart, are ultimately defined by the decisions of human experts. Unfortunately, encoding experts' knowledge is often time consuming and expensive. We propose a simple way to use fuzzy and informal knowledge from experts to guide discovery of interpretable latent topics in text. The underlying intuition of our approach is that latent factors should be informative about both correlations in the data and a set of relevance variables specified by an expert. Mathematically, this approach is a combination of the information bottleneck and Total Correlation Explanation (CorEx). We give a preliminary evaluation of Anchored CorEx, showing that it produces more coherent and interpretable topics on two distinct corpora.