 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent detection in Twitter: A keyword volume approach
Jan 03, 2019


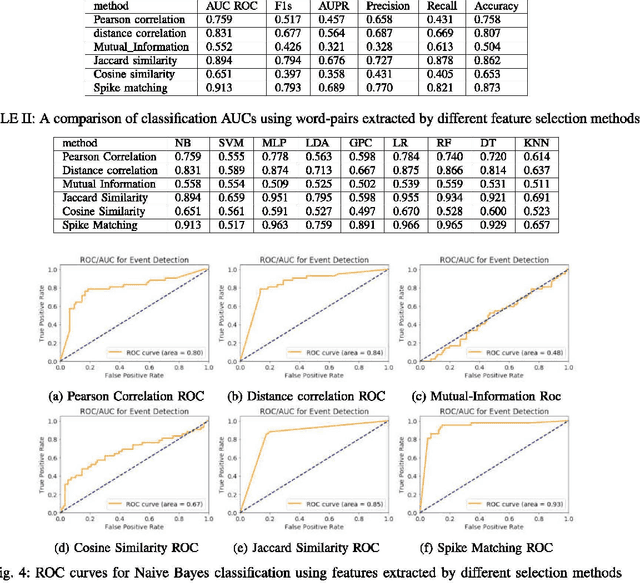
Event detection using social media streams needs a set of informative features with strong signals that need minimal preprocessing and are highly associated with events of interest. Identifying these informative features as keywords from Twitter is challenging, as people use informal language to express their thoughts and feelings. This informality includes acronyms, misspelled words, synonyms, transliteration and ambiguous terms. In this paper, we propose an efficient method to select the keywords frequently used in Twitter that are mostly associated with events of interest such as protests. The volume of these keywords is tracked in real time to identify the events of interest in a binary classification scheme. We use keywords within word-pairs to capture the context. The proposed method is to binarize vectors of daily counts for each word-pair by applying a spike detection temporal filter, then use the Jaccard metric to measure the similarity of the binary vector for each word-pair with the binary vector describing event occurrence. The top n word-pairs are used as features to classify any day to be an event or non-event day. The selected features are tested using multiple classifiers such as Naive Bayes, SVM, Logistic Regression, KNN and decision trees. They all produced AUC ROC scores up to 0.91 and F1 scores up to 0.79. The experiment is performed using the English language in multiple cities such as Melbourne, Sydney and Brisbane as well as the Indonesian language in Jakarta. The two experiments, comprising different languages and locations, yielded similar results.
Enhancing keyword correlation for event detection in social networks using SVD and k-means: Twitter case study
Jul 25, 2018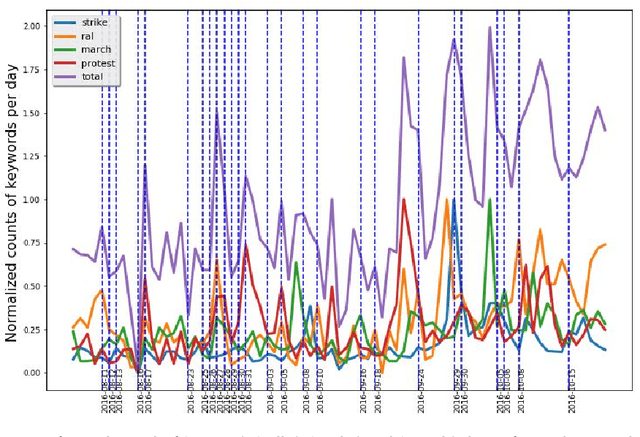
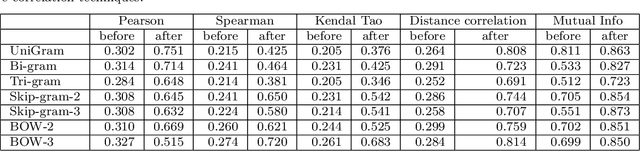
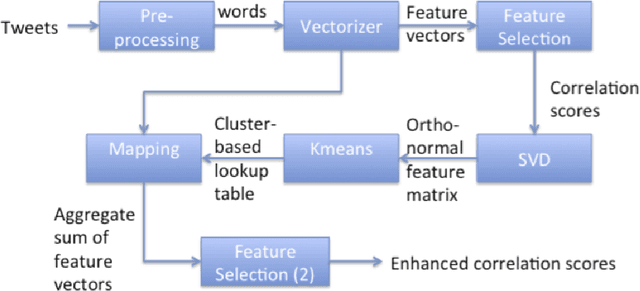
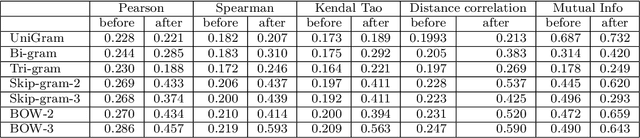
Extracting textual features from tweets is a challenging process due to the noisy nature of the content and the weak signal of most of the words used. In this paper, we propose using singular value decomposition (SVD) with clustering to enhance the signals of the textual features in the tweets to improve the correlation with events. The proposed technique applies SVD to the time series vector for each feature to factorize the matrix of feature/day counts, in order to ensure the independence of the feature vectors. Afterwards, the k-means clustering is applied to build a look-up table that maps members of each cluster to the cluster-centroid. The lookup table is used to map each feature in the original data to the centroid of its cluster, then we calculate the sum of the term frequency vectors of all features in each cluster to the term-frequency-vector of the cluster centroid. To test the technique we calculated the correlations of the cluster centroids with the golden standard record (GSR) vector before and after summing the vectors of the cluster members to the centroid-vector. The proposed method is applied to multiple correlation techniques including the Pearson, Spearman, distance correlation and Kendal Tao. The experiments have also considered the different word forms and lengths of the features including keywords, n-grams, skip-grams and bags-of-words. The correlation results are enhanced significantly as the highest correlation scores have increased from 0.3 to 0.6, and the average correlation scores have increased from 0.3 to 0.4.