 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Object Insertion in Gaussian Splatting with a Multi-View Diffusion Model
Sep 25, 2024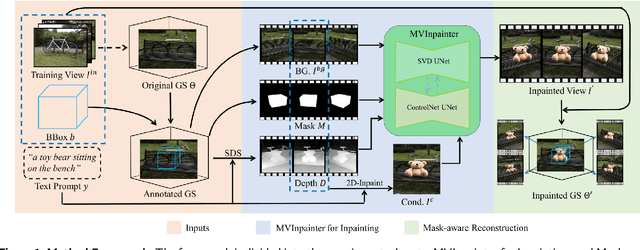
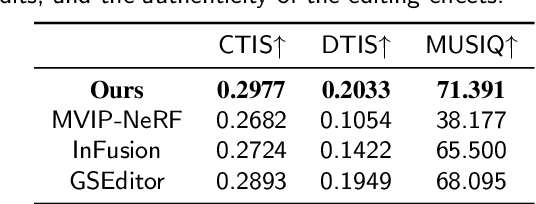


Generating and inserting new objects into 3D content is a compelling approach for achieving versatile scene recreation. Existing methods, which rely on SDS optimization or single-view inpainting, often struggle to produce high-quality results. To address this, we propose a novel method for object insertion in 3D content represented by Gaussian Splatting. Our approach introduces a multi-view diffusion model, dubbed MVInpainter, which is built upon a pre-trained stable video diffusion model to facilitate view-consistent object inpainting. Within MVInpainter, we incorporate a ControlNet-based conditional injection module to enable controlled and more predictable multi-view generation. After generating the multi-view inpainted results, we further propose a mask-aware 3D reconstruction technique to refine Gaussian Splatting reconstruction from these sparse inpainted views. By leveraging these fabricate techniques, our approach yields diverse results, ensures view-consistent and harmonious insertions, and produces better object quality. Extensive experiments demonstrate that our approach outperforms existing methods.
Chat2Layout: Interactive 3D Furniture Layout with a Multimodal LLM
Jul 31, 2024Automatic furniture layout is long desired for convenient interior design. Leveraging the remarkable visual reasoning capabilities of multimodal large language models (MLLMs), recent methods address layout generation in a static manner, lacking the feedback-driven refinement essential for interactive user engagement. We introduce Chat2Layout, a novel interactive furniture layout generation system that extends the functionality of MLLMs into the realm of interactive layout design. To achieve this, we establish a unified vision-question paradigm for in-context learning, enabling seamless communication with MLLMs to steer their behavior without altering model weights. Within this framework, we present a novel training-free visual prompting mechanism. This involves a visual-text prompting technique that assist MLLMs in reasoning about plausible layout plans, followed by an Offline-to-Online search (O2O-Search) method, which automatically identifies the minimal set of informative references to provide exemplars for visual-text prompting. By employing an agent system with MLLMs as the core controller, we enable bidirectional interaction. The agent not only comprehends the 3D environment and user requirements through linguistic and visual perception but also plans tasks and reasons about actions to generate and arrange furniture within the virtual space. Furthermore, the agent iteratively updates based on visual feedback from execution results. Experimental results demonstrate that our approach facilitates language-interactive generation and arrangement for diverse and complex 3D furniture.
VQ-NeRF: Neural Reflectance Decomposition and Editing with Vector Quantization
Nov 05, 2023



We propose VQ-NeRF, a two-branch neural network model that incorporates Vector Quantization (VQ) to decompose and edit reflectance fields in 3D scenes. Conventional neural reflectance fields use only continuous representations to model 3D scenes, despite the fact that objects are typically composed of discrete materials in reality. This lack of discretization can result in noisy material decomposition and complicated material editing. To address these limitations, our model consists of a continuous branch and a discrete branch. The continuous branch follows the conventional pipeline to predict decomposed materials, while the discrete branch uses the VQ mechanism to quantize continuous materials into individual ones. By discretizing the materials, our model can reduce noise in the decomposition process and generate a segmentation map of discrete materials. Specific materials can be easily selected for further editing by clicking on the corresponding area of the segmentation outcomes. Additionally, we propose a dropout-based VQ codeword ranking strategy to predict the number of materials in a scene, which reduces redundancy in the material segmentation process. To improve usability, we also develop an interactive interface to further assist material editing. We evaluate our model on both computer-generated and real-world scenes, demonstrating its superior performance. To the best of our knowledge, our model is the first to enable discrete material editing in 3D scenes.
A spatial-temporal short-term traffic flow prediction model based on dynamical-learning graph convolution mechanism
May 10, 2022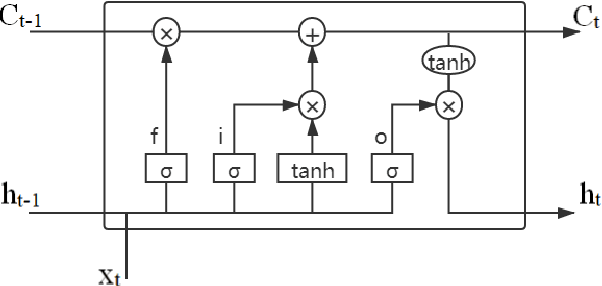



Short-term traffic flow prediction is a vital branch of the Intelligent Traffic System (ITS) and plays an important role in traffic management. Graph convolution network (GCN) is widely used in traffic prediction models to better deal with the graphical structure data of road networks. However, the influence weights among different road sections are usually distinct in real life, and hard to be manually analyzed. Traditional GCN mechanism, relying on manually-set adjacency matrix, is unable to dynamically learn such spatial pattern during the training. To deal with this drawback, this paper proposes a novel location graph convolutional network (Location-GCN). Location-GCN solves this problem by adding a new learnable matrix into the GCN mechanism, using the absolute value of this matrix to represent the distinct influence levels among different nodes. Then, long short-term memory (LSTM) is employed in the proposed traffic prediction model. Moreover, Trigonometric function encoding is used in this study to enable the short-term input sequence to convey the long-term periodical information. Ultimately, the proposed model is compared with the baseline models and evaluated on two real word traffic flow datasets. The results show our model is more accurate and robust on both datasets than other representative traffic prediction models.