 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHawkes based Representation Learning for Reasoning over Scale-free Community-structured Temporal Knowledge Graphs
Dec 28, 2024Temporal knowledge graph (TKG) reasoning has become a hot topic due to its great value in many practical tasks. The key to TKG reasoning is modeling the structural information and evolutional patterns of the TKGs. While great efforts have been devoted to TKG reasoning, the structural and evolutional characteristics of real-world networks have not been considered. In the aspect of structure, real-world networks usually exhibit clear community structure and scale-free (long-tailed distribution) properties. In the aspect of evolution, the impact of an event decays with the time elapsing. In this paper, we propose a novel TKG reasoning model called Hawkes process-based Evolutional Representation Learning Network (HERLN), which learns structural information and evolutional patterns of a TKG simultaneously, considering the characteristics of real-world networks: community structure, scale-free and temporal decaying. First, we find communities in the input TKG to make the encoding get more similar intra-community embeddings. Second, we design a Hawkes process-based relational graph convolutional network to cope with the event impact-decaying phenomenon. Third, we design a conditional decoding method to alleviate biases towards frequent entities caused by long-tailed distribution. Experimental results show that HERLN achieves significant improvements over the state-of-the-art models.
Neural Probabilistic Logic Learning for Knowledge Graph Reasoning
Jul 04, 2024



Knowledge graph (KG) reasoning is a task that aims to predict unknown facts based on known factual samples. Reasoning methods can be divided into two categories: rule-based methods and KG-embedding based methods. The former possesses precise reasoning capabilities but finds it challenging to reason efficiently over large-scale knowledge graphs. While gaining the ability to reason over large-scale knowledge graphs, the latter sacrifices reasoning accuracy. This paper aims to design a reasoning framework called Neural Probabilistic Logic Learning(NPLL) that achieves accurate reasoning on knowledge graphs. Our approach introduces a scoring module that effectively enhances the expressive power of embedding networks, striking a balance between model simplicity and reasoning capabilities. We improve the interpretability of the model by incorporating a Markov Logic Network based on variational inference. We empirically evaluate our approach on several benchmark datasets, and the experimental results validate that our method substantially enhances the accuracy and quality of the reasoning results.
Liberating Seen Classes: Boosting Few-Shot and Zero-Shot Text Classification via Anchor Generation and Classification Reframing
May 06, 2024



Few-shot and zero-shot text classification aim to recognize samples from novel classes with limited labeled samples or no labeled samples at all. While prevailing methods have shown promising performance via transferring knowledge from seen classes to unseen classes, they are still limited by (1) Inherent dissimilarities among classes make the transformation of features learned from seen classes to unseen classes both difficult and inefficient. (2) Rare labeled novel samples usually cannot provide enough supervision signals to enable the model to adjust from the source distribution to the target distribution, especially for complicated scenarios. To alleviate the above issues, we propose a simple and effective strategy for few-shot and zero-shot text classification. We aim to liberate the model from the confines of seen classes, thereby enabling it to predict unseen categories without the necessity of training on seen classes. Specifically, for mining more related unseen category knowledge, we utilize a large pre-trained language model to generate pseudo novel samples, and select the most representative ones as category anchors. After that, we convert the multi-class classification task into a binary classification task and use the similarities of query-anchor pairs for prediction to fully leverage the limited supervision signals. Extensive experiments on six widely used public datasets show that our proposed method can outperform other strong baselines significantly in few-shot and zero-shot tasks, even without using any seen class samples.
HQA-Attack: Toward High Quality Black-Box Hard-Label Adversarial Attack on Text
Feb 02, 2024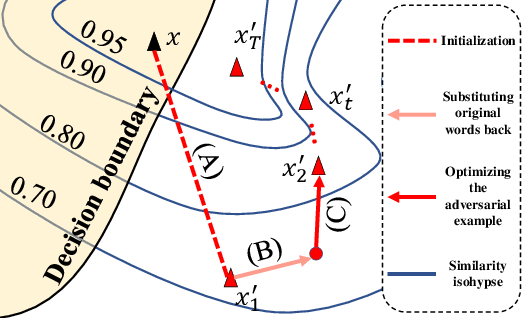
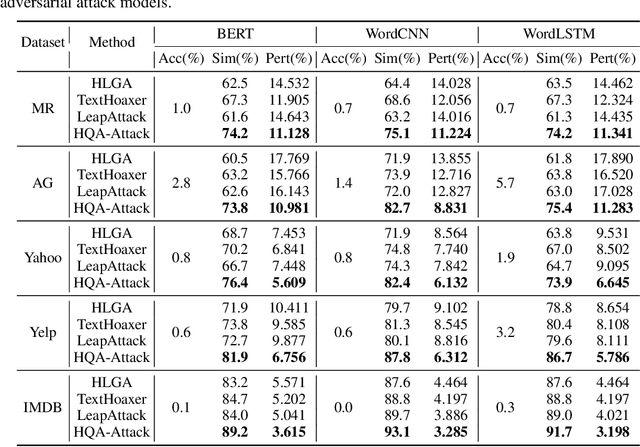
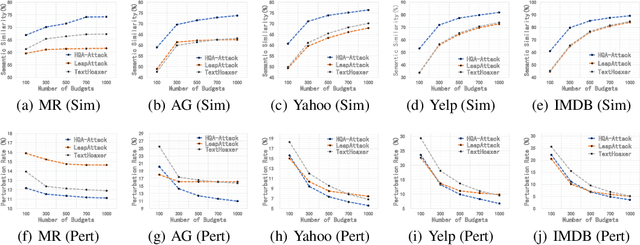
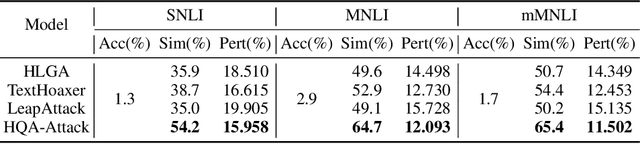
Black-box hard-label adversarial attack on text is a practical and challenging task, as the text data space is inherently discrete and non-differentiable, and only the predicted label is accessible. Research on this problem is still in the embryonic stage and only a few methods are available. Nevertheless, existing methods rely on the complex heuristic algorithm or unreliable gradient estimation strategy, which probably fall into the local optimum and inevitably consume numerous queries, thus are difficult to craft satisfactory adversarial examples with high semantic similarity and low perturbation rate in a limited query budget. To alleviate above issues, we propose a simple yet effective framework to generate high quality textual adversarial examples under the black-box hard-label attack scenarios, named HQA-Attack. Specifically, after initializing an adversarial example randomly, HQA-attack first constantly substitutes original words back as many as possible, thus shrinking the perturbation rate. Then it leverages the synonym set of the remaining changed words to further optimize the adversarial example with the direction which can improve the semantic similarity and satisfy the adversarial condition simultaneously. In addition, during the optimizing procedure, it searches a transition synonym word for each changed word, thus avoiding traversing the whole synonym set and reducing the query number to some extent. Extensive experimental results on five text classification datasets, three natural language inference datasets and two real-world APIs have shown that the proposed HQA-Attack method outperforms other strong baselines significantly.
Boosting Decision-Based Black-Box Adversarial Attack with Gradient Priors
Oct 29, 2023


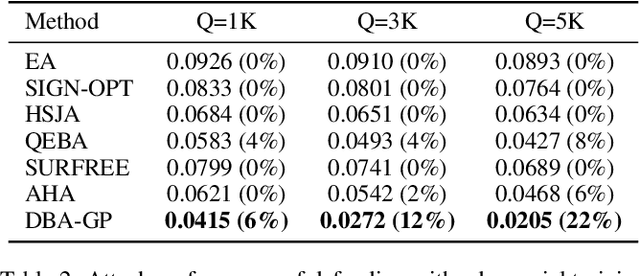
Decision-based methods have shown to be effective in black-box adversarial attacks, as they can obtain satisfactory performance and only require to access the final model prediction. Gradient estimation is a critical step in black-box adversarial attacks, as it will directly affect the query efficiency. Recent works have attempted to utilize gradient priors to facilitate score-based methods to obtain better results. However, these gradient priors still suffer from the edge gradient discrepancy issue and the successive iteration gradient direction issue, thus are difficult to simply extend to decision-based methods. In this paper, we propose a novel Decision-based Black-box Attack framework with Gradient Priors (DBA-GP), which seamlessly integrates the data-dependent gradient prior and time-dependent prior into the gradient estimation procedure. First, by leveraging the joint bilateral filter to deal with each random perturbation, DBA-GP can guarantee that the generated perturbations in edge locations are hardly smoothed, i.e., alleviating the edge gradient discrepancy, thus remaining the characteristics of the original image as much as possible. Second, by utilizing a new gradient updating strategy to automatically adjust the successive iteration gradient direction, DBA-GP can accelerate the convergence speed, thus improving the query efficiency. Extensive experiments have demonstrated that the proposed method outperforms other strong baselines significantly.
Boosting Few-Shot Text Classification via Distribution Estimation
Mar 26, 2023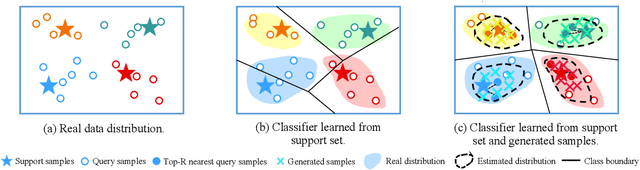
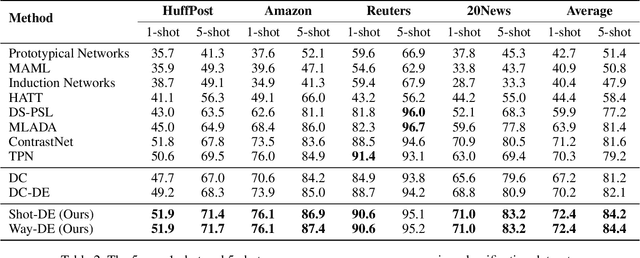

Distribution estimation has been demonstrated as one of the most effective approaches in dealing with few-shot image classification, as the low-level patterns and underlying representations can be easily transferred across different tasks in computer vision domain. However, directly applying this approach to few-shot text classification is challenging, since leveraging the statistics of known classes with sufficient samples to calibrate the distributions of novel classes may cause negative effects due to serious category difference in text domain. To alleviate this issue, we propose two simple yet effective strategies to estimate the distributions of the novel classes by utilizing unlabeled query samples, thus avoiding the potential negative transfer issue. Specifically, we first assume a class or sample follows the Gaussian distribution, and use the original support set and the nearest few query samples to estimate the corresponding mean and covariance. Then, we augment the labeled samples by sampling from the estimated distribution, which can provide sufficient supervision for training the classification model. Extensive experiments on eight few-shot text classification datasets show that the proposed method outperforms state-of-the-art baselines significantly.
Infomaxformer: Maximum Entropy Transformer for Long Time-Series Forecasting Problem
Jan 04, 2023The Transformer architecture yields state-of-the-art results in many tasks such as natural language processing (NLP) and computer vision (CV), since the ability to efficiently capture the precise long-range dependency coupling between input sequences. With this advanced capability, however, the quadratic time complexity and high memory usage prevents the Transformer from dealing with long time-series forecasting problem (LTFP). To address these difficulties: (i) we revisit the learned attention patterns of the vanilla self-attention, redesigned the calculation method of self-attention based the Maximum Entropy Principle. (ii) we propose a new method to sparse the self-attention, which can prevent the loss of more important self-attention scores due to random sampling.(iii) We propose Keys/Values Distilling method motivated that a large amount of feature in the original self-attention map is redundant, which can further reduce the time and spatial complexity and make it possible to input longer time-series. Finally, we propose a method that combines the encoder-decoder architecture with seasonal-trend decomposition, i.e., using the encoder-decoder architecture to capture more specific seasonal parts. A large number of experiments on several large-scale datasets show that our Infomaxformer is obviously superior to the existing methods. We expect this to open up a new solution for Transformer to solve LTFP, and exploring the ability of the Transformer architecture to capture much longer temporal dependencies.
MTSMAE: Masked Autoencoders for Multivariate Time-Series Forecasting
Oct 04, 2022

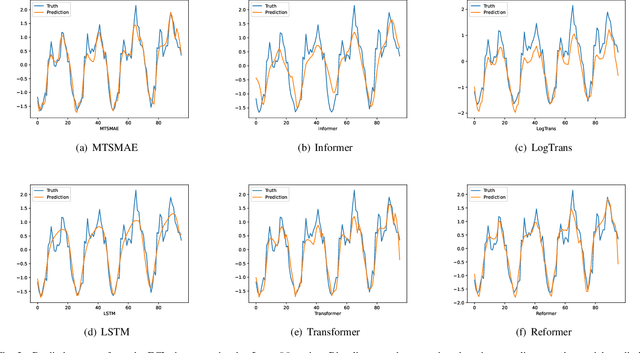
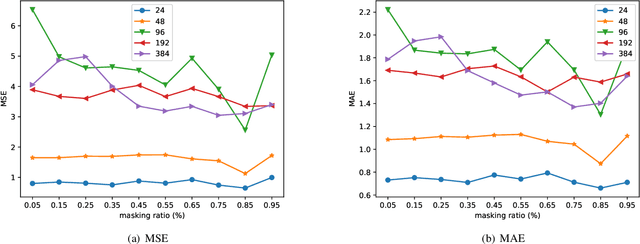
Large-scale self-supervised pre-training Transformer architecture have significantly boosted the performance for various tasks in natural language processing (NLP) and computer vision (CV). However, there is a lack of researches on processing multivariate time-series by pre-trained Transformer, and especially, current study on masking time-series for self-supervised learning is still a gap. Different from language and image processing, the information density of time-series increases the difficulty of research. The challenge goes further with the invalidity of the previous patch embedding and mask methods. In this paper, according to the data characteristics of multivariate time-series, a patch embedding method is proposed, and we present an self-supervised pre-training approach based on Masked Autoencoders (MAE), called MTSMAE, which can improve the performance significantly over supervised learning without pre-training. Evaluating our method on several common multivariate time-series datasets from different fields and with different characteristics, experiment results demonstrate that the performance of our method is significantly better than the best method currently available.
Features Fusion Framework for Multimodal Irregular Time-series Events
Sep 05, 2022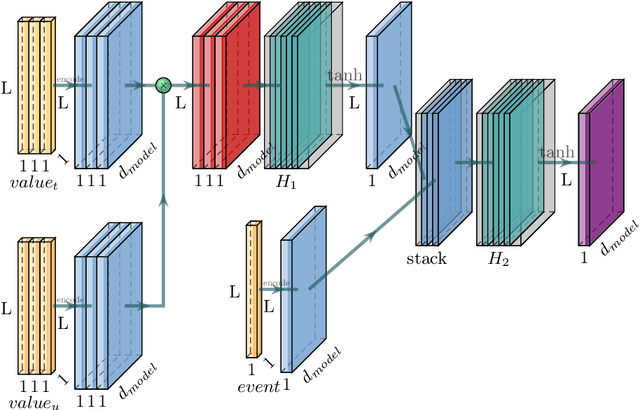
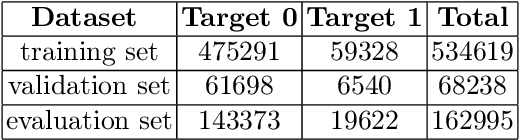

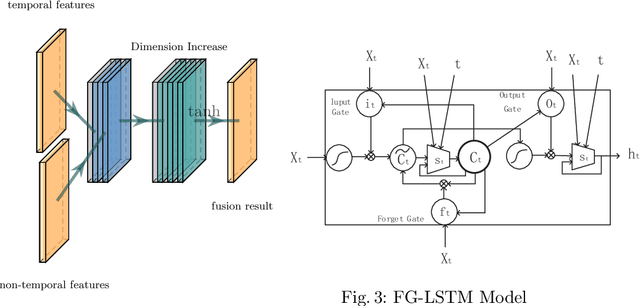
Some data from multiple sources can be modeled as multimodal time-series events which have different sampling frequencies, data compositions, temporal relations and characteristics. Different types of events have complex nonlinear relationships, and the time of each event is irregular. Neither the classical Recurrent Neural Network (RNN) model nor the current state-of-the-art Transformer model can deal with these features well. In this paper, a features fusion framework for multimodal irregular time-series events is proposed based on the Long Short-Term Memory networks (LSTM). Firstly, the complex features are extracted according to the irregular patterns of different events. Secondly, the nonlinear correlation and complex temporal dependencies relationship between complex features are captured and fused into a tensor. Finally, a feature gate are used to control the access frequency of different tensors. Extensive experiments on MIMIC-III dataset demonstrate that the proposed framework significantly outperforms to the existing methods in terms of AUC (the area under Receiver Operating Characteristic curve) and AP (Average Precision).
A Simple Meta-learning Paradigm for Zero-shot Intent Classification with Mixture Attention Mechanism
Jun 05, 2022


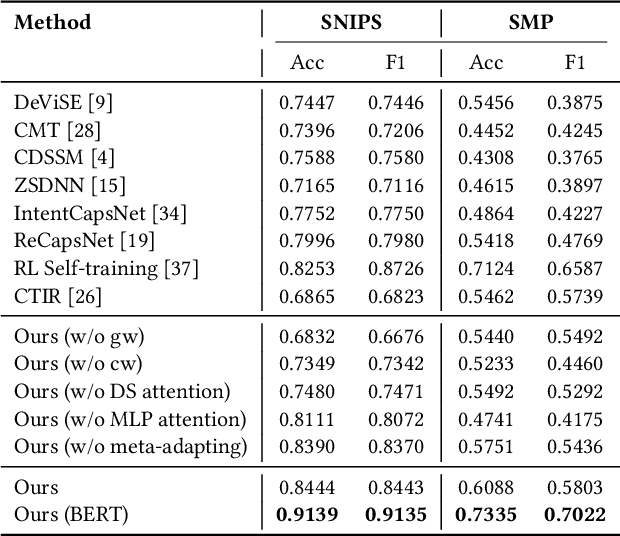
Zero-shot intent classification is a vital and challenging task in dialogue systems, which aims to deal with numerous fast-emerging unacquainted intents without annotated training data. To obtain more satisfactory performance, the crucial points lie in two aspects: extracting better utterance features and strengthening the model generalization ability. In this paper, we propose a simple yet effective meta-learning paradigm for zero-shot intent classification. To learn better semantic representations for utterances, we introduce a new mixture attention mechanism, which encodes the pertinent word occurrence patterns by leveraging the distributional signature attention and multi-layer perceptron attention simultaneously. To strengthen the transfer ability of the model from seen classes to unseen classes, we reformulate zero-shot intent classification with a meta-learning strategy, which trains the model by simulating multiple zero-shot classification tasks on seen categories, and promotes the model generalization ability with a meta-adapting procedure on mimic unseen categories. Extensive experiments on two real-world dialogue datasets in different languages show that our model outperforms other strong baselines on both standard and generalized zero-shot intent classification tasks.