 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Path Enhanced Neural Architecture Search for Multimodal Fake News Detection
Jan 24, 2025Multimodal fake news detection has become one of the most crucial issues on social media platforms. Although existing methods have achieved advanced performance, two main challenges persist: (1) Under-performed multimodal news information fusion due to model architecture solidification, and (2) weak generalization ability on partial-modality contained fake news. To meet these challenges, we propose a novel and flexible triple path enhanced neural architecture search model MUSE. MUSE includes two dynamic paths for detecting partial-modality contained fake news and a static path for exploiting potential multimodal correlations. Experimental results show that MUSE achieves stable performance improvement over the baselines.
Hawkes based Representation Learning for Reasoning over Scale-free Community-structured Temporal Knowledge Graphs
Dec 28, 2024Temporal knowledge graph (TKG) reasoning has become a hot topic due to its great value in many practical tasks. The key to TKG reasoning is modeling the structural information and evolutional patterns of the TKGs. While great efforts have been devoted to TKG reasoning, the structural and evolutional characteristics of real-world networks have not been considered. In the aspect of structure, real-world networks usually exhibit clear community structure and scale-free (long-tailed distribution) properties. In the aspect of evolution, the impact of an event decays with the time elapsing. In this paper, we propose a novel TKG reasoning model called Hawkes process-based Evolutional Representation Learning Network (HERLN), which learns structural information and evolutional patterns of a TKG simultaneously, considering the characteristics of real-world networks: community structure, scale-free and temporal decaying. First, we find communities in the input TKG to make the encoding get more similar intra-community embeddings. Second, we design a Hawkes process-based relational graph convolutional network to cope with the event impact-decaying phenomenon. Third, we design a conditional decoding method to alleviate biases towards frequent entities caused by long-tailed distribution. Experimental results show that HERLN achieves significant improvements over the state-of-the-art models.
Improve Meta-learning for Few-Shot Text Classification with All You Can Acquire from the Tasks
Oct 14, 2024

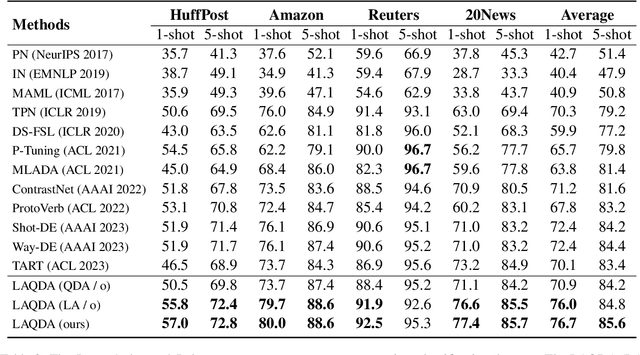
Meta-learning has emerged as a prominent technology for few-shot text classification and has achieved promising performance. However, existing methods often encounter difficulties in drawing accurate class prototypes from support set samples, primarily due to probable large intra-class differences and small inter-class differences within the task. Recent approaches attempt to incorporate external knowledge or pre-trained language models to augment data, but this requires additional resources and thus does not suit many few-shot scenarios. In this paper, we propose a novel solution to address this issue by adequately leveraging the information within the task itself. Specifically, we utilize label information to construct a task-adaptive metric space, thereby adaptively reducing the intra-class differences and magnifying the inter-class differences. We further employ the optimal transport technique to estimate class prototypes with query set samples together, mitigating the problem of inaccurate and ambiguous support set samples caused by large intra-class differences. We conduct extensive experiments on eight benchmark datasets, and our approach shows obvious advantages over state-of-the-art models across all the tasks on all the datasets. For reproducibility, all the datasets and codes are available at https://github.com/YvoGao/LAQDA.
Hate Speech Detection via Dual Contrastive Learning
Jul 10, 2023The fast spread of hate speech on social media impacts the Internet environment and our society by increasing prejudice and hurting people. Detecting hate speech has aroused broad attention in the field of natural language processing. Although hate speech detection has been addressed in recent work, this task still faces two inherent unsolved challenges. The first challenge lies in the complex semantic information conveyed in hate speech, particularly the interference of insulting words in hate speech detection. The second challenge is the imbalanced distribution of hate speech and non-hate speech, which may significantly deteriorate the performance of models. To tackle these challenges, we propose a novel dual contrastive learning (DCL) framework for hate speech detection. Our framework jointly optimizes the self-supervised and the supervised contrastive learning loss for capturing span-level information beyond the token-level emotional semantics used in existing models, particularly detecting speech containing abusive and insulting words. Moreover, we integrate the focal loss into the dual contrastive learning framework to alleviate the problem of data imbalance. We conduct experiments on two publicly available English datasets, and experimental results show that the proposed model outperforms the state-of-the-art models and precisely detects hate speeches.
Spectral Perturbation Meets Incomplete Multi-view Data
May 31, 2019


Beyond existing multi-view clustering, this paper studies a more realistic clustering scenario, referred to as incomplete multi-view clustering, where a number of data instances are missing in certain views. To tackle this problem, we explore spectral perturbation theory. In this work, we show a strong link between perturbation risk bounds and incomplete multi-view clustering. That is, as the similarity matrix fed into spectral clustering is a quantity bounded in magnitude O(1), we transfer the missing problem from data to similarity and tailor a matrix completion method for incomplete similarity matrix. Moreover, we show that the minimization of perturbation risk bounds among different views maximizes the final fusion result across all views. This provides a solid fusion criteria for multi-view data. We motivate and propose a Perturbation-oriented Incomplete multi-view Clustering (PIC) method. Experimental results demonstrate the effectiveness of the proposed method.