 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating BERT-based Pre-training Language Models for Detecting Misinformation
Mar 15, 2022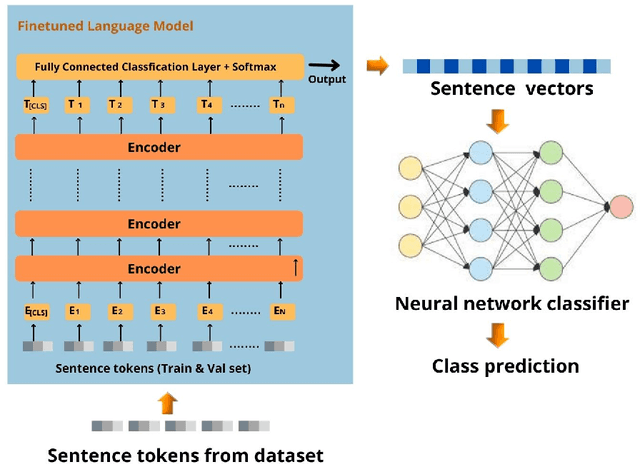
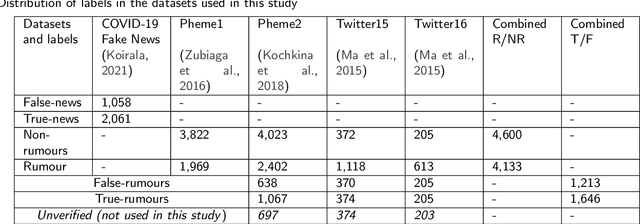


It is challenging to control the quality of online information due to the lack of supervision over all the information posted online. Manual checking is almost impossible given the vast number of posts made on online media and how quickly they spread. Therefore, there is a need for automated rumour detection techniques to limit the adverse effects of spreading misinformation. Previous studies mainly focused on finding and extracting the significant features of text data. However, extracting features is time-consuming and not a highly effective process. This study proposes the BERT- based pre-trained language models to encode text data into vectors and utilise neural network models to classify these vectors to detect misinformation. Furthermore, different language models (LM) ' performance with different trainable parameters was compared. The proposed technique is tested on different short and long text datasets. The result of the proposed technique has been compared with the state-of-the-art techniques on the same datasets. The results show that the proposed technique performs better than the state-of-the-art techniques. We also tested the proposed technique by combining the datasets. The results demonstrated that the large data training and testing size considerably improves the technique's performance.
BERT based classification system for detecting rumours on Twitter
Sep 07, 2021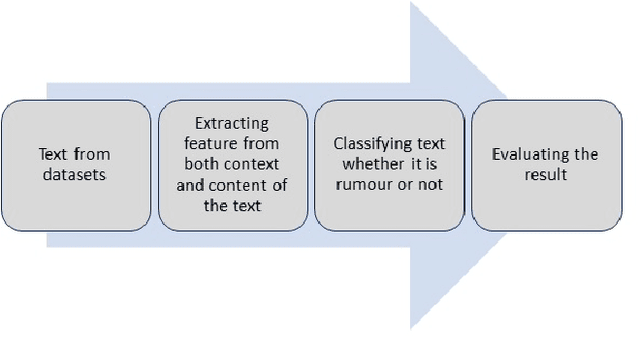
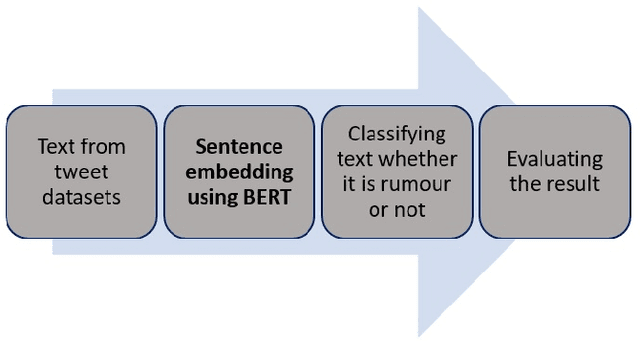
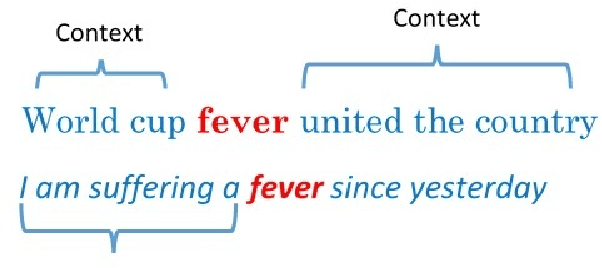
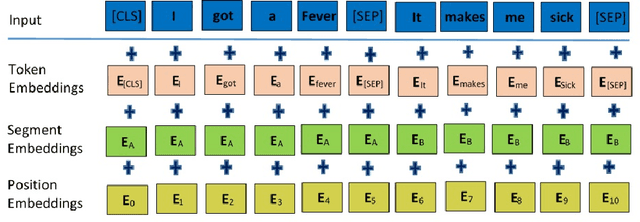
The role of social media in opinion formation has far-reaching implications in all spheres of society. Though social media provide platforms for expressing news and views, it is hard to control the quality of posts due to the sheer volumes of posts on platforms like Twitter and Facebook. Misinformation and rumours have lasting effects on society, as they tend to influence people's opinions and also may motivate people to act irrationally. It is therefore very important to detect and remove rumours from these platforms. The only way to prevent the spread of rumours is through automatic detection and classification of social media posts. Our focus in this paper is the Twitter social medium, as it is relatively easy to collect data from Twitter. The majority of previous studies used supervised learning approaches to classify rumours on Twitter. These approaches rely on feature extraction to obtain both content and context features from the text of tweets to distinguish rumours and non-rumours. Manually extracting features however is time-consuming considering the volume of tweets. We propose a novel approach to deal with this problem by utilising sentence embedding using BERT to identify rumours on Twitter, rather than the usual feature extraction techniques. We use sentence embedding using BERT to represent each tweet's sentences into a vector according to the contextual meaning of the tweet. We classify those vectors into rumours or non-rumours by using various supervised learning techniques. Our BERT based models improved the accuracy by approximately 10% as compared to previous methods.