 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing keyword correlation for event detection in social networks using SVD and k-means: Twitter case study
Paper and Code
Jul 25, 2018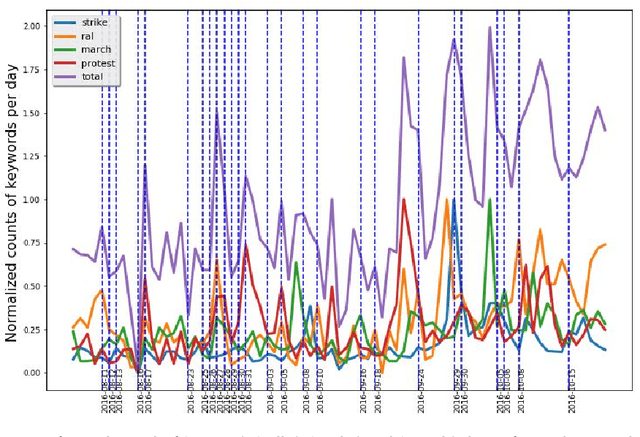
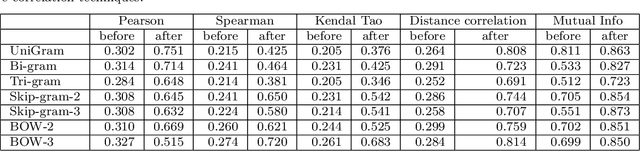
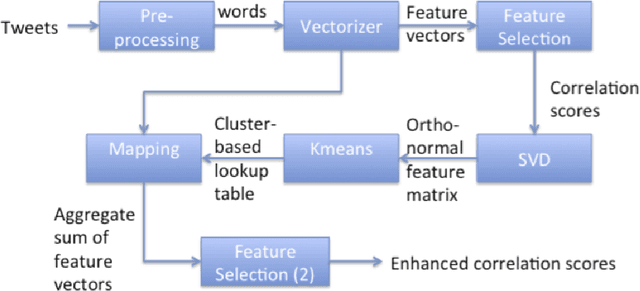
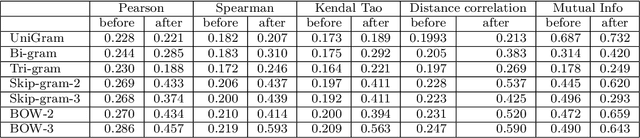
Extracting textual features from tweets is a challenging process due to the noisy nature of the content and the weak signal of most of the words used. In this paper, we propose using singular value decomposition (SVD) with clustering to enhance the signals of the textual features in the tweets to improve the correlation with events. The proposed technique applies SVD to the time series vector for each feature to factorize the matrix of feature/day counts, in order to ensure the independence of the feature vectors. Afterwards, the k-means clustering is applied to build a look-up table that maps members of each cluster to the cluster-centroid. The lookup table is used to map each feature in the original data to the centroid of its cluster, then we calculate the sum of the term frequency vectors of all features in each cluster to the term-frequency-vector of the cluster centroid. To test the technique we calculated the correlations of the cluster centroids with the golden standard record (GSR) vector before and after summing the vectors of the cluster members to the centroid-vector. The proposed method is applied to multiple correlation techniques including the Pearson, Spearman, distance correlation and Kendal Tao. The experiments have also considered the different word forms and lengths of the features including keywords, n-grams, skip-grams and bags-of-words. The correlation results are enhanced significantly as the highest correlation scores have increased from 0.3 to 0.6, and the average correlation scores have increased from 0.3 to 0.4.