 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDMLP: Patch-based Decomposed MLP for Long-Term Time Series Forecastin
May 22, 2024Recent studies have attempted to refine the Transformer architecture to demonstrate its effectiveness in Long-Term Time Series Forecasting (LTSF) tasks. Despite surpassing many linear forecasting models with ever-improving performance, we remain skeptical of Transformers as a solution for LTSF. We attribute the effectiveness of these models largely to the adopted Patch mechanism, which enhances sequence locality to an extent yet fails to fully address the loss of temporal information inherent to the permutation-invariant self-attention mechanism. Further investigation suggests that simple linear layers augmented with the Patch mechanism may outperform complex Transformer-based LTSF models. Moreover, diverging from models that use channel independence, our research underscores the importance of cross-variable interactions in enhancing the performance of multivariate time series forecasting. The interaction information between variables is highly valuable but has been misapplied in past studies, leading to suboptimal cross-variable models. Based on these insights, we propose a novel and simple Patch-based Decomposed MLP (PDMLP) for LTSF tasks. Specifically, we employ simple moving averages to extract smooth components and noise-containing residuals from time series data, engaging in semantic information interchange through channel mixing and specializing in random noise with channel independence processing. The PDMLP model consistently achieves state-of-the-art results on several real-world datasets. We hope this surprising finding will spur new research directions in the LTSF field and pave the way for more efficient and concise solutions.
Infomaxformer: Maximum Entropy Transformer for Long Time-Series Forecasting Problem
Jan 04, 2023The Transformer architecture yields state-of-the-art results in many tasks such as natural language processing (NLP) and computer vision (CV), since the ability to efficiently capture the precise long-range dependency coupling between input sequences. With this advanced capability, however, the quadratic time complexity and high memory usage prevents the Transformer from dealing with long time-series forecasting problem (LTFP). To address these difficulties: (i) we revisit the learned attention patterns of the vanilla self-attention, redesigned the calculation method of self-attention based the Maximum Entropy Principle. (ii) we propose a new method to sparse the self-attention, which can prevent the loss of more important self-attention scores due to random sampling.(iii) We propose Keys/Values Distilling method motivated that a large amount of feature in the original self-attention map is redundant, which can further reduce the time and spatial complexity and make it possible to input longer time-series. Finally, we propose a method that combines the encoder-decoder architecture with seasonal-trend decomposition, i.e., using the encoder-decoder architecture to capture more specific seasonal parts. A large number of experiments on several large-scale datasets show that our Infomaxformer is obviously superior to the existing methods. We expect this to open up a new solution for Transformer to solve LTFP, and exploring the ability of the Transformer architecture to capture much longer temporal dependencies.
MTSMAE: Masked Autoencoders for Multivariate Time-Series Forecasting
Oct 04, 2022

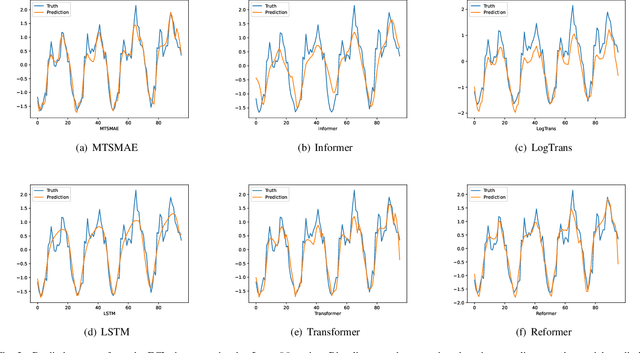
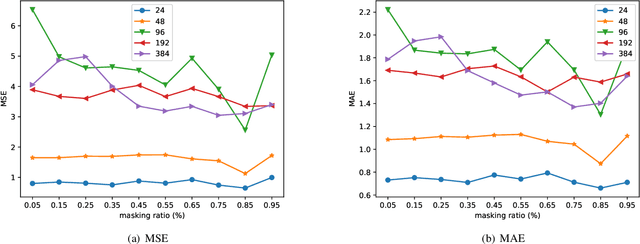
Large-scale self-supervised pre-training Transformer architecture have significantly boosted the performance for various tasks in natural language processing (NLP) and computer vision (CV). However, there is a lack of researches on processing multivariate time-series by pre-trained Transformer, and especially, current study on masking time-series for self-supervised learning is still a gap. Different from language and image processing, the information density of time-series increases the difficulty of research. The challenge goes further with the invalidity of the previous patch embedding and mask methods. In this paper, according to the data characteristics of multivariate time-series, a patch embedding method is proposed, and we present an self-supervised pre-training approach based on Masked Autoencoders (MAE), called MTSMAE, which can improve the performance significantly over supervised learning without pre-training. Evaluating our method on several common multivariate time-series datasets from different fields and with different characteristics, experiment results demonstrate that the performance of our method is significantly better than the best method currently available.
Features Fusion Framework for Multimodal Irregular Time-series Events
Sep 05, 2022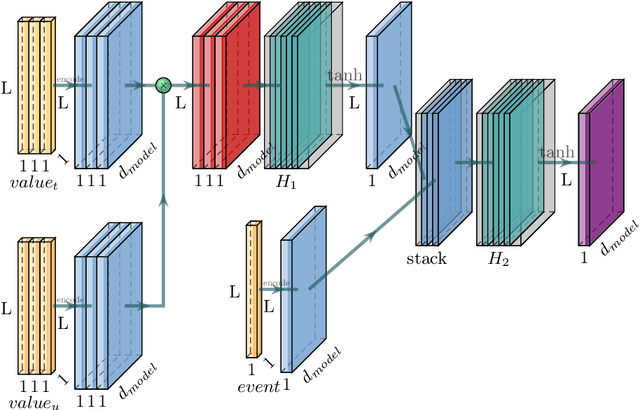
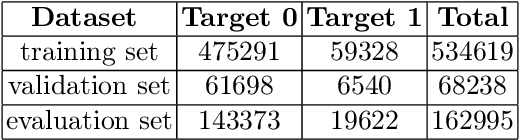

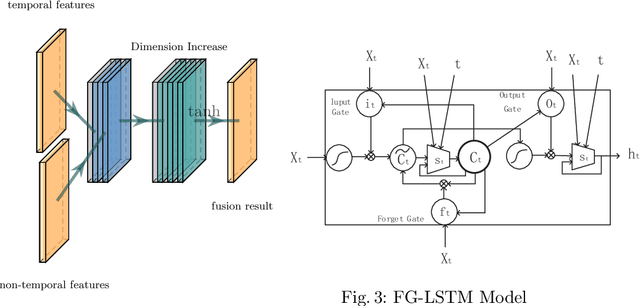
Some data from multiple sources can be modeled as multimodal time-series events which have different sampling frequencies, data compositions, temporal relations and characteristics. Different types of events have complex nonlinear relationships, and the time of each event is irregular. Neither the classical Recurrent Neural Network (RNN) model nor the current state-of-the-art Transformer model can deal with these features well. In this paper, a features fusion framework for multimodal irregular time-series events is proposed based on the Long Short-Term Memory networks (LSTM). Firstly, the complex features are extracted according to the irregular patterns of different events. Secondly, the nonlinear correlation and complex temporal dependencies relationship between complex features are captured and fused into a tensor. Finally, a feature gate are used to control the access frequency of different tensors. Extensive experiments on MIMIC-III dataset demonstrate that the proposed framework significantly outperforms to the existing methods in terms of AUC (the area under Receiver Operating Characteristic curve) and AP (Average Precision).