 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTSMAE: Masked Autoencoders for Multivariate Time-Series Forecasting
Paper and Code
Oct 04, 2022

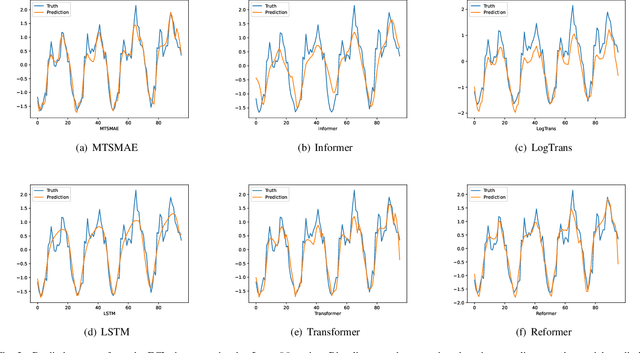
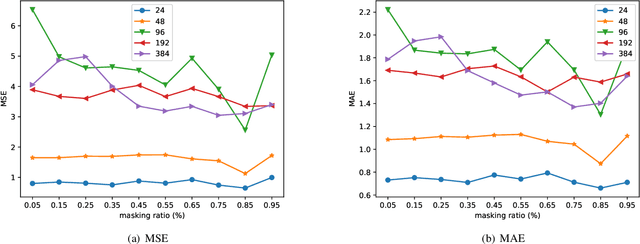
Large-scale self-supervised pre-training Transformer architecture have significantly boosted the performance for various tasks in natural language processing (NLP) and computer vision (CV). However, there is a lack of researches on processing multivariate time-series by pre-trained Transformer, and especially, current study on masking time-series for self-supervised learning is still a gap. Different from language and image processing, the information density of time-series increases the difficulty of research. The challenge goes further with the invalidity of the previous patch embedding and mask methods. In this paper, according to the data characteristics of multivariate time-series, a patch embedding method is proposed, and we present an self-supervised pre-training approach based on Masked Autoencoders (MAE), called MTSMAE, which can improve the performance significantly over supervised learning without pre-training. Evaluating our method on several common multivariate time-series datasets from different fields and with different characteristics, experiment results demonstrate that the performance of our method is significantly better than the best method currently available.