 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiberating Seen Classes: Boosting Few-Shot and Zero-Shot Text Classification via Anchor Generation and Classification Reframing
May 06, 2024



Few-shot and zero-shot text classification aim to recognize samples from novel classes with limited labeled samples or no labeled samples at all. While prevailing methods have shown promising performance via transferring knowledge from seen classes to unseen classes, they are still limited by (1) Inherent dissimilarities among classes make the transformation of features learned from seen classes to unseen classes both difficult and inefficient. (2) Rare labeled novel samples usually cannot provide enough supervision signals to enable the model to adjust from the source distribution to the target distribution, especially for complicated scenarios. To alleviate the above issues, we propose a simple and effective strategy for few-shot and zero-shot text classification. We aim to liberate the model from the confines of seen classes, thereby enabling it to predict unseen categories without the necessity of training on seen classes. Specifically, for mining more related unseen category knowledge, we utilize a large pre-trained language model to generate pseudo novel samples, and select the most representative ones as category anchors. After that, we convert the multi-class classification task into a binary classification task and use the similarities of query-anchor pairs for prediction to fully leverage the limited supervision signals. Extensive experiments on six widely used public datasets show that our proposed method can outperform other strong baselines significantly in few-shot and zero-shot tasks, even without using any seen class samples.
Boosting Few-Shot Text Classification via Distribution Estimation
Mar 26, 2023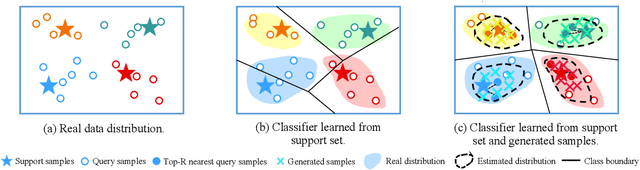
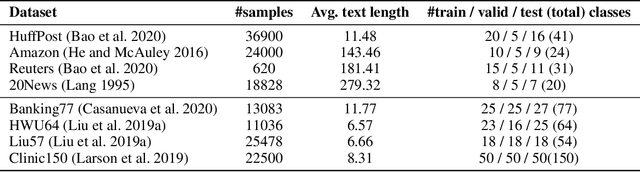
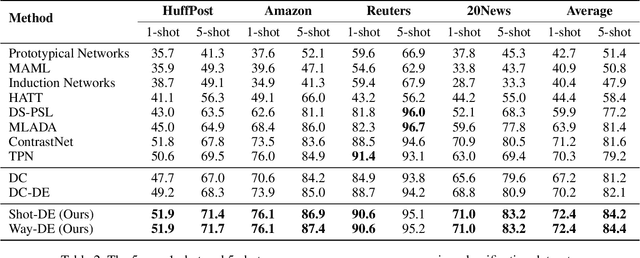

Distribution estimation has been demonstrated as one of the most effective approaches in dealing with few-shot image classification, as the low-level patterns and underlying representations can be easily transferred across different tasks in computer vision domain. However, directly applying this approach to few-shot text classification is challenging, since leveraging the statistics of known classes with sufficient samples to calibrate the distributions of novel classes may cause negative effects due to serious category difference in text domain. To alleviate this issue, we propose two simple yet effective strategies to estimate the distributions of the novel classes by utilizing unlabeled query samples, thus avoiding the potential negative transfer issue. Specifically, we first assume a class or sample follows the Gaussian distribution, and use the original support set and the nearest few query samples to estimate the corresponding mean and covariance. Then, we augment the labeled samples by sampling from the estimated distribution, which can provide sufficient supervision for training the classification model. Extensive experiments on eight few-shot text classification datasets show that the proposed method outperforms state-of-the-art baselines significantly.
A Simple Meta-learning Paradigm for Zero-shot Intent Classification with Mixture Attention Mechanism
Jun 05, 2022


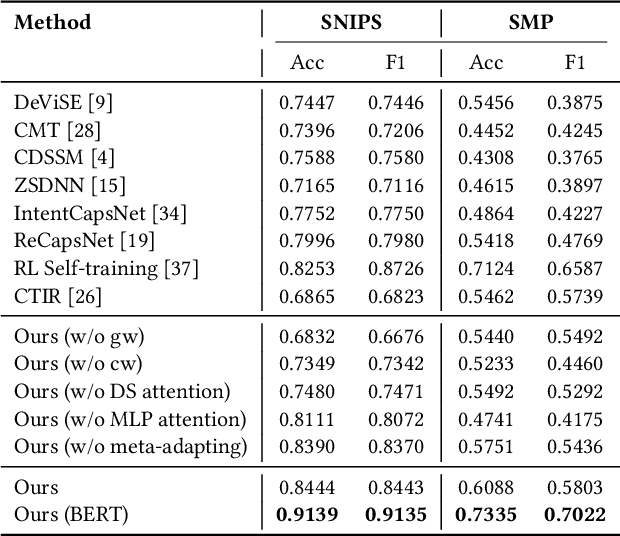
Zero-shot intent classification is a vital and challenging task in dialogue systems, which aims to deal with numerous fast-emerging unacquainted intents without annotated training data. To obtain more satisfactory performance, the crucial points lie in two aspects: extracting better utterance features and strengthening the model generalization ability. In this paper, we propose a simple yet effective meta-learning paradigm for zero-shot intent classification. To learn better semantic representations for utterances, we introduce a new mixture attention mechanism, which encodes the pertinent word occurrence patterns by leveraging the distributional signature attention and multi-layer perceptron attention simultaneously. To strengthen the transfer ability of the model from seen classes to unseen classes, we reformulate zero-shot intent classification with a meta-learning strategy, which trains the model by simulating multiple zero-shot classification tasks on seen categories, and promotes the model generalization ability with a meta-adapting procedure on mimic unseen categories. Extensive experiments on two real-world dialogue datasets in different languages show that our model outperforms other strong baselines on both standard and generalized zero-shot intent classification tasks.
An Explicit-Joint and Supervised-Contrastive Learning Framework for Few-Shot Intent Classification and Slot Filling
Oct 26, 2021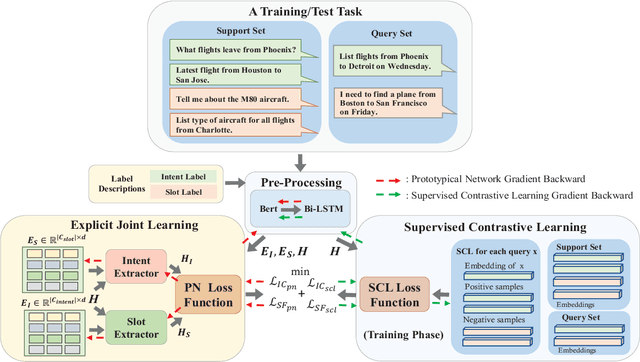


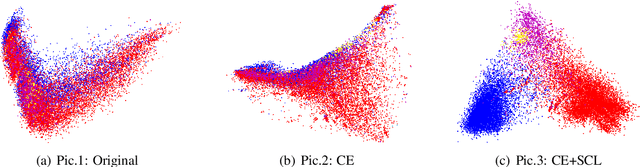
Intent classification (IC) and slot filling (SF) are critical building blocks in task-oriented dialogue systems. These two tasks are closely-related and can flourish each other. Since only a few utterances can be utilized for identifying fast-emerging new intents and slots, data scarcity issue often occurs when implementing IC and SF. However, few IC/SF models perform well when the number of training samples per class is quite small. In this paper, we propose a novel explicit-joint and supervised-contrastive learning framework for few-shot intent classification and slot filling. Its highlights are as follows. (i) The model extracts intent and slot representations via bidirectional interactions, and extends prototypical network to achieve explicit-joint learning, which guarantees that IC and SF tasks can mutually reinforce each other. (ii) The model integrates with supervised contrastive learning, which ensures that samples from same class are pulled together and samples from different classes are pushed apart. In addition, the model follows a not common but practical way to construct the episode, which gets rid of the traditional setting with fixed way and shot, and allows for unbalanced datasets. Extensive experiments on three public datasets show that our model can achieve promising performance.